
Keypoint detection is a computer vision task that locates specific landmark points on an object, most commonly body joints for human pose estimation but also hands, faces, and animals. Key model architectures include OpenPose, Keypoint-RCNN, CenterNet, and YOLO-based approaches, each with different tradeoffs in speed and accuracy. Applications span fitness tracking, sports analytics, augmented reality, autonomous vehicles, and robotics, anywhere a system needs to reason about the geometry or posture of an object.
Keypoint detection is a computer vision task that aims to identify the location of an object – often a person – and key points within the identified area (i.e. legs, arms, head). Keypoint detection is at the heart of many cutting-edge technologies, enabling applications from facial recognition in smartphones, assisting in object tracking for autonomous vehicles, or aiding in medical image analysis.
Imagine a world where your computer can not only see but also understand relationships between points in the visual world in a manner akin to the human eye. Keypoint detection is the key to this transformative vision, allowing computers to identify and pinpoint distinctive features in images. These keypoints serve as reference markers, making it possible for machines to make sense of the complex visual data they encounter.
This blog post will explore what keypoints are and how they are detected. We will delve into the various techniques and algorithms that make this possible and we will examine the real-world applications that rely on this technology.
What is Keypoint Detection?
Keypoint detection involves identifying specific, distinct points or locations within an image or frame in a video. These distinctive points, often referred to as “key points”, serve as landmarks or reference markers. These makers can be used by machines to analyze and interpret the visual content of an image.
For instance, consider a scenario where you are building an exercise application that lets people practice new yoga poses. You could use keypoint detection to identify various parts of the person using the application – their hips, legs, knees, elbows, arms – and apply logic to identify when the user successfully poses according to a visual prompt of a yoga pose.
There are a few sub-types of keypoint detection, which include:
- Human pose estimation: Identify key points associated with people.
- Hand pose estimation: Identify key points associated with human hands.
- Facial key points : Identify key points on human faces.
- Animal key points : Identify key points on animals (i.e. cats, fish).
You can use keypoint detection anywhere that you need to identify key points on an object. For instance, you could also use keypoint detection to monitor points on a robotic arm. You could use predictions from a keypoint detection model to check the arm is following instructions correctly.

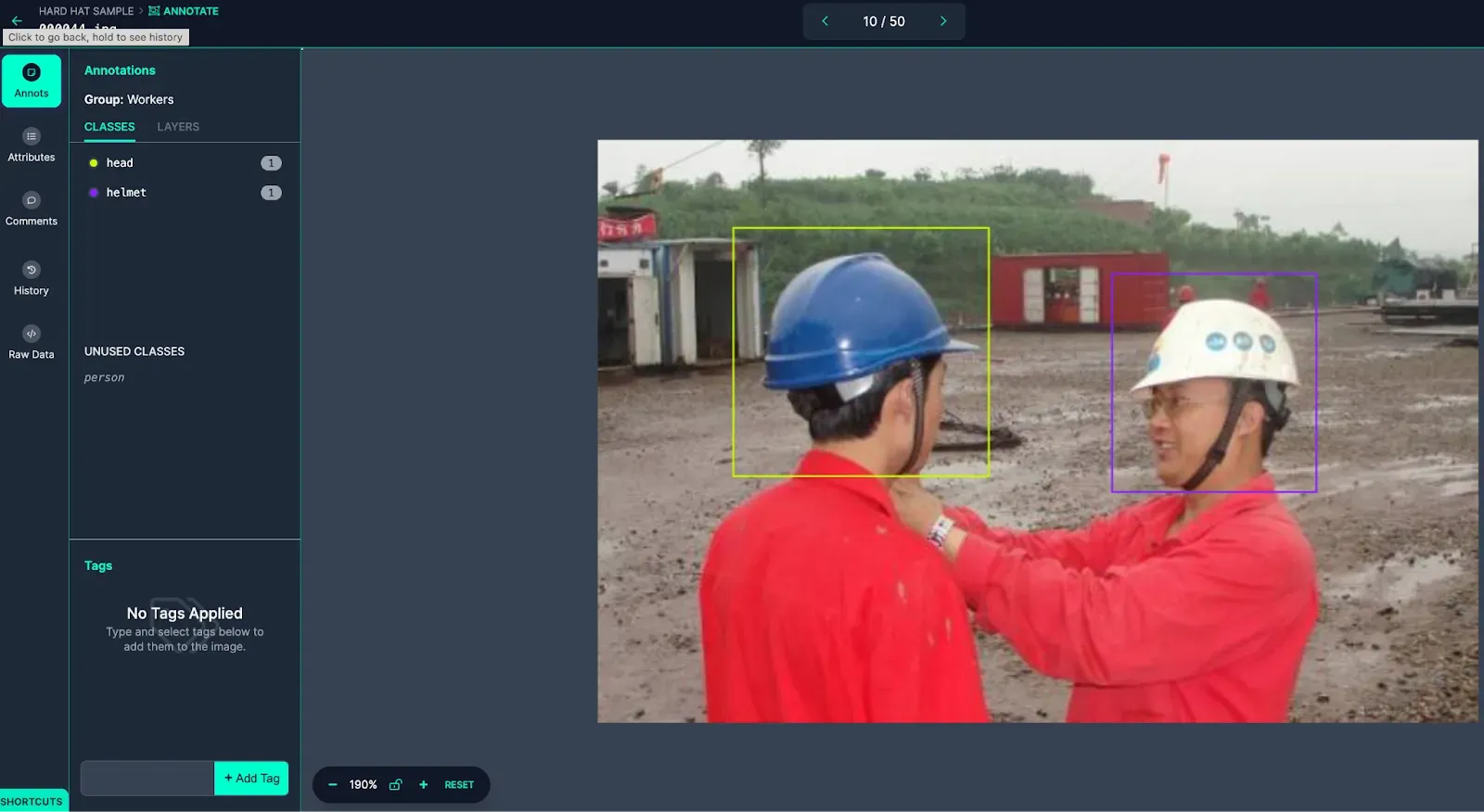
Example of two key points found (Tail and Head).
