
Semantic segmentation assigns a class label to every pixel in an image, going beyond bounding boxes to produce dense, pixel-level understanding of a scene. The post explains how the task works, including the use of one-hot encoded segmentation maps, and surveys the four major deep learning architectures built for it: Fully Convolutional Networks, U-Net, DeepLab, and PSPNet. Applications covered include autonomous driving perception and medical image analysis, where pixel-precise boundaries are required.
Semantic segmentation is a computer vision task that involves assigning each pixel in an image a label so that machines can recognize objects and their meanings. Semantic segmentation is commonly used for vision tasks that require absolute precision. This is in contrast to bounding box identification, which tells you the general region of an object but not to the pixel level.
This blog post serves as an introduction to the basics of semantic segmentation, offering insights into how it operates and examining various methods for its use.
What Is Semantic Segmentation?
Semantic segmentation is the process of partitioning an image into multiple segments and assigning semantic labels to each segment, thereby understanding the different objects and their boundaries within the image.
Semantic segmentation is like painting a picture where each color represents a different object or category. This technique enables computers to not only recognize objects but also understand their context within the image. Due to its comprehensive nature, this task is often termed as dense prediction, as it involves predicting labels for each individual pixel across the entire image.
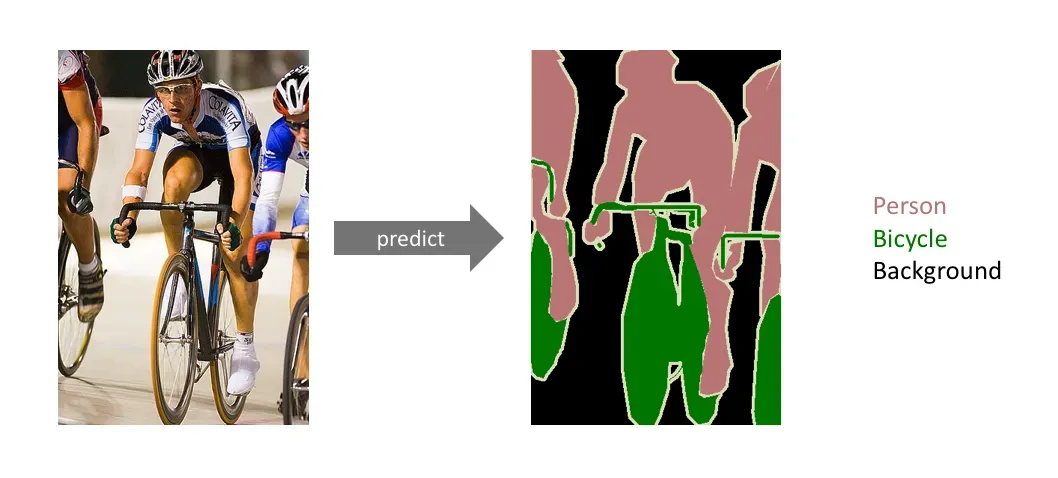
How Semantic Segmentation Works
The objective of a semantic segmentation model is to process either an RGB color image, sized (height x width x 3), or a grayscale image, sized (height x width x 1), and produce a segmentation map. In this map, each pixel is assigned a class label represented as an integer, forming a structure of (height x width x 3).
Here, we'll display the input image alongside its semantic labels. It's important to note that, for better visualization, we've labeled a prediction map with a lower resolution. However, in practice, the segmentation label resolution should align with that of the original input.

Similar to our treatment of standard categorical values, our target creation involves one-hot encoding of the class labels. This process essentially produces an output channel for each possible class.
