
Roboflow 100 (RF100) is an open-source object detection benchmark built to address the limited domain scope of COCO and Pascal VOC. It spans 100 datasets, 7 imagery domains, 224,714 images, and 829 class labels accumulated across more than 11,000 labeling hours, covering areas like aerial imagery, medical imaging, and satellite data that standard benchmarks omit. Initial experiments evaluating YOLOv5, YOLOv7, and GLIP on RF100 show that models trained on COCO perform well on semantically similar domains but degrade significantly on dissimilar ones, making cross-domain evaluation a better proxy for real-world generalization.
Advancing the state-of-the-art in object recognition with a new way to benchmark computer vision models across domains and task targets.
What is Roboflow 100?
Roboflow 100 (RF100) is a crowdsourced, open source object detection benchmark. It consists of 100 datasets, 7 imagery domains, 224,714 images, and 829 class labels with over 11,170 labeling hours.
RF100 aims to create an accessible, transparent and open-sourced benchmark for machine learning object detection models and assert generality using in the wild crawled datasets. RF100 is an Intel sponsored initiative.
You can download RF100 by following the instruction on the GitHub repo or in Roboflow Universe by clicking the export button in each dataset.
You can explore and visualize the data by playing with the visualization tool below. Similar images are clustered close to each other. To interact with the full visualization, check out the Roboflow 100 website.
Goal and Motivation
Microsoft COCO and Pascal VOC are well-known datasets used to train and evaluate computer vision models. Pioneering computer vision research is regularly benchmarked against COCO, for example, to give researchers and engineers a common set of statistics with which to understand model performance.
COCO and VOC datasets have a limited domain scope due to the nature of the data. Models pre-trained on COCO or VOC are usually used for domain-specific tasks, and evaluating narrow domain datasets may not be the best proxy of a model's performance in the wild.
For example, COCO does not contain medical images. As a result, it is difficult to be sure how a given model will perform in the medical domain when benchmarked against COCO.
We made the Roboflow 100 to help address the limited domain problem, providing engineers and researchers with a collection of 224,714 images across 829 classes against which models can be benchmarked. RF100 is a complement – not replacement – for datasets of common objects in context.
Furthermore, we observed researchers, including the Microsoft Research teams behind Florence and GLIP, were organically citing community-created Roboflow Universe datasets to assess the robustness of models beyond COCO. Thus, we saw an opportunity to make this process of assessing model capabilities beyond common objects in context, and RF100 is the first result.
RF100 is composed of images annotated in the wild and represents real data people used to train a model. By open-sourcing RF100, we hope to help researchers test a model's ability to generalize across domains. The RF100 dataset is inspired by the robust Objects365 and Object Detection in The Wild benchmarking projects.
Data Collection
RF100 is comprised of 100 datasets selected from Roboflow Universe, an online repository of open-source images. Roboflow Universe contains over 100,000 datasets and images were selected using the following criteria:
- Effort: The user spent substantial labeling hours working on the task;
- Diversity: The user was working on a novel task;
- Quality: The user annotated with high fidelity to the task;
- Substance: The user assembled a substantial dataset with nuance and;
- Feasibility: The user was attempting a learnable task.
Before including a dataset in the Roboflow 100 benchmark, we conducted a series of processing steps. These were:
- Resizing all images to
640x640pixels; - Eliminating class ambiguity;
- Splitting the data in train, validation and test and;
- Suppressing under-representing classes (less than
0.5%).

Data Overview
The data in RF100 is definitionally informed by the areas computer vision is being used in practice. When assessing an initial set of novel domains, we observed clusters to categorize datasets.
We selected seven different semantic categories to achieve comprehensive coverage of different domains:
- Aerial: Space, static cameras, and drones
- Video games: First-person shooting, multiplayer online battle arena, and robot fighting
- Microscopic: Human, plants, and inanimate
- Underwater: Aquarium and sea
- Documents: Social media and structured
- Electromagnetic: Night-vision, x-ray, thermal, and MRI
- Real World: Indoor, damage, vehicles, safety, electronics, animals, plant, geology, and various human activities
The following image shows a curated example of images per category:

You can find all the datasets in the RF100 benchmark on Roboflow Universe.
