
We are excited to announce that you can now use Roboflow Annotate to label and review data for multimodal vision models. You can then export this data into several popular formats, including the format required by GPT-4o, for use in fine-tuning a large multimodal model.
Fine-tuning multimodal models can help you improve model accuracy, especially on specific domains with which the base model may struggle. To fine-tune multimodal models, having a high quality dataset is essential for helping your model to derive patterns from your annotations.
In this guide, we will walk through how to use the multimodal dataset functionalities in Roboflow.
Without further ado, let’s get started!
How to Create a Multimodal Dataset
Let's walk through how to create a multimodal dataset in Roboflow. The dataset could then be exported for fine-tuning with GPT-4o, Florence-2, and other multimodal models supported by Roboflow.
Step #1: Create a Project
To get started, create a free Roboflow account. From your Roboflow dashboard, click “Create New Project” to create a new project.
A page will appear from which you can create a project:
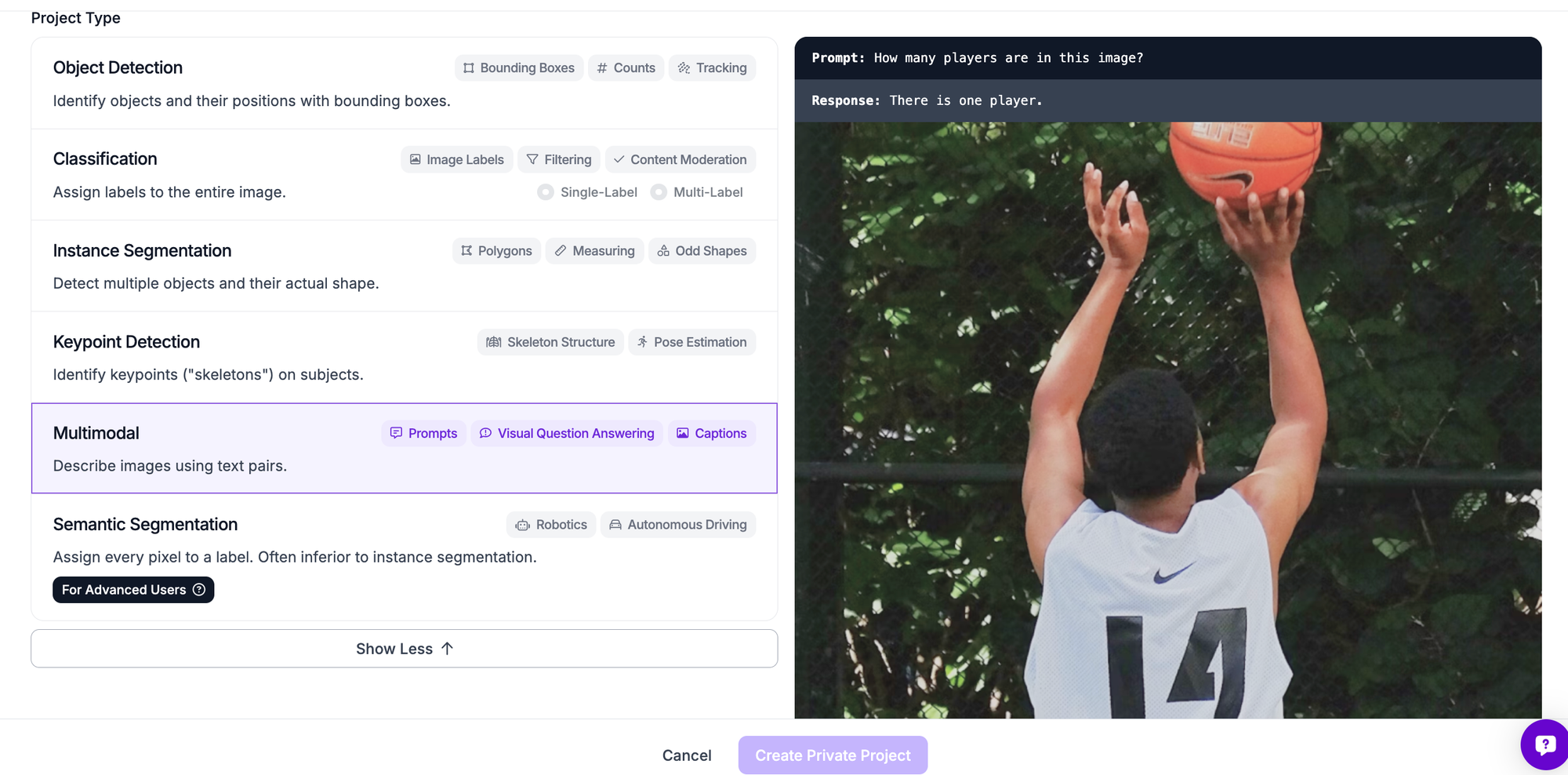
Set a name for your project. When asked to select a project type, choose “Multimodal”. This refers to the image-text pairs commonly used in training multimodal models.
