![What is Computer Vision? Comprehensive Guide [2026]](https://storage.ghost.io/c/2c/8d/2c8d8c0d-1c15-4b6d-825e-02b78d61d40a/content/images/size/w1200/format/webp/2026/06/img-blog-introduction-to-computer-vision-1.png)
Computer vision gives computers the ability to identify, locate, and interpret objects in images and video. This guide covers the foundational task types, including image classification, object detection, semantic segmentation, instance segmentation, and keypoint detection, explaining what each does and when to use it. It also walks through the practical steps for starting a project: collecting data, labeling it with annotation tools, training a model, and deploying it for inference.
Computer vision has the potential to revolutionize the world.
Historically, in order to do computer vision, you've needed a really strong technical background. That is no longer the case. As the field of computer vision has matured, you can worry less about the engineering details and more on how computer vision can help you solve a specific problem.
After reading this post, you should have a good understanding of computer vision without a strong technical background and you should know the steps needed to solve a computer vision problem.
What is computer vision?
Computer vision is the ability for a computer to see and understand the physical world. With computer vision, computers can learn to identify, recognize, and pinpoint the position of objects.
Consider the following scenario: you want to take a drink from a glass of water. When you have this idea, multiple things happen that require use of visual skills:
- You have to recognize that the thing in front of you is a glass of water.
- You have to know where your arm and the glass are, then move your arm in the direction of the glass.
- You have to recognize when your hand is close enough to properly grab the glass.
- You have to know where your face is, then pick up the glass and move it toward your face.
Computer vision encompasses all of these same processes, but for computers!
Computer vision problems fall into a few different buckets. This is important because different problems are solved with different methods.
What is machine vision?
Machine vision is an application of computer vision in industrial use cases. Machine vision can be used for to detect defects, manage inventory, monitor stages of a production pipeline, ensure workers wear the appropriate PPE in controlled workplace settings, and more.
You will likely hear "machine vision" and "computer vision" used interchangeably, but in many cases people use "machine vision" to refer more specifically to industrial applications of computer vision. You can imagine this the relationship between machine and computer vision like nesting dolls. Machine vision is a more focused subset within computer vision.
Generally, both machine vision and computer vision are concerned with identifying, segmenting, tracking, or classifying features in images, and use the information gathered to perform a function (i.e. to slow down a production pipeline, to notify a manager of an issue, to log an event like a forklift entering a construction site).
What is computer vision used for? Computer vision use cases
Computer vision is transforming industries from robotics and manufacturing to healthcare and sports. Already today, vision AI systems are unlocking new levels of automation, efficiency, and insight. As just one recent example, the Paris 2024 Olympics used AI to track athlete movements in volleyball, diving, and gymnastics. Let’s take a look at real-world applications of computer vision, revealing how this technology is already shaping the future.
Robotics: Computer vision enables robots to identify and track objects for tasks such as inventory management, sorting, and assembly line operations. Self-driving cars and drones use LiDAR and vision-based mapping to move safely while avoiding obstacles.
Manufacturing: Manufacturers are leveraging real-world vision AI systems to help avoid jams and pile ups, identify defects in products, packaging, and labels, and alert staff to safety and health hazards. Companies such as Audi are already using computer vision for quality inspection and welding processes.
Logistics: Warehouses, shipping, and inventory management are already being streamlined by real-world vision. Amazon uses vision-powered robots (Sparrow, Robin, Cardinal) for defect detection and package handling; DHL has implemented AR smart glasses for hands-free warehouse sorting; and UPS deploys AI-driven drones for autonomous deliveries.
Sports: Vision AI is impacting everything from player tracking to fan engagement. The main use fans have probably already encountered is minimizing human error in officiating. Did you know the 2024-2025 English Premier League’s Semi-Automated Offside Tech (SAOT) brings instant, precise offside rulings? And Formula One leverages AI to detect track limit violations automatically.
Healthcare: The healthcare industry is rapidly adopting computer vision technology to improve patient care and save time. Computer vision is used for pill counting and identification, sterilizing medical equipment, and even detecting cancerous cells through ai-assisted screening.
Data analytics: Real-world AI is revolutionizing analytics allowing for historical data analysis, extracting patterns from video feeds to optimize parking lot usage or track customer movement in retail stores to optimize product placement and staffing.