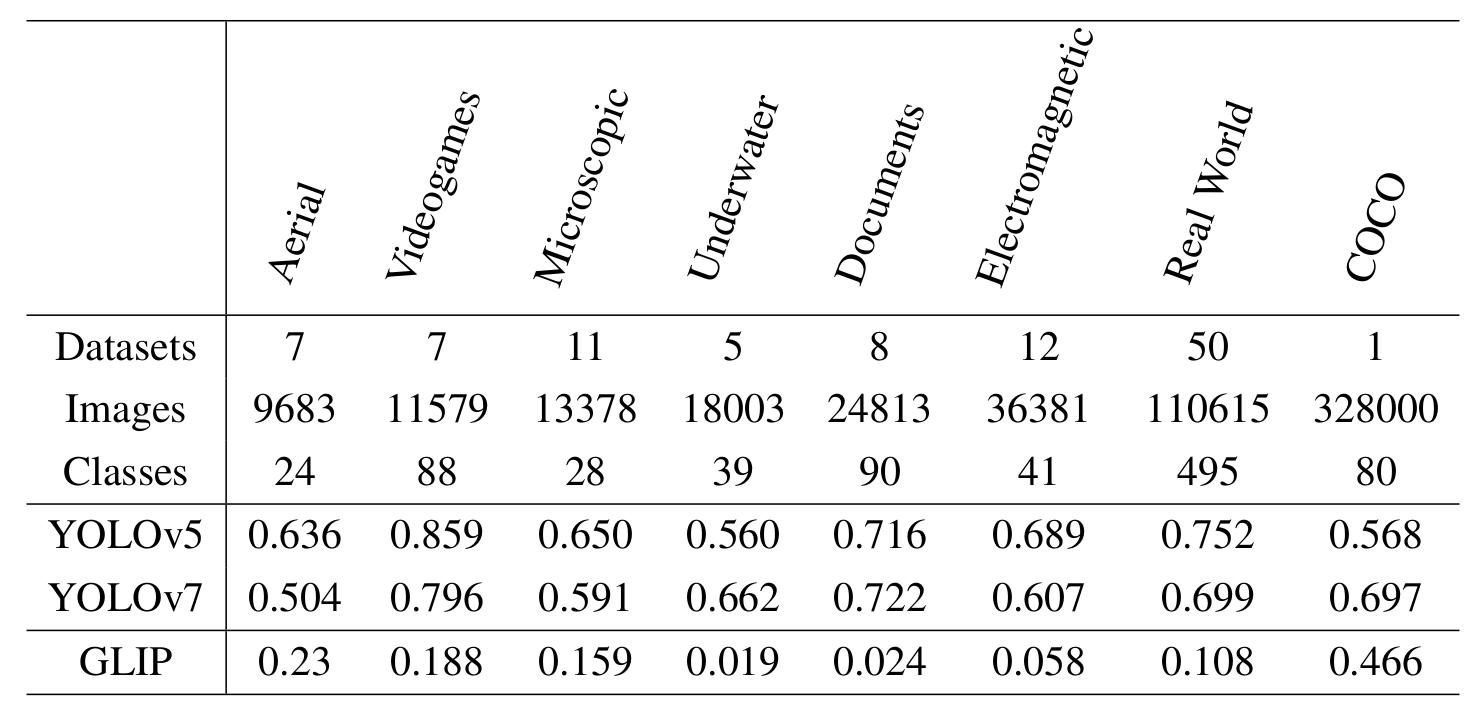
Dataset Statistics
In our research, we investigated different statistics. These included dataset size, bounding boxes (bbox) area, and number of categories. This helped us better understand the representation of each category of data in our dataset. The following image groups statistics by category:
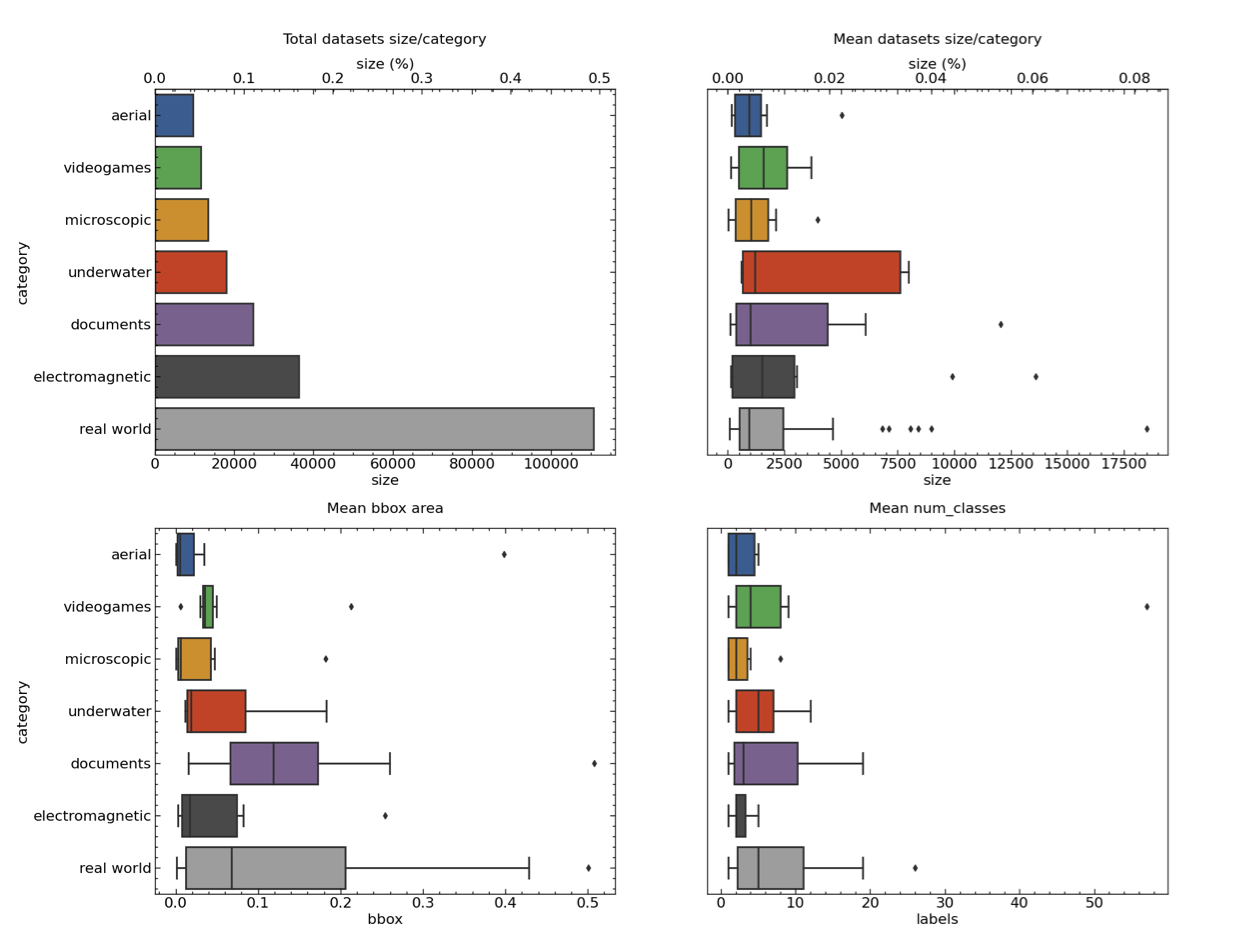