Then, click “Create Project”.
Step #2: Configure Dataset Prefixes
Next, you need to set up “prefixes”. Prefixes are used to annotate your images.
A prefix can either be:
- An identifier like
<PREFIX>, that is used to prompt a VLM like Florence-2, or; - A question like "What is in this image?", ideal for use with general VQA models like GPT-4o.
For Florence-2 fine-tuning, for example, the prefix chosen will correspond to the prefix prompt you give to the model. For Florence-2, prefixes should be in the format <PREFIX>, like <TOTAL>.
For GPT-4o, your prefix may be: "What is the total in this receipt?"
For this guide, we are going to create a project with a single prefix: <TOTAL>
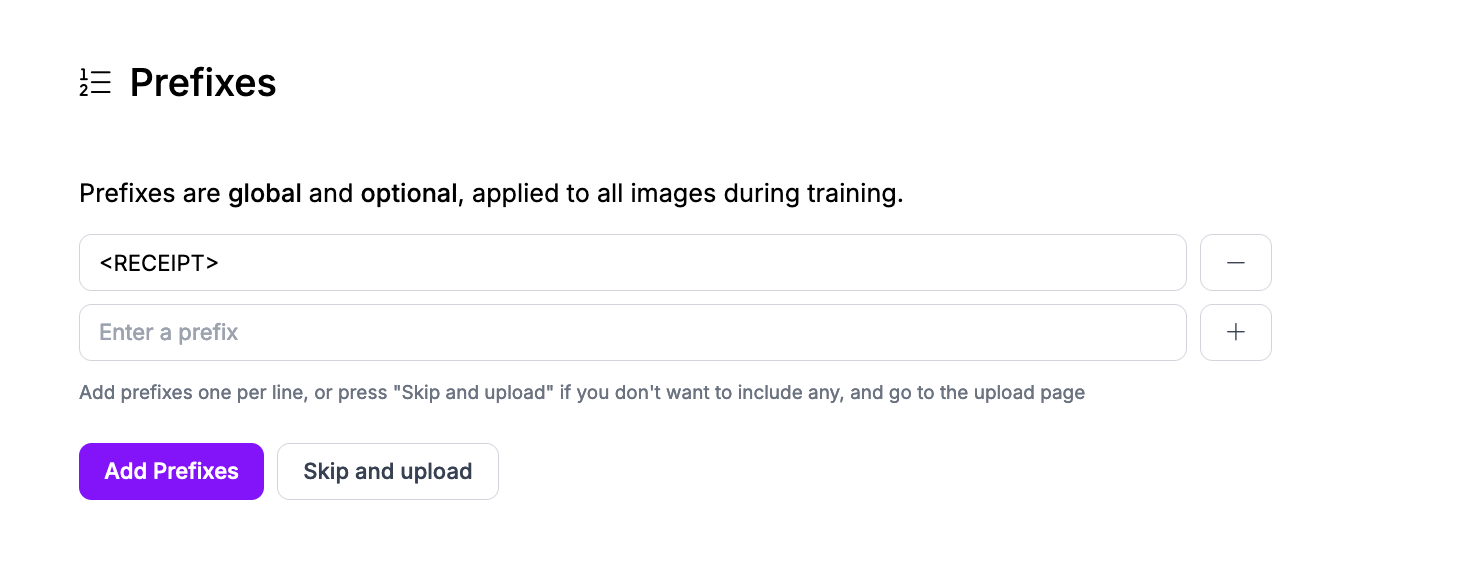
We could add multiple prefixes for different features in the receipt that we want to identify, like total, subtotal, and tax. For this guide, we'll stick with one prefix.
