
Activation functions decide whether each neuron in a neural network fires, and without non-linear ones like ReLU, Sigmoid, or Softmax, neural networks could only model linear relationships. This guide covers the major activation function types including binary step, linear, sigmoid, tanh, ReLU, leaky ReLU, Swish, and Softmax, explains what makes each useful, and provides guidance on which to choose based on your output layer task: linear for regression, sigmoid for binary classification, Softmax for multi-class, and sigmoid again for multi-label problems.
Activation functions are crucial for the proper functioning of neural networks in deep learning, necessary for tasks such as image classification and language translation. These functions play a key role in determining the accuracy of deep learning model outputs. They also significantly affect the convergence ability and speed of neural networks.
Without activation functions, these complex tasks in deep learning would be difficult to handle.
In this article, we are going to discuss:
- What is an activation function?
- Why do we use activation functions?
- Key types of activation functions
Without further ado, let’s begin!
What is an Activation Function?
Activation functions determine whether or not a neuron should be activated based on its input to the network. These functions use mathematical operations to decide if the input is important for prediction. If an input is deemed important, the function “activates'' the neuron.
An activation function produces an output using a set of input values given to a node or layer. A node in a neural network is similar to a neuron in the human brain, receiving input signals (external stimuli) and reacting to them. The brain processes input signals and decides whether or not to activate a neuron based on pathways that have been built up over time and the intensity with which the neuron fires.
Activation functions in deep learning perform a similar role. The main purpose of an activation function is to transform the summed weighted input from a node into an output value that is passed on to the next hidden layer or used as the final output.
Why Are Activation Functions Important?
Most activation functions are non-linear. This allows neural networks to "learn" features about a dataset (i.e. how different pixels make up a feature in an image). Without non-linear activation functions, neural networks would only be able to learn linear and affine functions. Why is this an issue? It is an issue because the linear and affine functions cannot capture the complex and non-linear patterns that often exist in real-world data.
Activation functions also help map an input stream of unknown distribution and scale to a known one. This stabilizes the training process and maps values to the desired output for non-regression tasks like classification, generative modeling or reinforcement learning. Non-linear activation functions introduce complexity into neural networks and enable them to perform more advanced tasks.
Types of Activation Functions
Let's examine the most popular types of neural network activation functions to solidify our knowledge of activation functions in practice. The three most popular functions are:
- Binary step
- Linear activation
- Non-linear activation
Binary Step Activation Functions
The binary step function uses a threshold value to determine whether or not a neuron should be activated. The input received by the activation function is compared to the threshold. If the input is greater than the threshold, the neuron is activated and its output is passed on to the next hidden layer. If the input is less than the threshold, the neuron is deactivated and its output is not passed on.
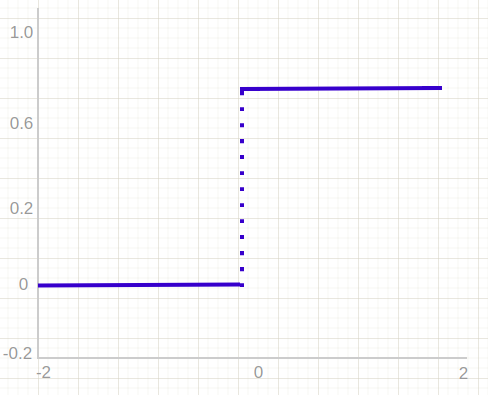
The binary step function cannot provide multi-value outputs. This means that it is unsuitable for solving multi-class classification problems. Moreover, it is not differentiable, which means that it cannot be used with gradient-based optimization algorithms and this leads to a difficult training.
Linear Activation Function
The linear activation function, also referred to as "no activation" or "identity function," is a function where the activation is directly proportional to the input. This function does not modify the weighted sum of the input and simply returns the value it was given. You may be familiar with identity functions from lambda calculus.