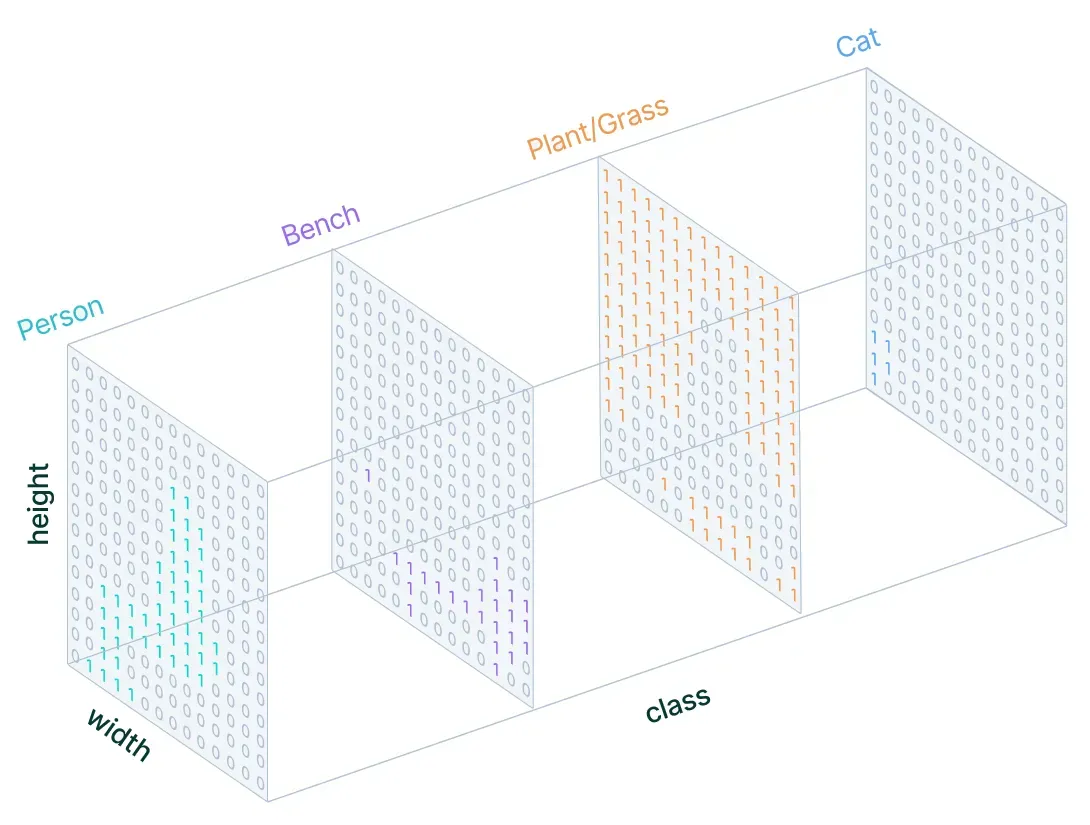
After defining the task's structure, we need to define an architecture tailored for this purpose. A straightforward method for constructing a neural network architecture for this task involves stacking multiple convolutional layers (employing the same padding to maintain dimensions) and generating a final segmentation map. This approach directly learns the mapping from the input image to its respective segmentation by progressively transforming feature mappings.
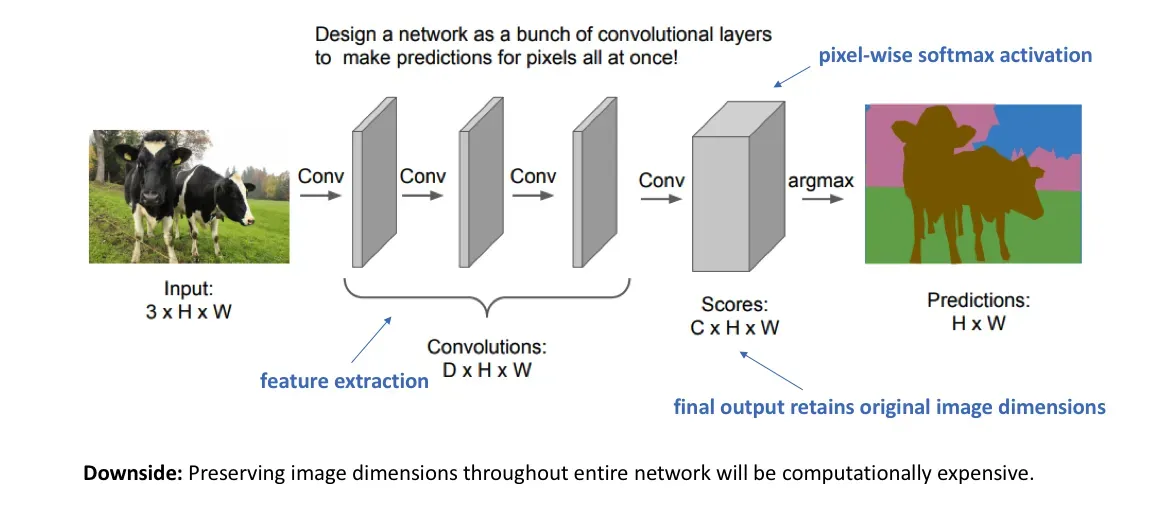
However, the preservation of full resolution across the network can lead to a substantial increase in computational overhead. Consequently, innovative specialized architectures have been developed to tackle this issue while maintaining optimal performance. These architectures introduce novel techniques and design principles aimed at efficiently handling high-resolution data throughout the segmentation process.