Then, click “Save”.
Step #3: Upload Multimodal Data
You can now upload images to label or review in Roboflow.
Click "Upload Data" in the left sidebar of your project.
If you have data in any of the compatible multimodal formats (i.e. GPT-4o JSONL), you can upload both the images and the annotations to Roboflow. The annotations will be automatically recognized. Otherwise, you can upload raw images to label in Roboflow.
Drag and drop your images to upload them into Roboflow:
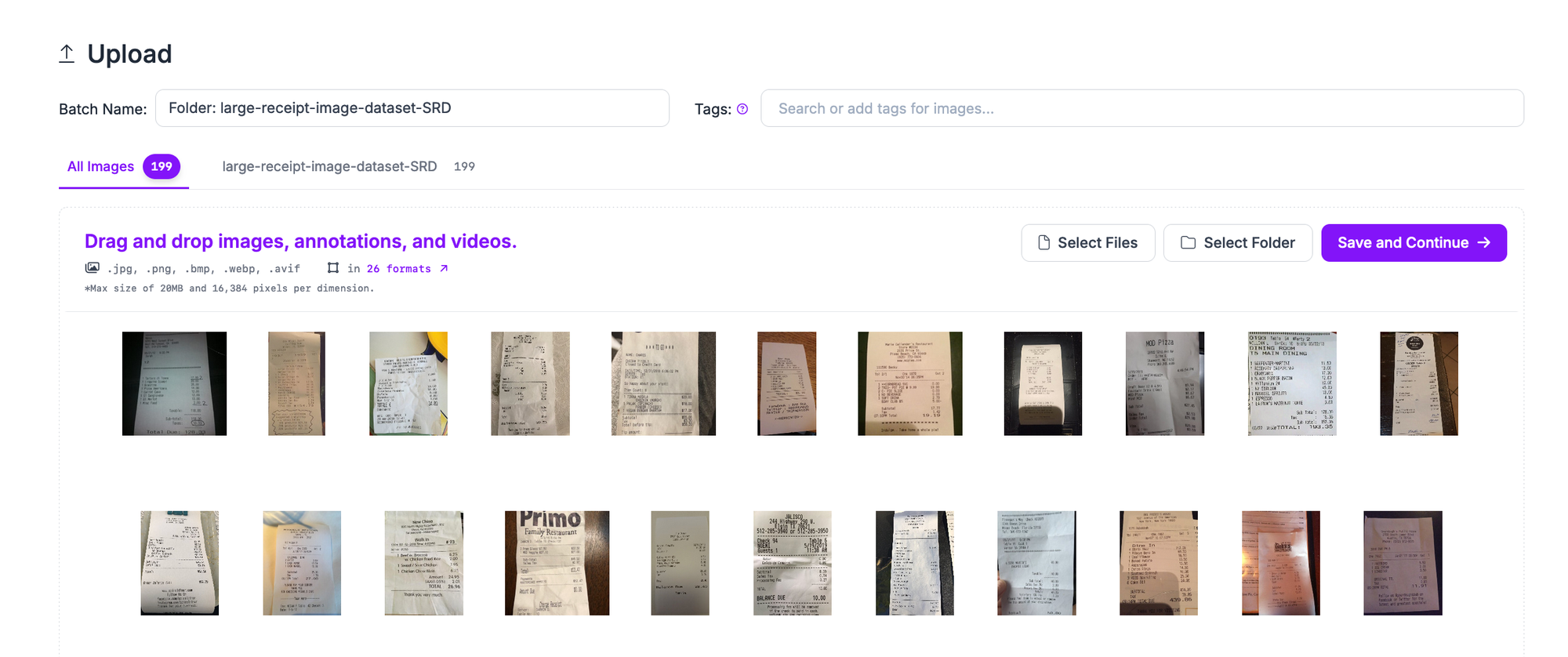
Your images will then be processed in the browser.
Click the “Save and Continue” button to save and finish uploading your data.
The amount of time it will take to upload your data will depend on how many images you are uploading and the size of your dataset.
Step #4: Annotate Multimodal Data
With prefixes ready and data imported, you can start annotating data.
To annotate data, click “Annotate” in the left sidebar and select an image to start annotating.
The Roboflow Annotate interface will appear from which you can annotate images. A window will appear with all of the questions that you configured on the Prefix page in the last step.