Computer vision is even used in agriculture for inspecting crops, detecting plant diseases, and assessing soil quality for more efficient farming practices. Explore even more computer vision case studies from smart home monitoring to coffee bean inspection.
What are the different types of computer vision problems?
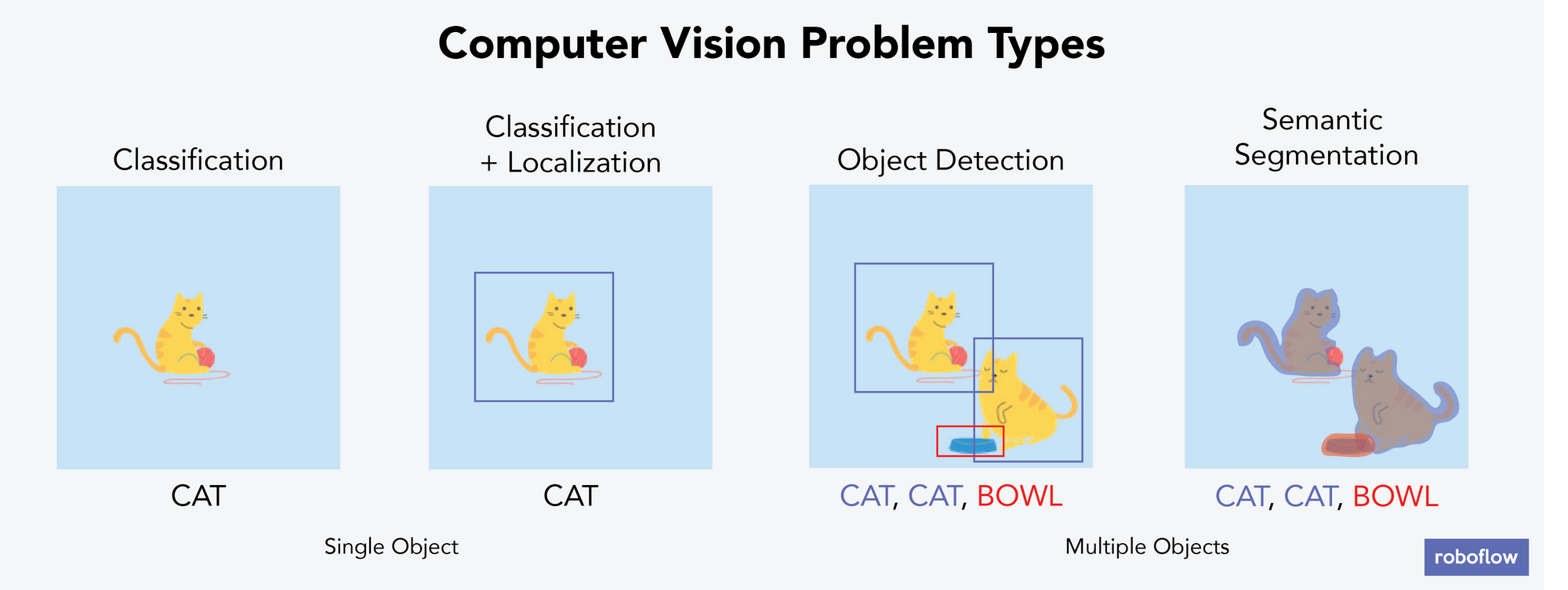
There are six main types of computer vision problems, four of which are illustrated in the above image and detailed below. Let's talk about each of the main types of computer vision problem types, alongside examples of real-world problems that can be solved by each type of problem. These are:
Image classification
Image classification is the process of categorizing each image into one bucket. For example, if you had a stack of 100 images that each contain either one cat or one dog, then classification means predicting whether the image you hold is of a cat or a dog.
In each image, there is only one object you care about labeling – your computer wouldn't identify that two dogs are in an image or that there's a cat and a dog – just that an image belongs in the "dog" bucket or the "cat" bucket.
Classification and localization
Categorizing each image into one bucket and identifying where the object of interest is in the frame. For example, if you had a stack of 100 images that contain either one dog or one cat, then your computer would be able to identify whether the image contains a dog or cat and where in the image it is.
