
Extracting specific text or structured information from scanned documents or images used to be an incredibly difficult challenge. With the advent of models like Claude, however, it is easier than ever to retrieve data such as the contents of tables from a document.
In this guide, we are going to build a Workflow that:
- Classifies whether a document contains a table.
- If the document contains a table, sends the document to Claude for OCR and table data extraction.
In this guide, we’ll retrieve data from the following example image from an academic paper:

The Workflow will only call Claude if the image contains a table; otherwise, Claude is not run. This means you don't have to pay for a Claude API call if an image doesn't contain a table.
You can try the Workflow with your own Claude key below, or fork it into your Workspace to test and customise the Workflow:
Without further ado, let’s get started!
Prerequisites
To follow this guide, you will need:
- A free Roboflow account;
- An Claude account with API access, and;
- Your Claude API key.
Refer to the Claude documentation to learn how to retrieve your Claude API key.
Step #1: Create a Workflow
Roboflow Workflows is a web-based application builder for computer vision projects.
With Workflows, you can build complex, multi-stage applications that accept images or videos as an input. You can then run your application in the Roboflow Cloud, on a dedicated server managed by Roboflow, or on your own hardware.
Open your Roboflow dashboard and click on the Workflows tab in the left sidebar. Then, click “Create Workflow”. You will be taken to a page with an empty Workflow that looks like this:

Step #2: Add a Table Detection Block
One common workflow when building AI tools is to create "routing" logic that customises your prompt depending on the input.
For this guide, we are going to build routing logic that ensures we only ask Claude to extract data from a table if an image contains a table.
This will prevent us from incurring the cost of calling a cloud API to extract data on documents that do not contain tables.
We are going to use a pre-trained model that can detect whether or not an image contains a table.
Add a new Object Detection Model to your Workflow:
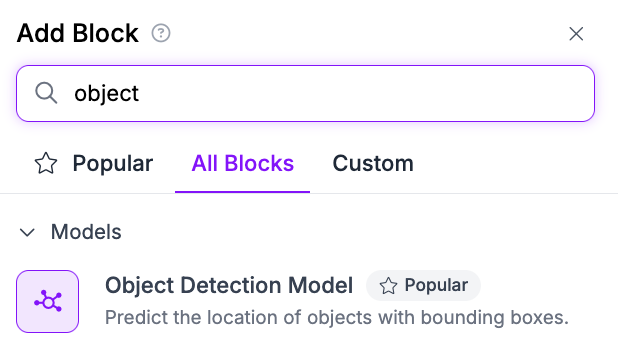
Then, set the model ID to page-object-detection/5:
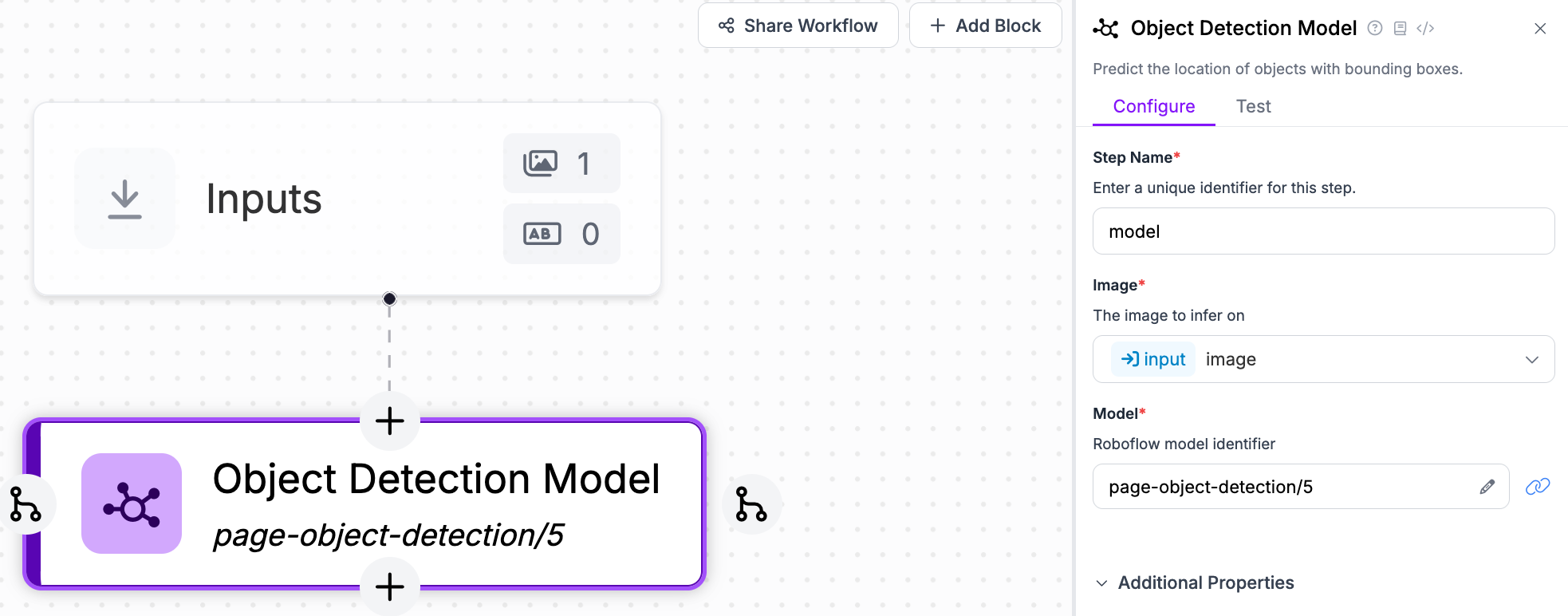
We need to configure what classes to use. Set the value of the Class Filter to 1. This is the name of the class that identifies tables in the model. (Note: Most models would use a class name like "table", but this model was trained with numbers as class names instead.)