In the next section, we will discuss several prominent architectures that have emerged to address these challenges, providing insights into their unique features and advantages.
Common Semantic Segmentation Architectures
In the following section, we will discuss various semantic segmentation techniques that employ Convolutional Neural Networks (CNNs) as their fundamental architecture.
Fully Convolutional Network (FCN)
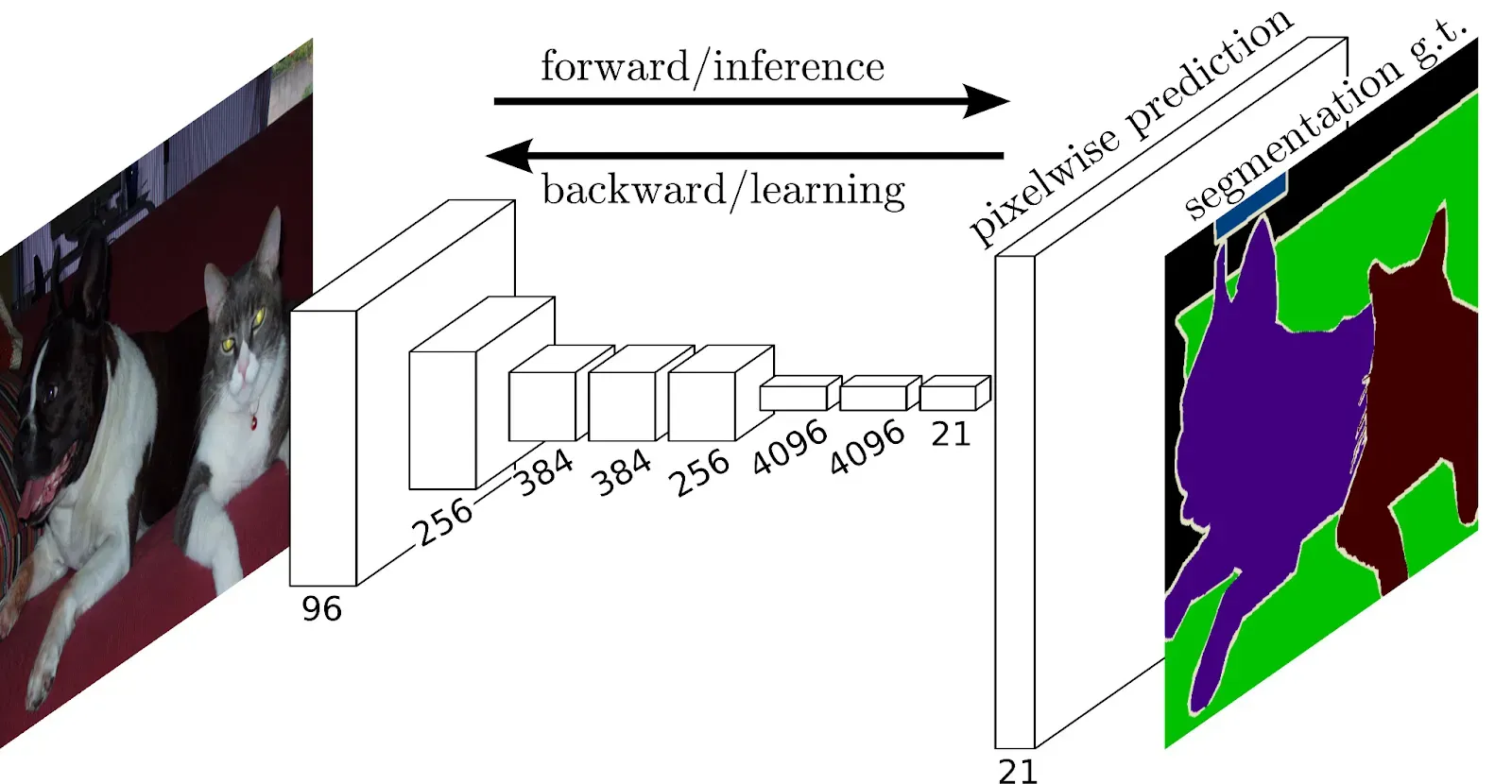
The Fully Convolutional Network (FCN) represents a significant advancement in the field of computer vision, particularly in tasks like semantic segmentation where a detailed understanding of images is crucial. What makes FCNs unique is their ability to process images of varying sizes without sacrificing the finer details.