Here is the annotation interface for our receipt VQA project:
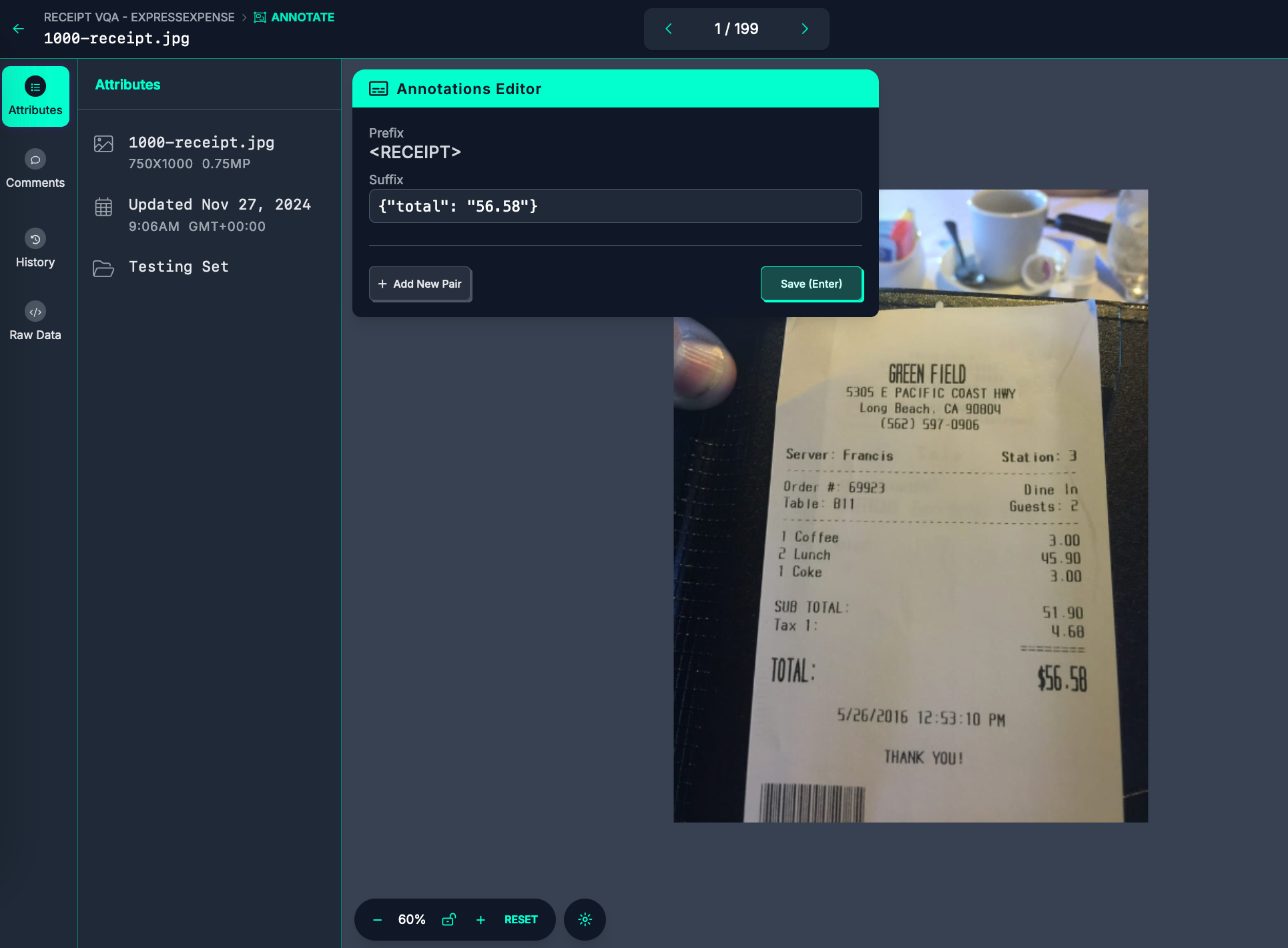
To annotate, write a text description for each prefix. Your descriptions will be auto-saved.
In the above example, our prefix is <RECEIPT> and our "suffix" (answer) is:
{"total": "56.58"}When you have annotated an image, press the left or right arrows at the top of the page to move to the next image. You can also use the arrow keys to move between images (as long as your keyboard is not focused on a text input).