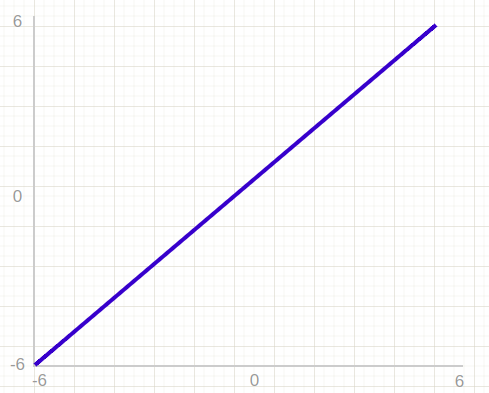
However, there are two major issues with the linear activation function.
First, this function cannot be used with backpropagation because the derivative of the function is a constant with no relation to the input, and it causes all layers of the neural network to collapse into one.
Second, no matter how many layers are present, the last layer will be a linear function of the first layer when a linear activation function is used. This effectively reduces the neural network to a single layer.
Non-Linear Activation Functions
The linear activation function is equivalent to a linear regression model. This is because the linear activation function simply outputs the input that it receives, without applying any transformation.
Let's make an example to understand why this is the case. In a neural network, the output of a neuron is computed using the following equation:
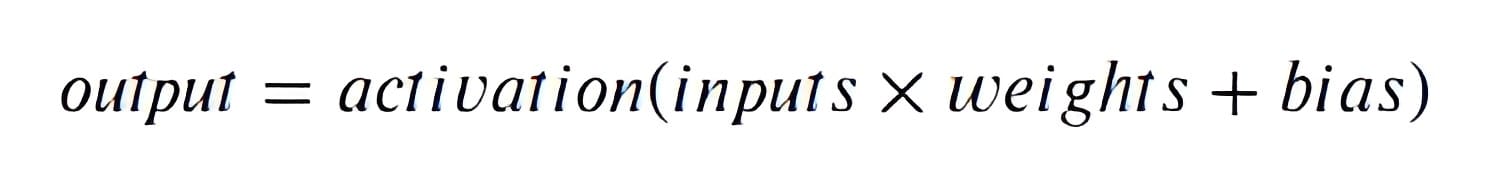
If the activation function is a linear function, then the output will be a linear combination of the inputs and this would be the same equation that is used in linear regression to model the relationships between the input and output variables.
On the other hand, non-linear activation functions address the limitations of linear activation functions by enabling backpropagation and the stacking of multiple layers of neurons. This is a standard procedure in many state-of-the-art computer vision and advanced machine learning algorithms.
Non-linear functions allow the derivative function to be related to the input, which allows a model to adjust weights in the input neurons to improve prediction. Non-linear activation functions also allow the output to be a non-linear combination of inputs passed through multiple layers. This enables neural networks to model non-linear relationships in the data.
In the next section, we’re going to talk about the most common non-linear activation functions used today. Non-linear functions are one of the most useful things in machine learning and computer vision as most of the problems in these fields cannot be solved with linear functions. So we’ll focus our attention on them.
Common Non-Linear Activation Functions
There has been significant research on non-linear activation functions in recent years, leading to the development of new and improved functions and a shift in popularity for certain ones. However, some classic activation functions are still widely used.
A few of the most commonly used and well-known activation functions are listed below. Let’s start with the sigmoid function.
Sigmoid Activation Function
The sigmoid activation function maps an input stream to the range (0, 1). Unlike the step function, which only outputs 0 or 1, sigmoid outputs a range of values between 0 and 1, excluding 0 and 1 themselves. Here’s an illustration of this function:
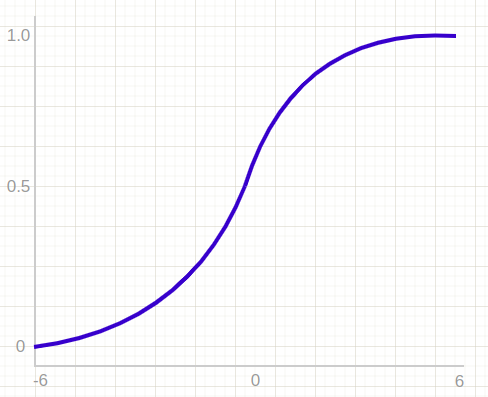
While the sigmoid function is an improvement over the previously discussed activation functions and is useful in tasks like binary classification, it has significant drawbacks when it comes to backpropagation. In particular, it suffers from both the vanishing gradient or exploding gradient.