Unlike traditional neural networks that focus on recognizing the general region where an object is present, FCNs dive deep into the intricate details of every pixel in an image. They achieve this by using layers specifically designed for understanding different features of the image, such as edges, shapes, and textures.
One of the key features of FCNs is their capacity to maintain the spatial information of the image throughout the network. This means that even after downsampling the image to extract features, FCNs have mechanisms to upsample the features back to the original resolution, ensuring that no details are lost in the process. Moreover, FCNs incorporate skip connections, which allow them to combine information from different parts of the image at various scales. This helps them grasp both local details and global context, resulting in more accurate segmentation.
U-Net
The U-Net architecture has garnered significant attention for its exceptional performance in semantic segmentation tasks. It derives its name from its distinctive U-shaped architecture, which features a contracting path followed by an expansive path, resembling the letter "U".
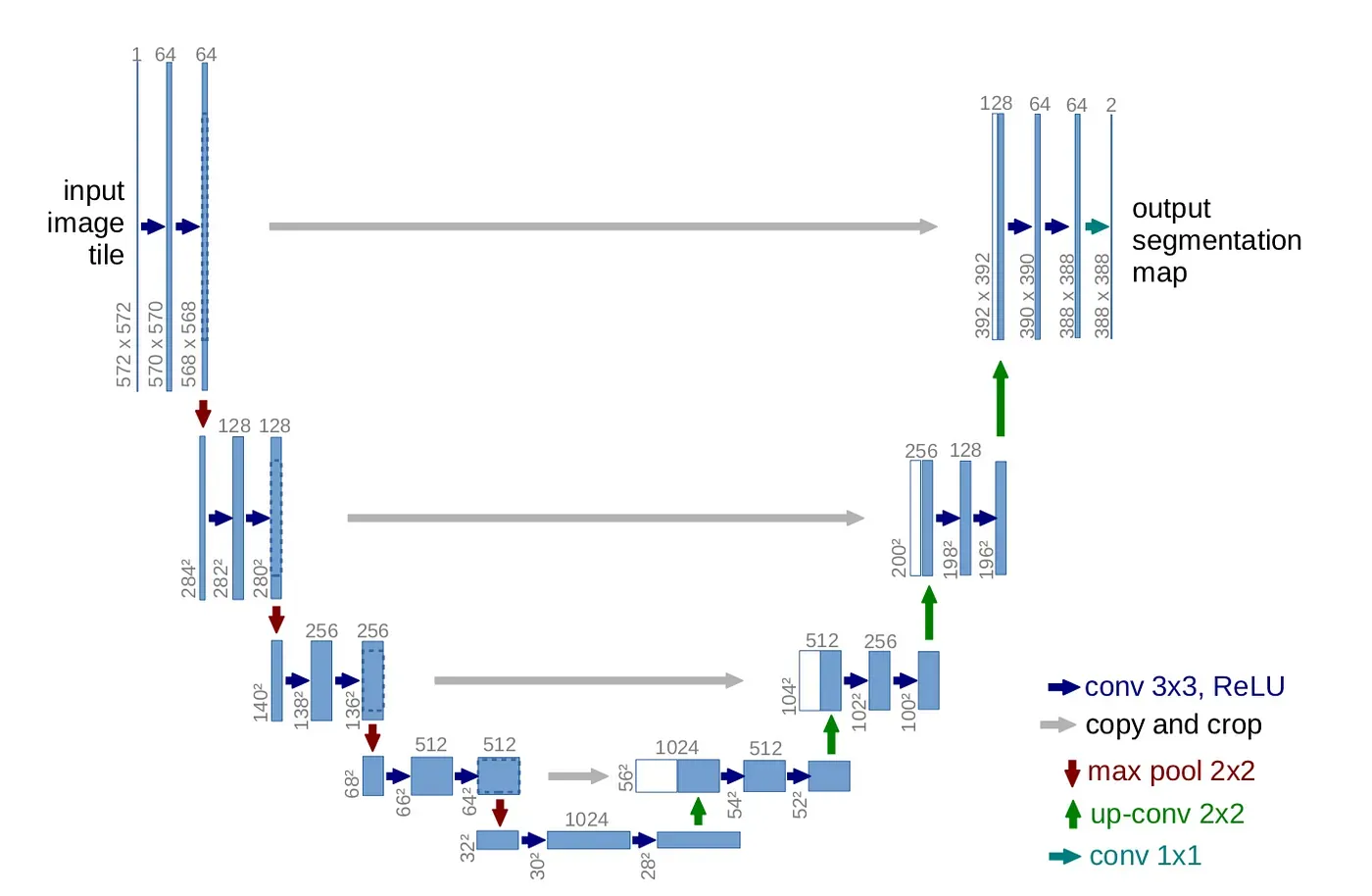
At the core of the U-Net architecture is its ability to capture both local details and global context effectively. The contracting path consists of convolutional layers interspersed with max-pooling operations, facilitating the extraction of high-level features and reducing the spatial dimensions of the input image.