Step #5: Generate Dataset Version
Next, we are going to create a dataset version. A version is a snapshot of your data frozen in time.
Click “Generate” in the left sidebar of your Roboflow project. A page will appear from which you can create a dataset version.
You can apply preprocessing and augmentation steps to images in dataset versions.
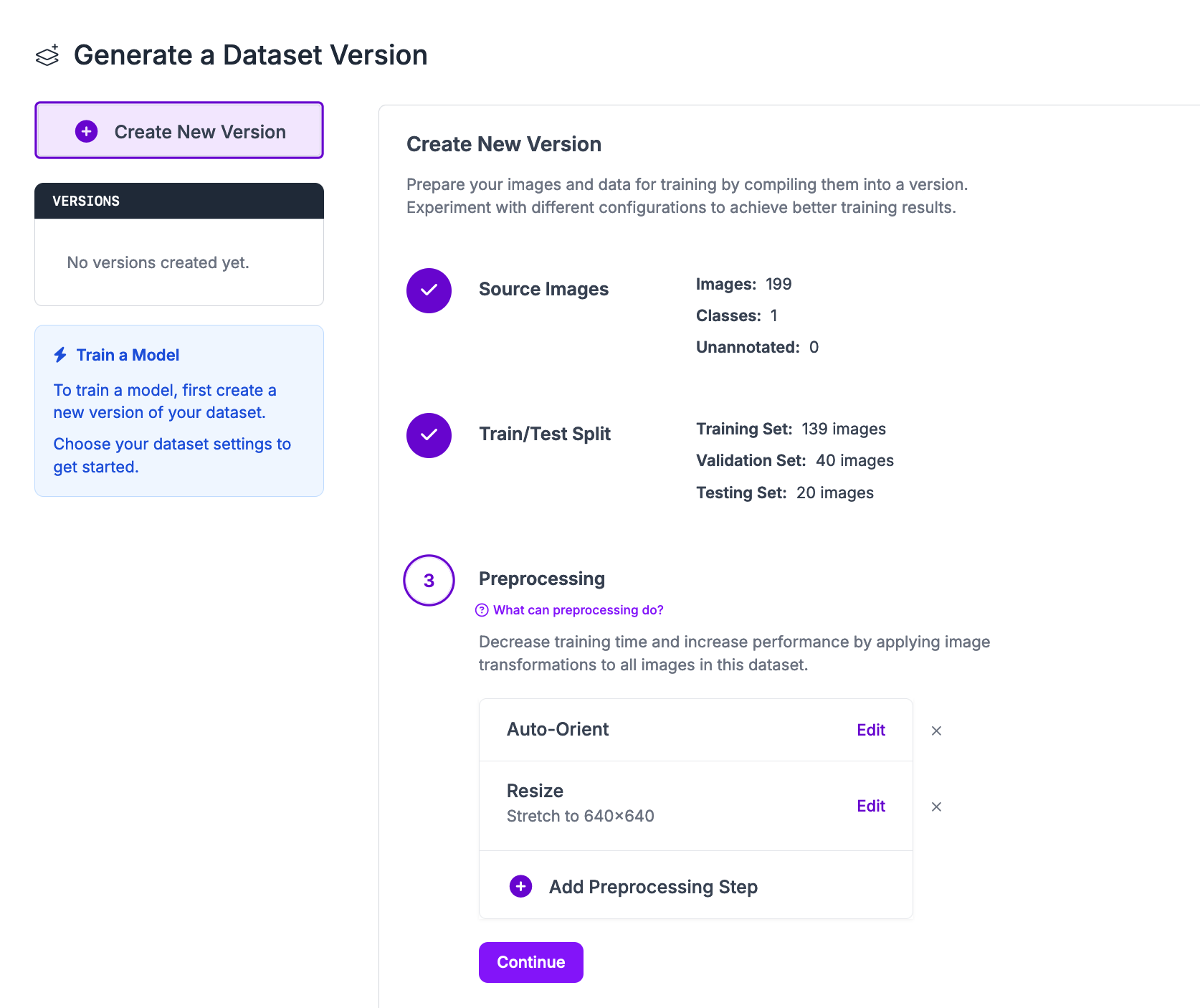
For your first model version, we recommend applying the default preprocessing steps and no augmentation steps. In future training jobs, you can experiment with different augmentations that may be appropriate for your project.
