
Object detection can unlock new possibilities for every industry, and create entirely new applications that were not possible before. Because there are many situations where knowing whether something is in an image or in a video is helpful.
Consider a scenario where you are building a sports analytics system. If you can detect what is in a video feed showing a game, you can count players in a region, track how long players are in different regions, and more. As a result, you can analyze plays' effectiveness, a players' performance, scout the competition faster, and all sorts of things.
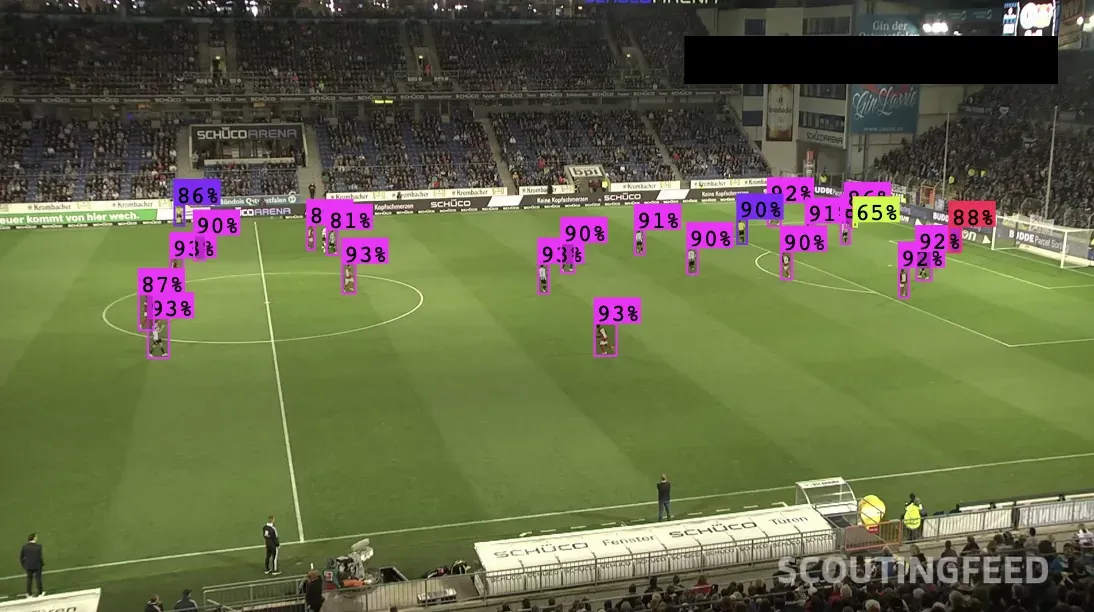
Here's an example of object detection being used on a football field, detecting players:
This is where object detection comes in. Object detection is a computer vision solution that identifies what is in an image and where the detected objects are in the image. With object detection, you can also identify where something is in an image, which can help you answer questions like "Is there a person in a restricted area?" or "Is there a part present in the top corner of this product?".
The use cases of object detection are wide ranging: from identifying issues with products to finding anomalies in medical images to detecting cracks in rails to analyzing video for various insights.
In this guide, we are going to discuss what object detection is, how it works, when it is useful, and how object detection compares to other computer vision solutions.
You can try an object detection model with the following Workflow:
Drag and drop an image you want to detect objects in. Then, say what objects you want to detect. Run the Workflow to see the object detection model in action.
Without further ado, let's get started.
What Is Object Detection?
Object detection is a computer vision solution that identifies objects, and their locations, in an image. An object detection system will return the coordinates of the objects in an image that it has been trained to recognize. The system will also return a confidence level, which shows how confident the system is that a prediction is accurate.
Let's take a look at the results from a product detection model:

In the above photo, all products and areas on a shelf with empty products are highlighted with boxes. These boxes are the coordinates where the object detection system – called a model – thinks an object is present. We call prediction boxes "bounding boxes" in computer vision.
The percentage numbers next to each label tell us how confident the model is that a prediction is correct. In this case, the yellow labels indicate a product is present; the pink labels indicate there is an empty space.
Once you know what is in an image or video, you can apply post-processing to derive more insights from the visual media. For instance, you can answer questions like "for how long does an object appear in a video?" by using the computer vision model over each frame in a video and tracking when the object appears and disappears.
You can also answer questions such as:
- How many instances of an object are in an image?
- How many times does an object show up in an image?
- Is there an object in a specified region of an image or video?
How To Detect Objects
Object detection models need to be trained. This refers to a process by which a neural network is created and learns features from an image. A neural network learns features by being shown images of an object in many different scenarios (i.e. different backgrounds, objects at different angles), with labels corresponding to the object and its location.
Here is an example of an annotated image for object detection:

Here, you can see a box that corresponds to the location of a particular object. This will be used as input to the neural network, alongside the image, during the training stage.
Images are labeled either manually, using a machine-assisted computer vision labeling tool like Roboflow Annotate, or using a semi-automated solution like Autodistill. The more accurate and consistent the annotations are, and the more representative images are for the environment in which a model will be deployed, the better a model will perform.
These features are learned and encoded in "weights" and "biases", which are saved after training to be used in testing and production.
Models can learn how to identify multiple objects. With that said, most production use cases only require identifying a few objects. Using Roboflow, you can go from a folder of images to a fully-trained computer vision model faster than ever.
What Is Object Detection Used For?
Object detection can be used for any problem where you need to know if an image or video contains a specific object or multiple objects and where those objects are located. You can also use object detection when you need to check whether something is present in an image or video.
Because of this broad utility, computer vision has found uses across industries. Let's talk through a few industries that are using object detection today to solve problems.
Transportation Infrastructure
Transportation providers can use object detection to assure safety across their networks, for example, by identifying obstacles on a train track or for workplace safety to check if there is somebody present in a restricted area on a work site.
Food Manufacturers
Food manufacturers can use object detection for defect detection and to assure the integrity of products before they are packaged and sent away. For example, you can use vision to make sure that the right lid and packaging are assigned to the correct yogurt during production.
Autonomous Vehicles
Over the last decade, there has been significant work done to create cars that safely drive themselves. Behind this innovation is computer vision. Cars need to be able to detect certain objects such as pedestrians, traffic lights, traffic cones, etc. so they can make decisions about what to do and where to go. Automotive manufacturers also use object detection to ensure the parts of each car are high-quality and properly aligned.
Object Detection Models and Architectures
Several object detection architectures have shaped the computer vision landscape over the last decade: Convolutional Neural Networks (CNNs), You Only Look Once (YOLO), and, more recently, transformer-based detectors like RF-DETR. Each has contributed to the modern computer vision industry.
CNNs use convolutions, an image processing technique, to learn features about an image. This process involves applying a sliding window across every pixel in an image to learn features. The information from convolutions is processed by a neural network. There are many implementations of CNNs, including R-CNN, Mask R-CNN, and Fast R-CNN.
The YOLO family of models has also been influential in the world of computer vision. Introduced in 2014 by Joseph Redmon, YOLO has been both an active area of research and development and seen wide community adoption, as well as implementations by many developers and researchers. YOLOv5 and YOLOv8, developed and maintained by the Ultralytics team, power production object detection models around the world.
RF-DETR is Roboflow's real-time, transformer-based object detection model. Built on the DETR architecture, RF-DETR delivers strong accuracy across a wide range of object sizes and is designed to be a drop-in solution for production deployments. It is a compelling choice for teams looking for state-of-the-art performance without the complexity of tuning anchor-based detectors.
Curious to learn more about YOLO? Check out our complete guide to the YOLO family of models, in which we go from the beginnings of the architecture with the first YOLO model to today's popular YOLO11 model.
In 2023 and 2024, "zero-shot" object detection models rose to greater prominence. These are models that can accept an aribtrary text prompt and identify objects associated with the prompt. Grounding DINO is one of the best examples. With Grounding DINO, you can provide a text prompt and identify corresponding objects.
Zero-shot models require no fine-tuning to use, although can be fine-tuned for greater performance in specific domains.
Here is an example showing Grounding DINO identifying a wide variety of objects in an image:

Object Detection vs. Classification vs. Segmentation
Object detection models tell you both if an image or video contains an object and, if so, where that object is. Models can identify multiple different objects in the same image or video.
This is in contrast to image classification, which can only assign a single label that is representative of an image. Classification models tell you if an image fits into one for multiple categories, whereas object detection models can tell you both what is in an image and where each instance of an object is in an image.
If you need to know at a pixel level where an object is in an image, image segmentation is useful. Segmentation is another computer vision solution in which the specific location of an object in an image is identified. This precision has some trade-offs, however: labels need to be done as precisely as possible, and retrieving predictions is typically slower.
How to Get Started: Object Detection Datasets and Models
Before you start training your own models, we encourage you to explore other models to experience computer vision for yourself. Here are a few different models to play around with:
There are many different entry points to object detection. A common path is to use a tool such as Roboflow, which will introduce you to the workflow of building an object detection model without requiring code. If you have some coding experience, you can get started by training your own computer vision model.
The steps you'll need to follow to create your first object detection model are:
- Decide on what you want to detect;
- Collect data for your project;
- Label data with bounding boxes or polygons;
- Train an object detection model using a model like RF-DETR, and finally;
- Test the model.
Roboflow has guides that can assist with following this process. Our getting started guide will get you training object detection models without any code. Our How to Train guides, such as our How to Train RF-DETR guide, walk through all you need to know to train computer vision models with code. These guides are accompanied by interactive "notebooks", code documents with accompanying text instructions, that you can use to train a model.
Using Object Detection
Object detection is a computer vision solution that powers systems around the world. From identifying defects in products to ensuring safety on work sites to powering autonomous vehicles, object detection can help.
With an object detection system, you can identify what is in an image or video and where objects are in an image. RF-DETR and CNNs are two of the most prominent architectures used for object detection today. RF-DETR, Roboflow's real-time transformer-based detector, offers state-of-the-art accuracy and is well-suited for production deployments across a wide range of use cases.
Object detection models learn how to identify objects by being shown images with labels that correspond to the location of objects you want to identify in an image.
Roboflow provides all the tools you need to go from an idea to a fully-trained computer vision model. You can use Roboflow Universe to find labeled images to use in a project, Roboflow Annotate to label your own data, Roboflow Train to train a model, and Deploy to deploy a model to a range of devices, from iOS to NVIDIA GPUs. Get started free.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (May 30, 2025). What Is Object Detection? How It Works and Why It Matters. Roboflow Blog: https://blog.roboflow.com/object-detection/