Next, add a Property Definition block and add the "Count Items" operation:

This will define a variable we can use to build logic depending on how many tables are in the image. Count Items will count all objects that match the class filters we defined in the last step.
Step #3: Create and Configure a Claude Block
Click “Add Block”, then choose Claude:

A Claude block will be added to your Workflow and a configuration tab will open from which you can configure the block.
Choose the Open Prompt prompting strategy. This will allow you to specify a custom prompt. Then, set the prompt you want. For this guide, we’ll use the prompt “Extract the contents of the table and return as a CSV.”. This will allow us to validate that Claude can successfully extract our table and turn it into a structured format with which we can work.

You will then need to set your Claude API key.
You can configure what model to use in the Model Version dropdown:

For this example, we’ll use Claude 3.5 Sonnet, Anthropic’s latest multimodal model.
Step #4: Add Condition
Now that we have set up our table detection model and Claude, we can use a Continue If block to trigger
Next, add a Continue If block between the Property Definition and Claude blocks:
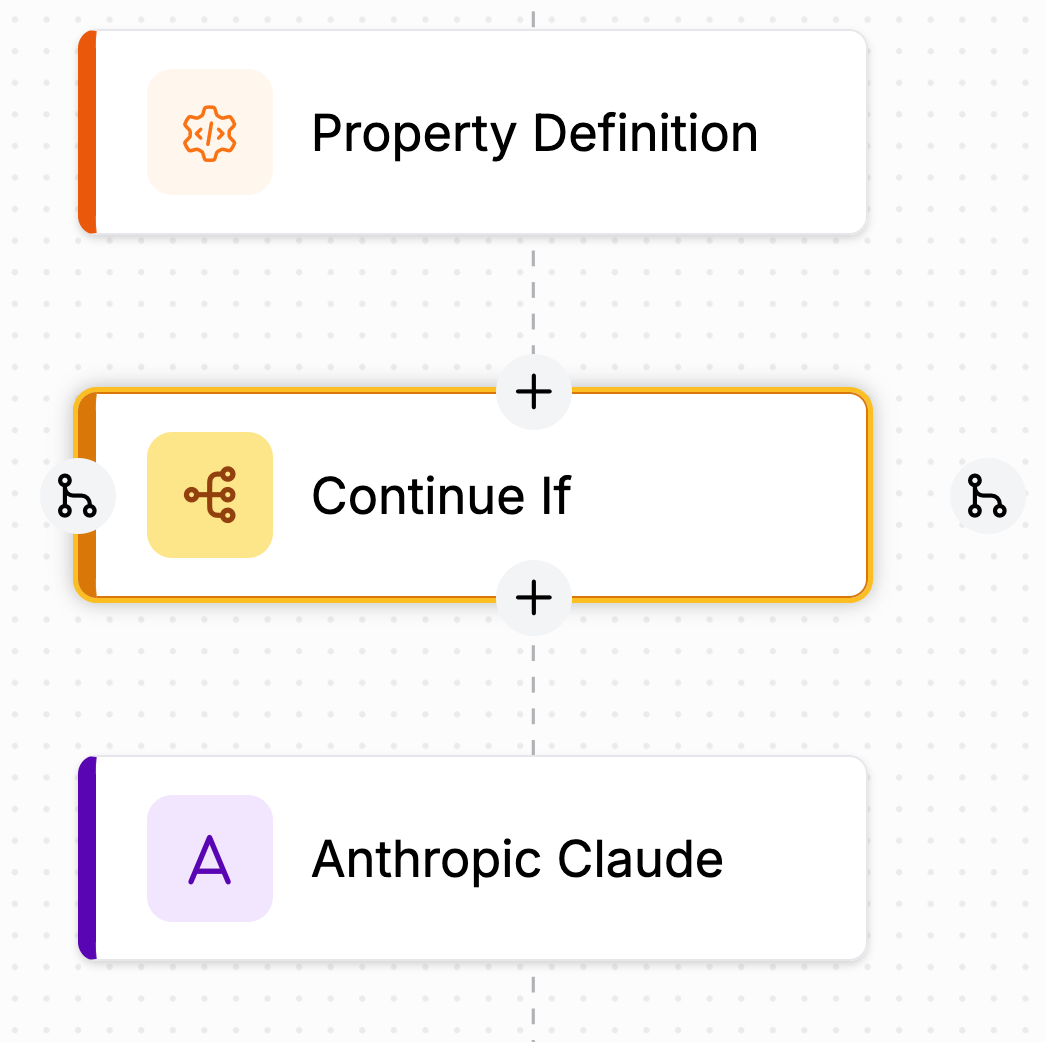
This block will let us trigger Claude only if a condition is met. For this example, we willi trigger Claude is there is at least one table in our input image.
Click on the condition_statement edit button:

A window will pop up in which you can set a condition:
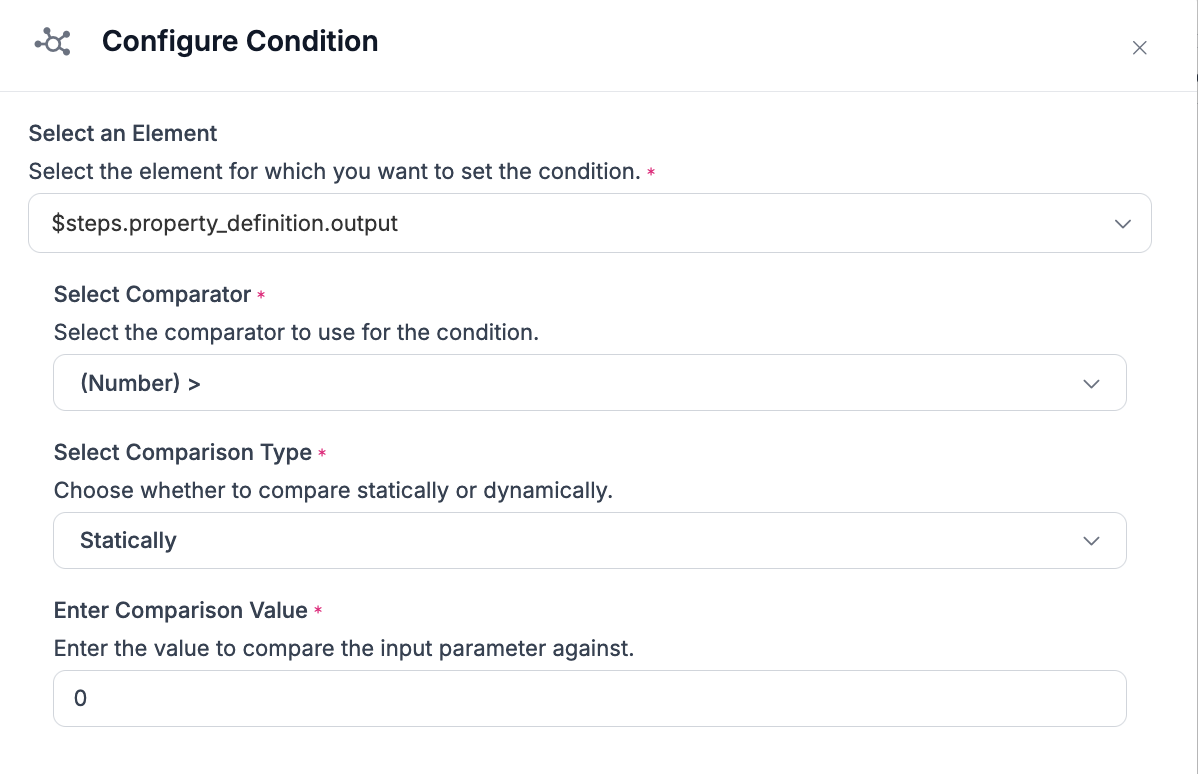
Set the condition to use the output from your property definition. Set the Comparator to greater than (>) and the Comparison Value to 0.
This means that the Countine If will allow any blocks following it (in this case, Claude) only if our object count property is greater than 0. In other words, our input image must contain a table for Claude to trigger.
Step #5: Test Application
With our block ready, we can now test our application. Click “Save” in the top right corner of the Workflows interface. Then, click “Test Workflow”. A tab will appear from which you can test your Workflow with any example image or with your webcam.
Let’s use the following image of a table from an academic paper:
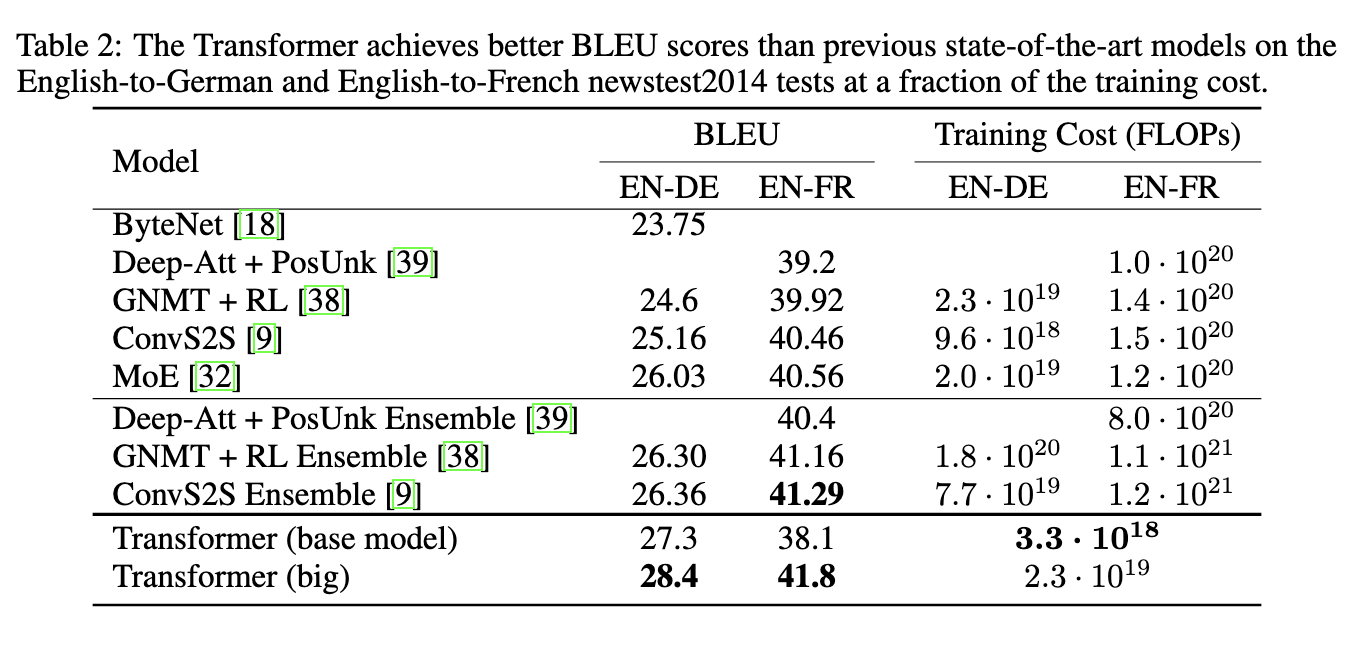
Drag the image into the Input section in the testing interface:
Your Workflow will run and call the OpenAI API. A result will then be returned as a JSON payload. The plain-text value from the OpenAI API will be in a key called “output”.