This process helps in compressing the information and learning abstract representations of the input. Following the contracting path, the expansive path employs upsampling layers, such as transposed convolutions or interpolation techniques, to restore the spatial resolution of the feature maps.
Additionally, skip connections are introduced to connect corresponding layers between the contracting and expansive paths. These skip connections serve to fuse high-resolution features from the contracting path with the upsampled features, enabling the network to retain fine details while incorporating global context information.
One of the distinguishing features of the U-Net architecture is its symmetric design, which allows for seamless information flow between the contracting and expansive paths. This symmetrical structure ensures that the network can precisely localize objects in the image while maintaining spatial consistency. Furthermore, U-Net architecture is highly adaptable and can be tailored to different applications and datasets by adjusting its depth, width, and the number of feature maps in each layer. This flexibility makes it suitable for a wide range of semantic segmentation tasks across various domains.
DeepLab
DeepLab has gained widespread recognition for its ability to achieve highly accurate pixel-level predictions while efficiently handling high-resolution images. At the heart of DeepLab lies its innovative use of atrous convolution, also known as dilated convolution. Atrous convolution (or dilated convolution) allows the network to effectively enlarge the receptive field of convolutional filters without increasing the number of parameters, enabling it to capture contextual information across a broader region while maintaining computational efficiency.