Click “Create” at the bottom of the page to create your dataset version.
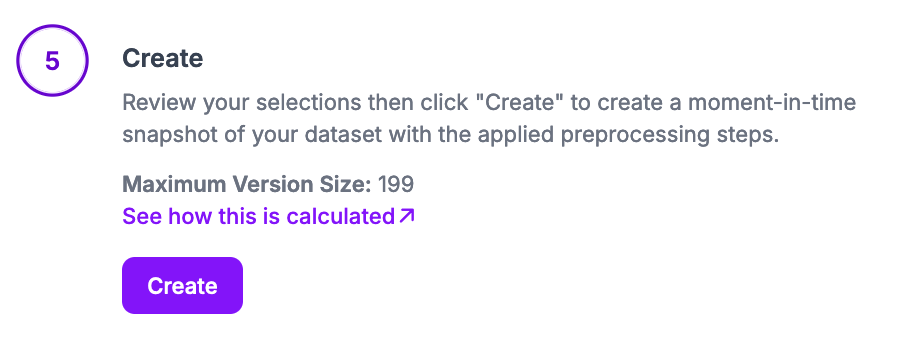
Your dataset version will then be generated. This process may take several minutes depending on the number of images in your dataset.
Step #6: Export Data or Train a Model
With your dataset version ready, you can export it for use in fine-tuning a multimodal foundation model such as GPT-4o.
You can also train Florence-2 models in the cloud with Roboflow.
To export your data, click “Export Dataset” on your dataset version page:
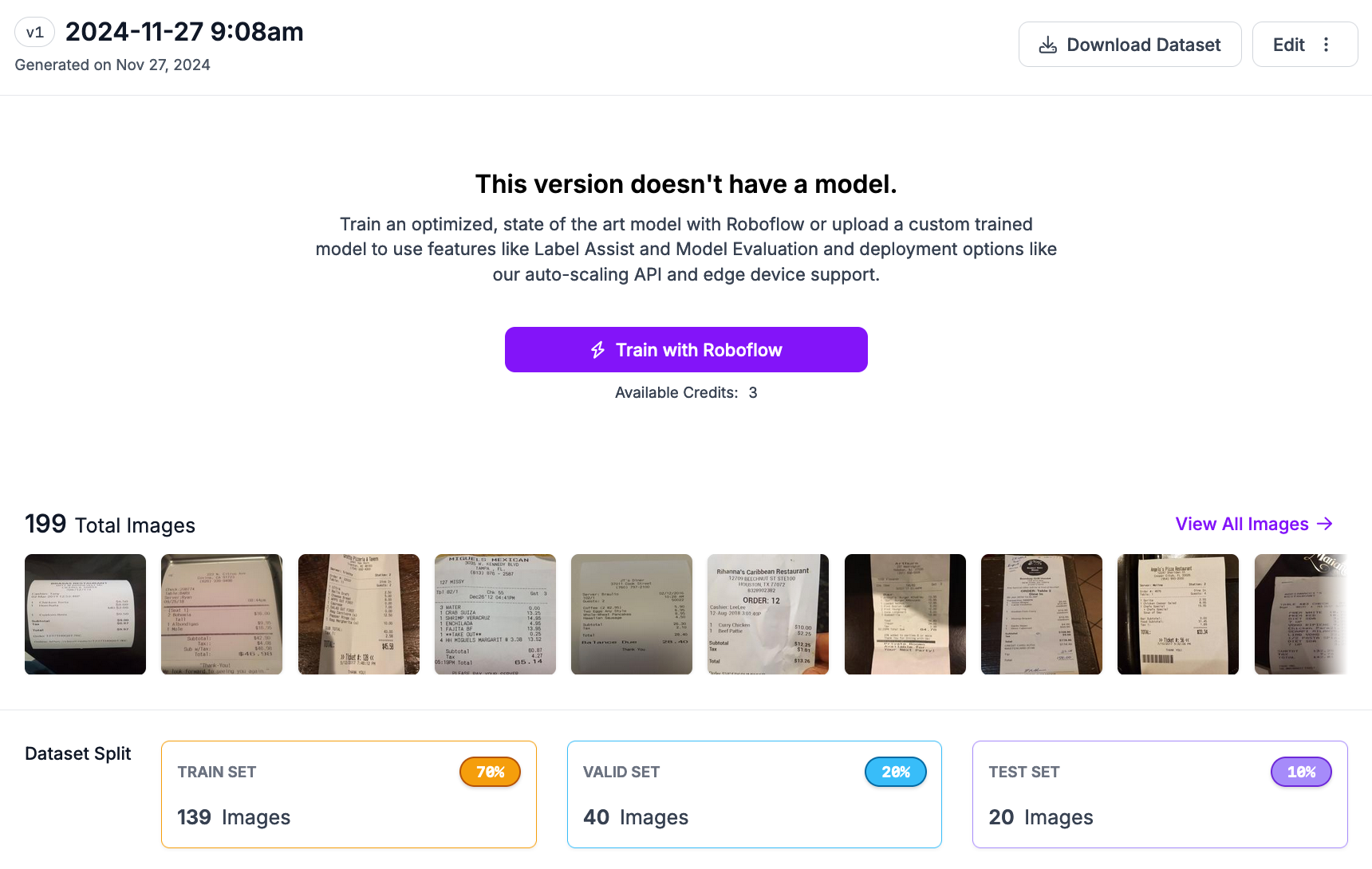
A window will appear from which you can choose the format in which to export your data. Choose the format that you need.
To train a model, click the "Train with Roboflow" button. A window will appear from which you can choose a model to train:
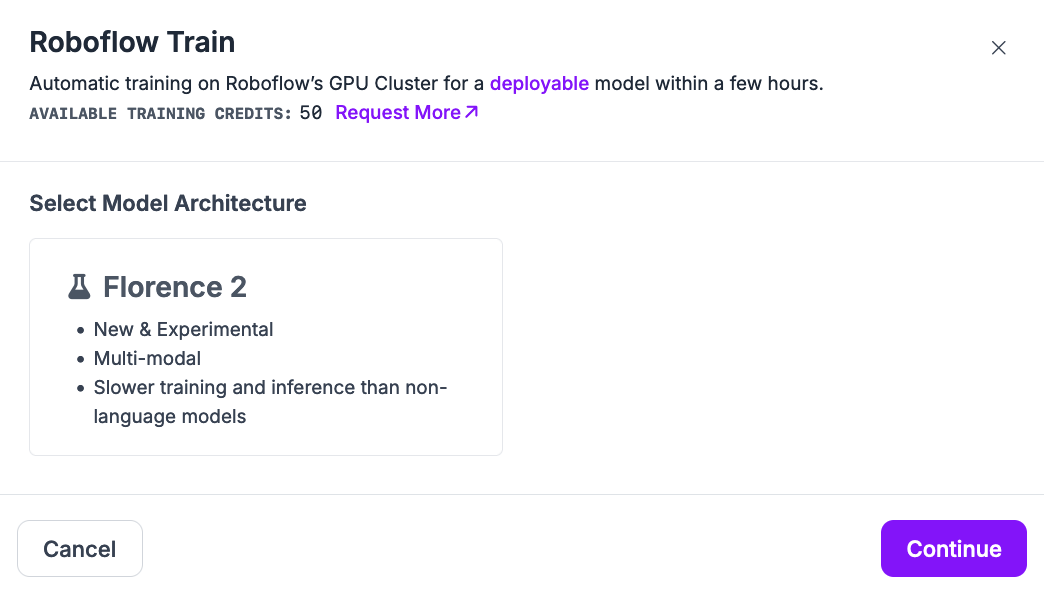
If you are interested in fine-tuning a Florence-2 model, you can follow our full Florence-2 fine-tuning guide for more information.
Next Steps
Once you have a labeled dataset, you can use Roboflow to fine-tune a multimodal vision model such as GPT-4o. To learn more about fine-tuning GPT-4o for visual question answering and other multimodal tasks, refer to our GPT-4o vision fine-tuning tutorial.
Follow the Roboflow Notebooks repository on GitHub to stay up to date on the latest multimodal and vision-language model fine-tuning guides.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Dec 3, 2024). Launch: Label Multimodal Datasets with Roboflow. Roboflow Blog: https://blog.roboflow.com/multimodal-dataset-labeling/