Notably, Aerial, Microscopic and Electromagnetic have smaller bounding boxes compared to the rest. The average number of classes across different categories is only ten, meaning in practice the use case is to identify a small set of objects.
To further visualize the data, we encoded each image with CLIP and plotted the reduced embeddings via TSNE.
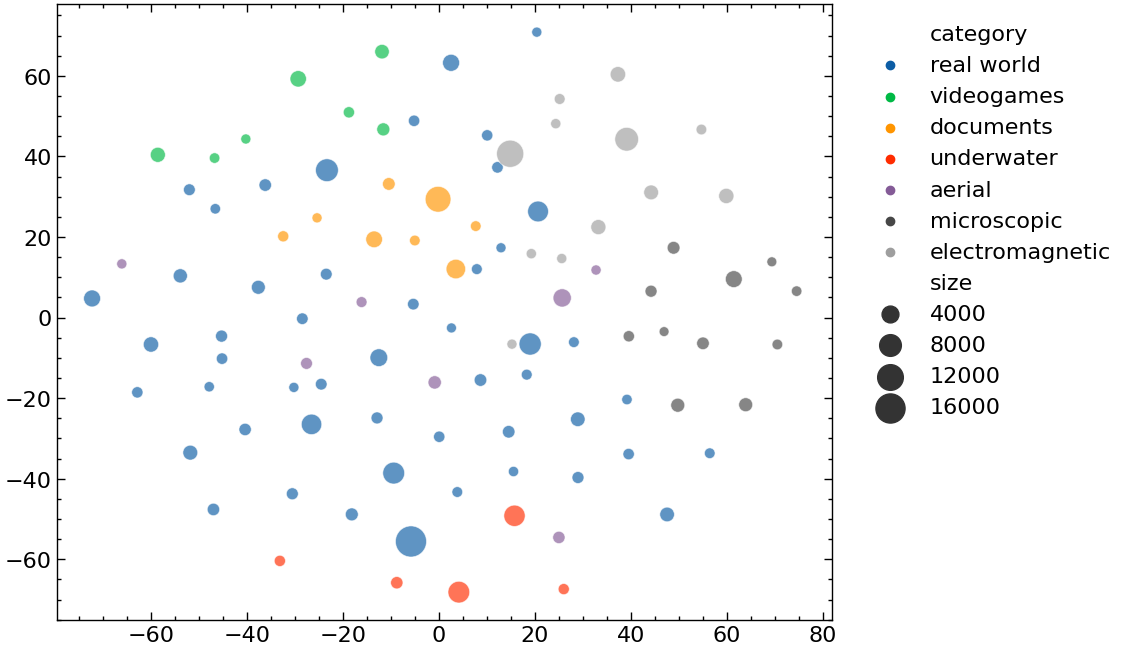
A high-performance web application is available to help you visualize and explore the datasets.