The vanishing gradient problem happens when the gradients get smaller and smaller as the layers get deeper. This can make it difficult for the neural network to learn as the optimizer updates to the weights will be very small and this will lead to the network to stop learning.
On the contrary, the exploding gradient problem happens when the gradients get larger and larger as the layers get deeper. This can cause the weights to become very large, which can lead to numerical instability and cause the model to perform poorly.
Additionally, the output range of [0, 1] is not centered at 0, which can also cause issues during backpropagation. Finally, the use of exponential functions can be computationally expensive and slow down the network.
Tanh
The tanh activation function is similar to the sigmoid in that it maps input values to an s-shaped curve. But, in the tanh function, the range is (-1, 1) and is centered at 0. This addresses one of the issues with the sigmoid function.
Tanh stands for the hyperbolic tangent, which is the hyperbolic sine divided by the hyperbolic cosine, similar to the regular tangent. Here’s an illustration of this function:
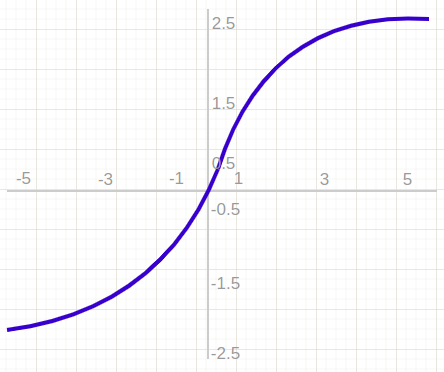
Although tanh can be more effective than sigmoid, it still suffers from the same issues as sigmoid when it comes to backpropagation with large or small input values, and it is also an exponential function.
ReLU
ReLU (Rectified Linear Unit) is a more modern and widely used activation function. ReLU is a simple activation function that replaces negative values with 0 and leaves positive values unchanged, which helps avoid issues with gradients during backpropagation and is faster computationally. Here is a graphic showing the ReLU function in use:
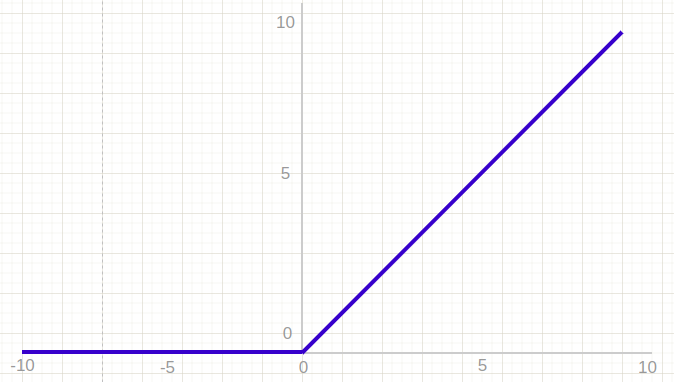
In practice, networks using ReLU tend to converge about six times faster than those with sigmoid or tanh. However, ReLU is not centered at 0 and does not handle negative inputs well. This can cause problems during training.
Leaky ReLU is an extension of ReLU that addresses these issues.
Leaky ReLU
Leaky ReLU is an extension of the ReLU activation function that aims to address the issue of negative inputs being replaced with zero by the original ReLU function. Instead of replacing negative inputs with zero, Leaky ReLU multiplies them by a small, user-defined value between 0 and 1, allowing some of the information contained in the negative inputs to be retained in the model. The representation of this function is shown below.
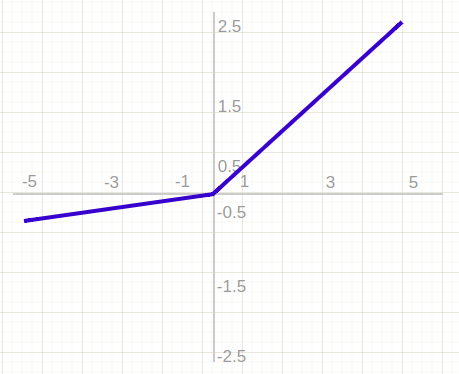
Softmax
Before exploring the ins and outs of the Softmax activation function, we should focus on its building block: the sigmoid/logistic activation function that works on calculating probability values.