Here is the result from our Workflow:
[
{
"model_predictions": {
"image": {
"width": 1278,
"height": 596
},
"predictions": [
{
"width": 1126,
"height": 551,
"x": 669,
"y": 290.5,
"confidence": 0.5323795080184937,
"class_id": 1,
"class": "1",
"detection_id": "6ad07d34-ed98-4515-85cc-6f2721bf2eaa",
"parent_id": "image"
}
]
},
"property_definition": 1,
"anthropic_claude": {
"output": "Here's the table converted to markdown format:\n\n| Model | BLEU | | Training Cost (FLOPs) | |\n|---|---|---|---|---|\n| | EN-DE | EN-FR | EN-DE | EN-FR |\n| ByteNet [18] | 23.75 | | | |\n| Deep-Att + PosUnk [39] | | 39.2 | | 1.0 · 10²⁰ |\n| GNMT + RL [38] | 24.6 | 39.92 | 2.3 · 10¹⁹ | 1.4 · 10²⁰ |\n| ConvS2S [9] | 25.16 | 40.46 | 9.6 · 10¹⁸ | 1.5 · 10²⁰ |\n| MoE [32] | 26.03 | 40.56 | 2.0 · 10¹⁹ | 1.2 · 10²⁰ |\n| Deep-Att + PosUnk Ensemble [39] | | 40.4 | | 8.0 · 10²⁰ |\n| GNMT + RL Ensemble [38] | 26.30 | 41.16 | 1.8 · 10²⁰ | 1.1 · 10²¹ |\n| ConvS2S Ensemble [9] | 26.36 | 41.29 | 7.7 · 10¹⁹ | 1.2 · 10²¹ |\n| Transformer (base model) | 27.3 | 38.1 | **3.3 · 10¹",
"classes": null
}
}
]Our Workflow returns:
- The position of the table in the image, from our object detection model.
- The contents of the table, from Claude.