In each image, there is only one object you care about labeling. In localization, the computer identifies where that object is using something called a bounding box.
A real-world example is using computer vision to fight wildfires by detecting smoke in a specific location.
Object detection
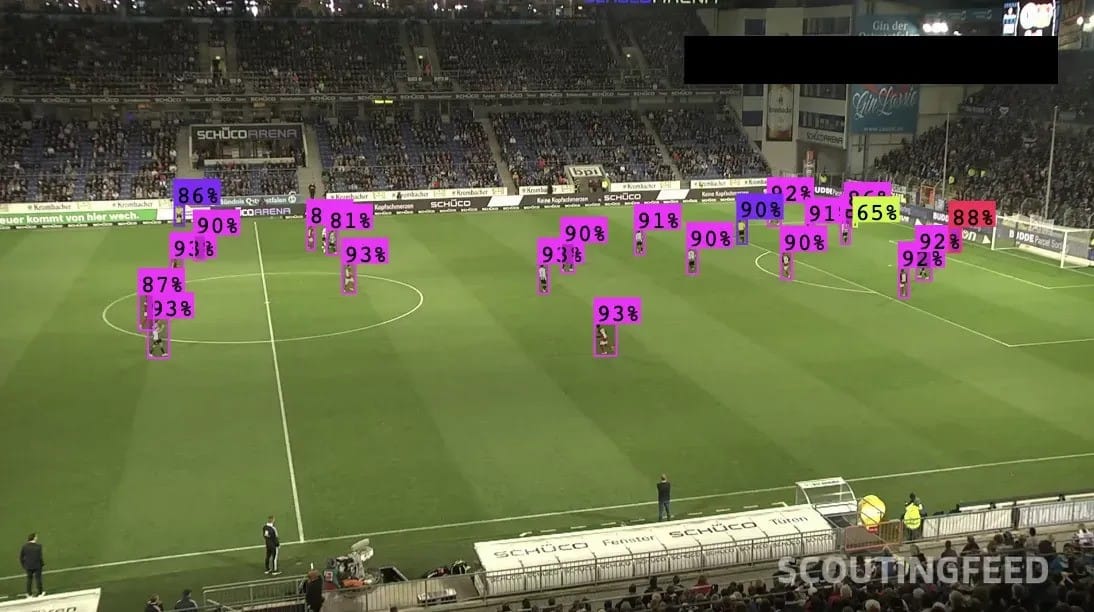
Object detection means identifying where an object of interest is, for any object of interest. For example, if you had a stack of 100 images and each is a family photo with pets, then your computer would identify where the humans and the pets were in each image. Images can contain any number of objects; they aren't limited to only one.
A real-world example of object detection is using computer vision to identify individual players in a game.
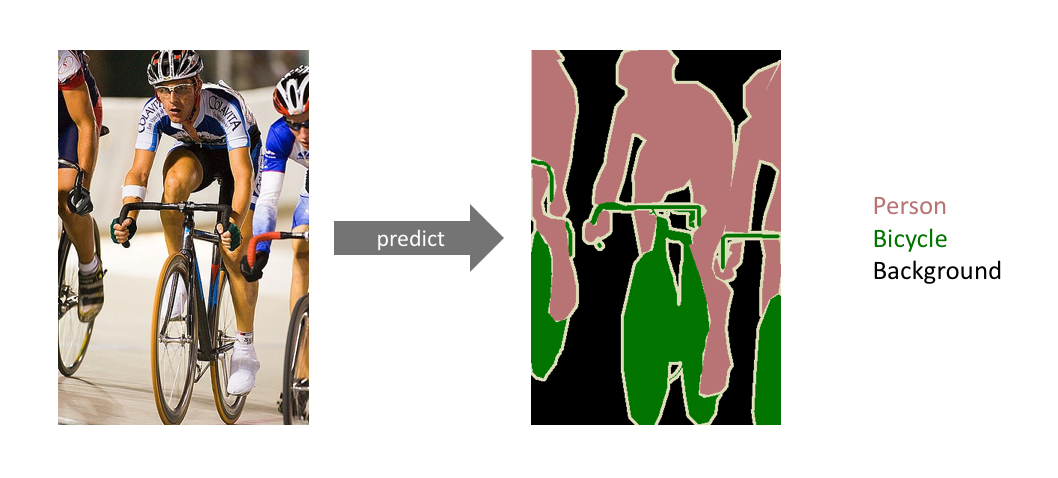
Semantic segmentation
Semantic segmentation means detecting the set of pixels belonging to a specific class of object. This is like object detection, but object detection places a bounding box around the object, while semantic segmentation tries to more closely identify each object by assigning every pixel into a class.