Recall that the output of the sigmoid function was in the range of 0 to 1, which can be thought of as probability. However, this function faces certain problems. Let’s suppose we have five output values of 0.65, 0.9, 0.85, 0.8, and 0.6, respectively. How can we move forward with it?
The answer is: We can’t.
The values of the different classes in the output layer should add up to 1, but this is not the case with the current values. The Softmax function combines multiple sigmoids to calculate the relative probabilities of each class.
The Softmax function is used to determine the probability of each class in a multi-class classification problem. It is often applied to the final layer of a neural network. This function works similarly to the sigmoid/logistic activation function by calculating relative probabilities.
Let’s talk through an example. Say we have a model that has three classes and therefore three neurons in the output layer. The output from these neurons is given as [1.8, 0.9, 0.68]. Applying the Softmax function to these values will result in probabilities [0.58, 0.23, 0.19].
The Softmax function assigns the highest probability to the output with the highest value and assigns zero probability to the other outputs.
In this example, the output with the highest value is at index 0 (0.58), so the function assigns a probability of 1 to it and zero probability to the outputs at indices 1 and 2. This makes it convenient to use the Softmax function for multi-class classification problems.
Swish
Swish consistently matches or outperforms the ReLU activation function on deep networks applied to various challenging domains such as image classification, machine translation etc.
The output of the swish function approaches a constant value as the input approaches negative infinity, but increases without bound as the input approaches infinity.
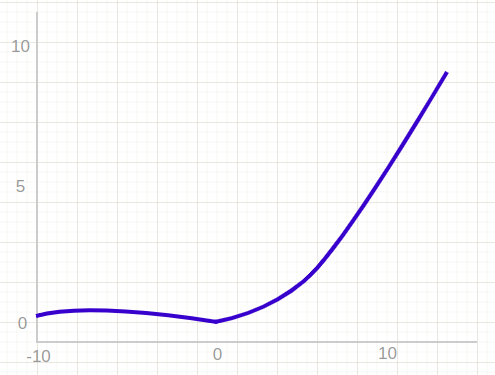
Compared to ReLU, the Swish activation function is smooth and continuous, unlike ReLU which has a sharp change in direction at x = 0. Swish gradually bends from 0 towards negative values and then back up again, rather than switching suddenly like ReLU.
In addition, the ReLU activation function converts negative values to zero, but these values may still be useful for identifying patterns in the data. Additionally, large negative values are set to zero, which promotes sparsity in the network.
How to Choose the Right Activation Function
To choose an activation function when training a neural network, it is typically a good idea to start with a ReLU-based function, as this function has been successful in a wide range of tasks. However, certain architectures, like RNNs and LSTMs, may require specific activation functions like sigmoid or tanh.
It is recommended to use the ReLU activation function only in the hidden layers of a neural network. In addition, Sigmoid/Logistic and Tanh functions should not be used in the hidden layers of a neural network because they can cause issues with training due to vanishing gradients.
Here are some guidelines for selecting an activation function for the output layer based on the type of prediction problem:
- Regression: Use Linear Activation Function
- Binary Classification: Use Sigmoid/Logistic Activation Function
- Multi-class Classification: Use Softmax
- Multi-label Classification: Use Sigmoid
Key Takeaways On Activation Functions
Now, let’s have a quick recap of everything we have covered!
Activation functions are an essential component of neural networks, as they determine the output of the neural network. Non-linear activation functions are the most commonly used and are necessary for introducing complexity into the network.
Activation functions help map input values to a known range, which helps stabilize training and helps map values to a desired output in the last layer. The most popular activation functions include binary step, linear, sigmoid, tanh, ReLU, and Softmax.
The choice of activation function depends on the type of neural network architecture and the type of prediction problem being solved. It is important that the activation function is differentiable in order for the network to be trainable using backpropagation.
For more computer vision education posts, visit our Learn Computer Vision page.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Jan 12, 2023). What is an Activation Function? A Complete Guide.. Roboflow Blog: https://blog.roboflow.com/activation-function-computer-vision/