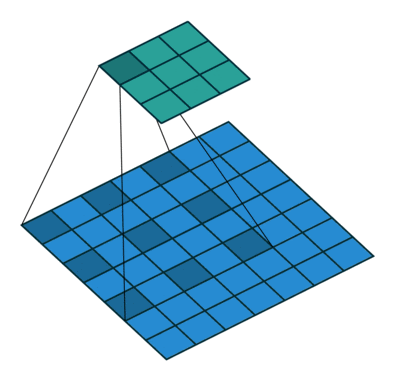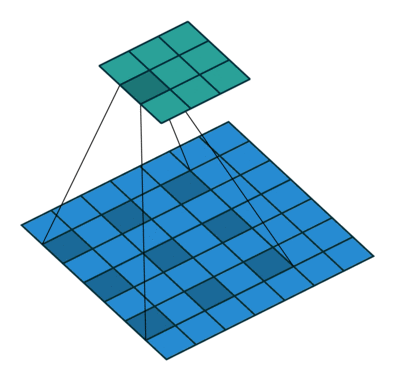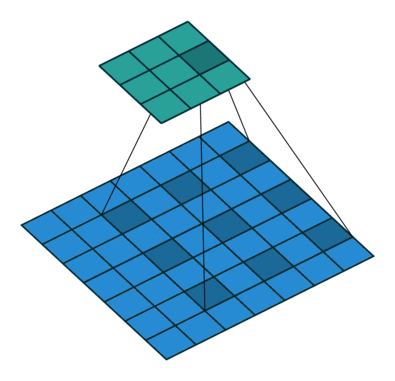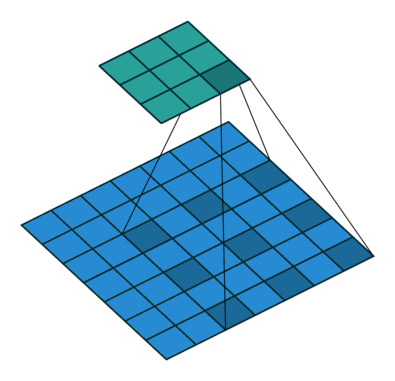
DeepLab employs a convolutional neural network backbone, such as ResNet or MobileNet, to extract rich feature representations from the input image. These features are then fed into the ASPP module, which consists of multiple parallel convolutional layers with different dilation rates. The ASPP module enables the network to capture multi-scale contextual information, allowing it to make more informed decisions about the class labels for each pixel.
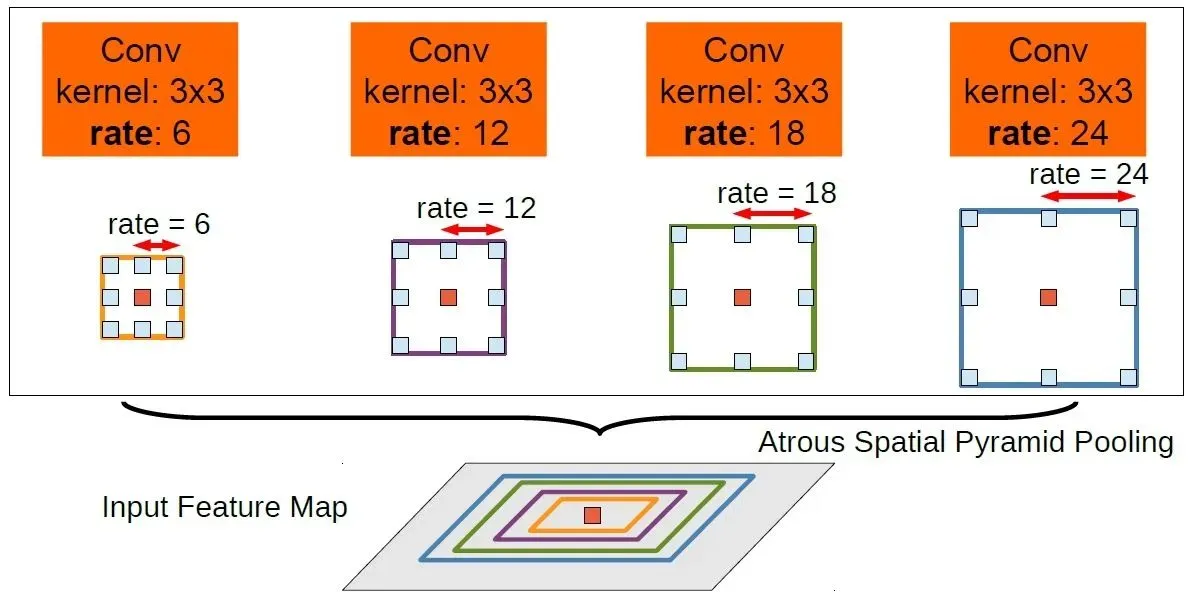
Furthermore, DeepLab incorporates post-processing techniques such as conditional random fields (CRFs) to refine the segmentation masks and improve the overall accuracy of the predictions.
CRFs help to enforce spatial consistency and smoothness in the segmentation output, reducing artifacts and enhancing the visual quality of the results. Another noteworthy aspect of DeepLab is its ability to handle images of arbitrary sizes through the use of fully convolutional operations. This makes it well-suited for real-world applications where images may vary in resolution.