Experiments
We evaluated YOLOv5 and YOLOv7, two popular object detection model architectures, and GLIP, in a zero-shot fashion, on RF100 and report the results.
Since the goal was to compare intra-model performance, we trained only one instance per dataset. We used YOLOv5 small, YOLOv7 base both pre-trained on COCO and GLIP-T pre-trained on O365, GoldG, CC3M, SBU. Both YOLOv5 and YOLOv7 have comparable performance.
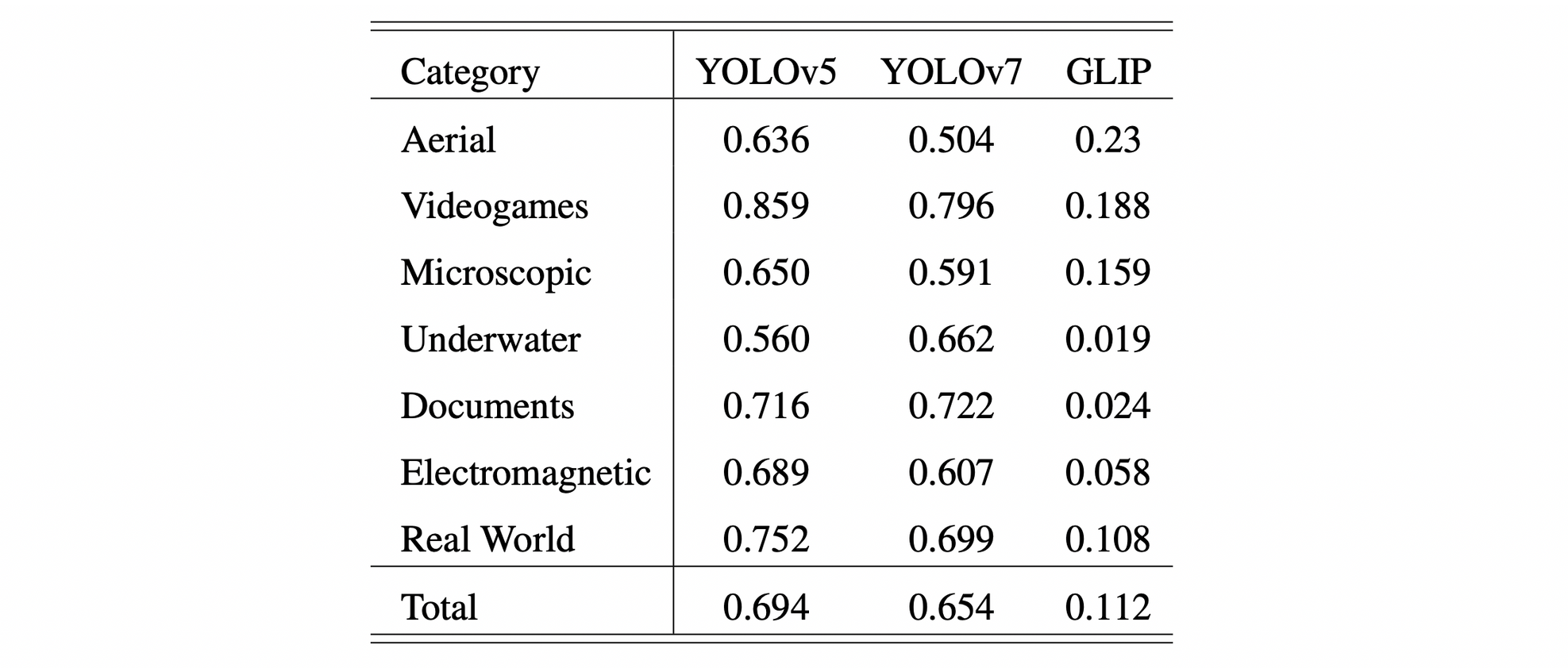
Supervised trained models perform well on datasets somewhat similar to COCO, while performing worst on different semantically different datasets, e.g. on Aerial.
Meaning, model evaluation on semantically different datasets is a helpful proxy for downstream model performance, especially in domain settings that differ from the web imagery in COCO.
Arxiv
Conclusion
We introduce the RF100 object detection benchmark of 100 datasets to encourage the evaluation of object detection model performance to test model generalizability across a wider array of imagery domains.
Our initial evaluation shows that the new RF100 benchmark will provide valuable insights into how new object detection models will perform in the wild on tasks previously unassessed.
Cite this Post
Use the following entry to cite this post in your research:
Francesco, Jacob Solawetz, Joseph Nelson. (Nov 28, 2022). 📸 Roboflow 100: A Multi-Domain Object Detection Benchmark. Roboflow Blog: https://blog.roboflow.com/roboflow-100/