When rendered in a markdown processing application, the result is:
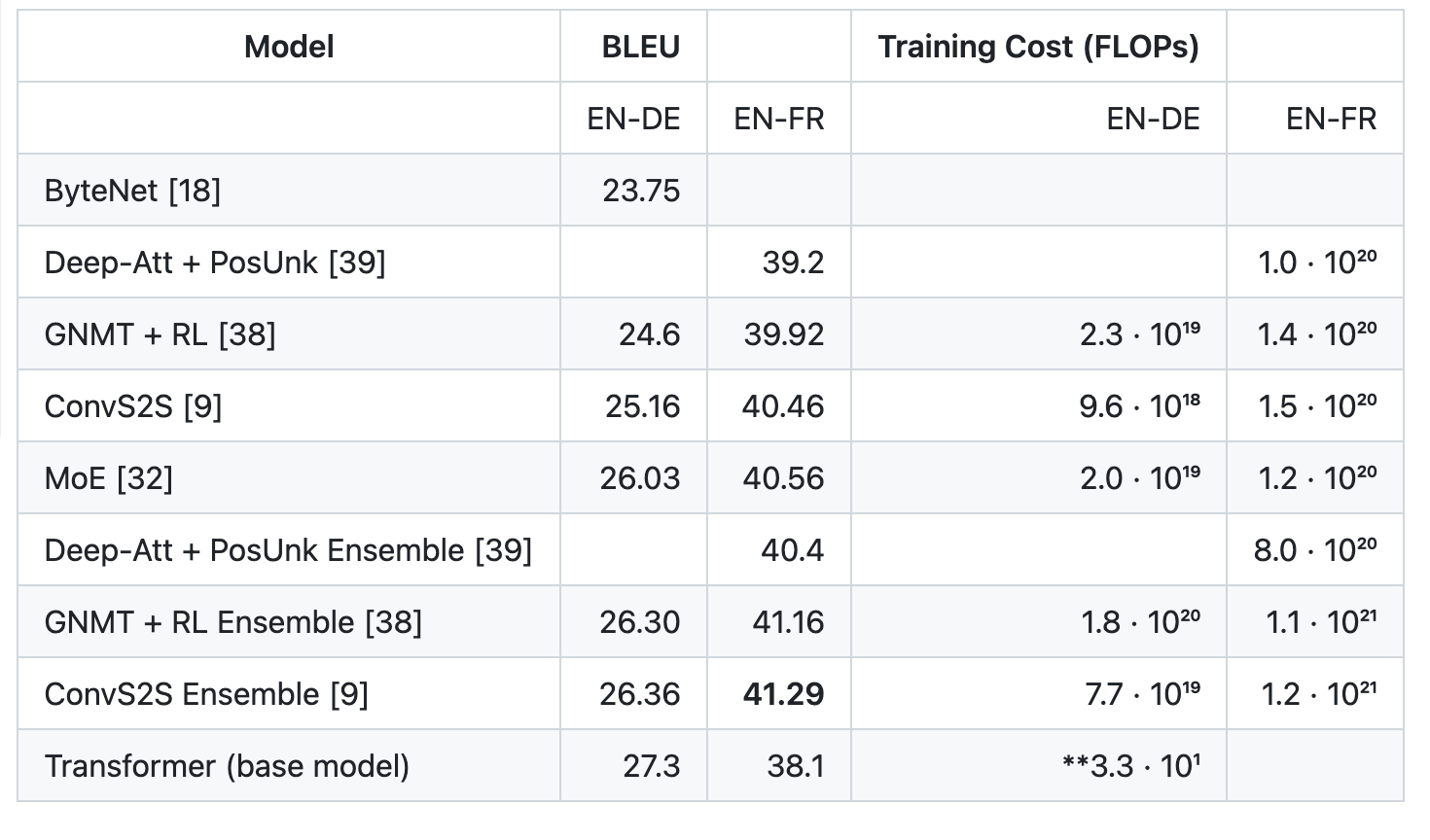
Claude 3.5 Sonnet extracted data from the table and returned it in a plain text representation that can be parsed and further evaluated.
Of note, the model did miss the last row in the table. This could be addressed by experimenting with different prompts.
Let's try on another input image:

Our Workflow returns:
[
{
"model_predictions": {
"image": {
"width": null,
"height": null
},
"predictions": []
},
"property_definition": 0,
"anthropic_claude": {
"output": null,
"classes": null
}
}
]Because no table was found, the Claude block returns null.
Conclusion
Using Roboflow Workflows, you can build complex, multi-stage applications that use state-of-the-art computer vision techniques and models.
In this guide, we built a starter application that uses Anthropic’s Claude model to read the data in tables. This text is then returned in a JSON payload.
You could expand the Workflow to, for example, accept an image, classify whether it is a table or a chart, and route the image to different models depending on the content type. You could also send a Slack notification if a table contains a certain value.
To learn more about building with Roboflow Workflows, check out the Workflows launch guide.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Jan 30, 2025). How to Extract Data from Tables with AI. Roboflow Blog: https://blog.roboflow.com/how-to-extract-data-from-tables-with-ai/