Pyramid Scene Parsing Network (PSPNet)
The Pyramid Scene Parsing Network (PSPNet) is a cutting-edge deep learning architecture designed for semantic image segmentation tasks, particularly in complex scenes with diverse objects and backgrounds. PSPNet has garnered widespread acclaim for its exceptional performance in accurately parsing scenes while efficiently capturing contextual information at multiple scales.
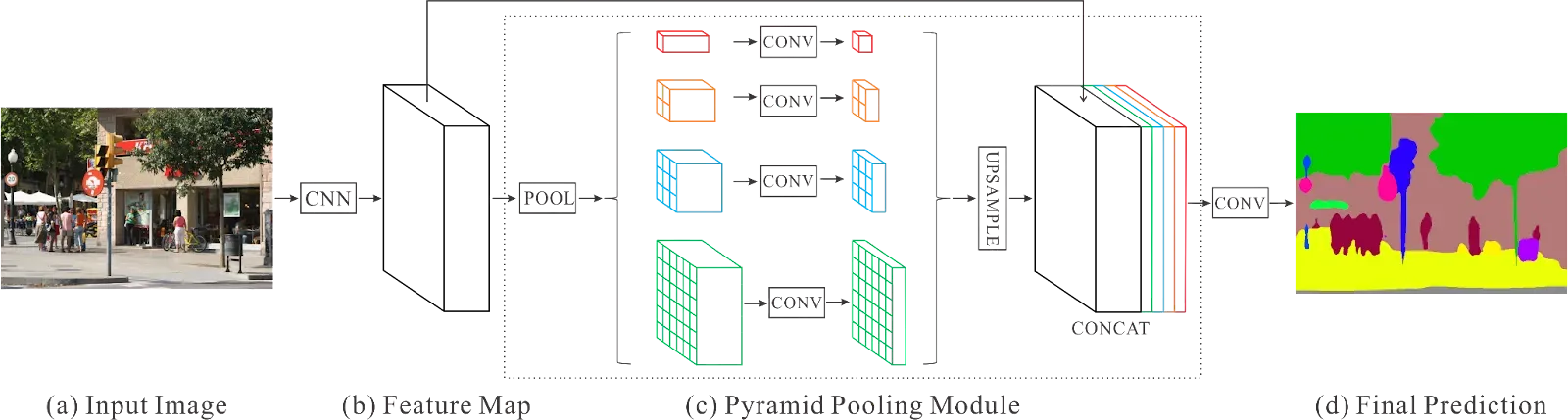
Central to PSPNet's success is its innovative pyramid pooling module, which enables the network to effectively capture multi-scale contextual information from the input image. The pyramid pooling module divides the feature maps into different regions of interest and aggregates features from each region at multiple scales.
This allows the network to incorporate both local details and global context, enabling more informed decisions about the class labels for each pixel. Moreover, PSPNet adopts a hierarchical structure that consists of multiple stages of feature extraction and refinement.
The network begins with a deep convolutional backbone, such as ResNet or VGGNet, which extracts rich feature representations from the input image. These features are then passed through a series of pyramid pooling modules, each operating at a different spatial scale, to capture contextual information at various levels of granularity.
Furthermore, PSPNet incorporates additional components such as atrous spatial pyramid pooling and spatial pyramid pooling (SPP) to further enhance its ability to capture multi-scale contextual information. These modules complement the pyramid pooling module by providing additional context at different resolutions, enabling the network to make more accurate predictions.
Semantic Segmentation in Computer Vision
To sum up, semantic segmentation lets us recognize different things in pictures by labeling each pixel. Deep learning methods, especially using modified neural networks like FCN, Unet, PSPNet, and DeepLab, make these algorithms accurate. These techniques are applied in various fields like self-driving cars and medical images showing their usefulness in real-world tasks.
Ready to try semantic segmentation? With Roboflow, you can label pixel-perfect masks, train custom segmentation models, and deploy them - all in one platform. Get started free with your first segmentation project today.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (May 30, 2025). What Is Semantic Segmentation In Computer Vision?. Roboflow Blog: https://blog.roboflow.com/what-is-semantic-segmentation/