This is a good solution for any computer vision problem that requires something more delicate or specific than a bounding box. The image below is an example of semantic segmentation.
Instance segmentation
Instance segmentation differentiates between objects in the same class. In the image above, there appear to be three people and three bicycles. Semantic segmentation classifies each pixel into a class, so each pixel falls into the "person," "bicycle," or "background" bucket. With instance segmentation, we aim to differentiate between classes of objects (person, bicycle, background) and objects within each class – e.g. tell which pixel belongs to which person and which pixel belongs to which bicycle.

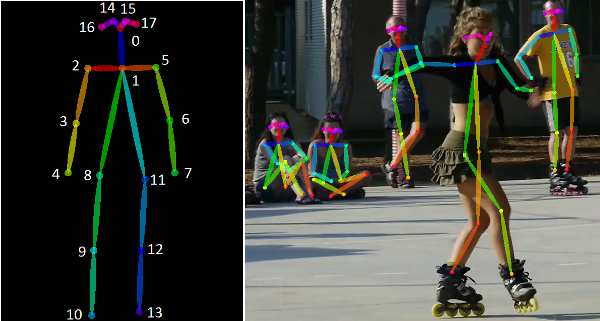
Keypoint detection
Keypoint detection, also called landmark detection, this is an approach that involves identifying certain keypoints or landmarks on an object and tracking that object.
On the left side of the image below, notice that the stick-like image of the human is color-coded and important locations, the the keypoints, are identified with a number. On the right-hand side of the image we notice that each human matches up with a similar stick. In keypoint detection, the computer attempts to identify those landmarks on each human.
How to get started with computer vision
We'll walk through each of these steps, with the goal being that at the end of the process you know the steps needed to solve a computer vision problem and get started on your first computer vision project.
1. Collect data for computer vision
In order to use data to solve a problem, you must gather data to do it! For computer vision, this data consists of pictures and/or videos. This can be as simple as taking pictures or videos on your phone, then uploading them to a service you can use. Roboflow allows you to easily create your own dataset by uploading directly from your computer.
2. Label and annotate computer vision data
While the goal is to get computers to see the way we as humans see, computers understand images very differently. Check out this (very pixelated) picture of Abraham Lincoln below. On the left, you just see the picture. In the middle, you see the picture with numbers inside each pixel.
Each number represents how light or dark a pixel is – the lighter the pixel, the higher the number. The right image is what the computer sees: the numbers corresponding to the colour of each pixel.
If your goal is to get your computer to understand what dogs look like, then the computer needs you to tell it which pixels correspond to a dog. This is where you label, or annotate, your image.
You should try to label as many images as you can, following best practices for labeling images.
3. Train a computer vision model
There are many different computer vision models that you can train.
Earlier, I used the example of you having a stack of 100 images that each contain either one cat or one dog. All "training" means is that our computer goes through those images over and over again, learning what it means for an image to have a dog or a cat in it. Hopefully we have enough images and the computer eventually learns enough so that it can see a picture of a dog it's never seen before, and recognize it as a dog.
4. Deploy a computer vision model
Training the model isn't quite the end – you probably want to use that model in the real world. In many cases the goal is to quickly generate predictions. In computer vision, we call that inference.
You might want to deploy to some program on your computer, or to AWS, or to something internal to your team.
Build the future with computer vision
Congratulations, you've just covered the basics of computer vision! You now know the various types of computer vision tasks, why to use them, and how to create your first computer vision project.
Cite this Post
Use the following entry to cite this post in your research:
Trevor Lynn. (Jan 29, 2025). What is Computer Vision? Comprehensive Guide [2026]. Roboflow Blog: https://blog.roboflow.com/intro-to-computer-vision/