What Makes a Point a "Key Point"?
Key points are typically defined by certain characteristics that set them apart from the surrounding pixels. These characteristics include:
- Uniqueness: Key points should be unique and easily distinguishable from other points in the image. They stand out due to specific visual attributes, such as color, intensity, or texture.
- Invariance: Key points should exhibit a degree of invariance to common image transformations, such as rotation, scaling, and changes in lighting conditions. In other words, the same keypoint should be detectable in different versions of the same object or scene.
- Repeatability: Key points should be reliably detectable across different instances of the same object or scene. This repeatability is essential for various applications, including object recognition and tracking.
How to Detect Keypoints
The keypoint detection process is similar to that of any other computer vision process, but with one big difference: you need to annotate images with key points that you want to identify.
The process of keypoint detection typically consists of the following key steps:
- Data Preparation: Collect and annotate a dataset of images with key points.
- Model Selection and Training: Choose a deep learning architecture suitable for keypoint detection and train it on the annotated dataset. The model should learn to predict key points based on image input.
- Model Evaluation: Evaluate the model's performance using a separate validation dataset. Metrics like Mean Average Precision (mAP) or Euclidean distance error can be used to assess keypoint detection accuracy.
- Detection: Use the trained model for keypoint detection on new, unseen images. Provide the image as input to the model, and it will predict the key points.
Common Techniques and Algorithms for Keypoint Detection
Keypoint detection has evolved significantly with the advent of deep learning techniques. Deep learning models have demonstrated remarkable capabilities in various computer vision tasks, including keypoint detection.
Before the deep learning era, traditional methods like the Harris Corner Detector and SIFT were dominating the key points detection task. However, with the rise of deep learning, those methods have been discarded since deep learning architectures have given way to more powerful and data-driven approaches.
In this section, we will explore some popular keypoint detection deep learning techniques.
YOLO
While YOLO is primarily used for object detection, it can be adapted for keypoint detection tasks. To achieve this, you can add extra output layers in the network that predict keypoint coordinates. Each keypoint corresponds to a set of output channels in these layers.
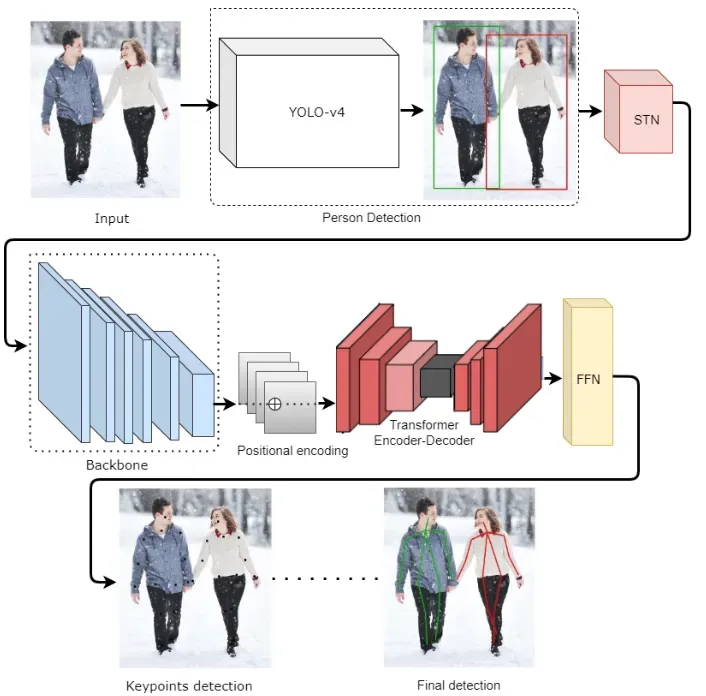
For instance, in PoseTED, YOLO-v4 is employed for human detection, resulting in the localization of individuals using bounding boxes. Subsequently, the Spatial Transformer Network (STN) is applied to extract regions of interest by cropping the original image based on the predicted bounding boxes.
The backbone network then processes these regions to generate comprehensive feature representations. The keypoint detection process, relative to the corresponding bounding boxes, is facilitated by a Transformer encoder-decoder with positional encoding. Ultimately, a prediction-based Feed-Forward Network (FFN) is utilized to predict key points and represent them as vectors corresponding to various body parts.
In addition, the Ultralytics YOLOv8 architecture has support for keypoint detection.
OpenPose
OpenPose, a computer vision framework, uses a convolutional neural network backbone to simultaneously detect multiple body parts, including joints, hands, feet, and the face, in input images or video frames.
By generating confidence maps and part affinity fields (PAFs), OpenPose captures the likelihood of body part presence and spatial relationships between parts. Post-processing techniques are then applied to identify key points and their connections, enabling the estimation and visualization of human poses.
The resulting keypoint coordinates find applications in gesture recognition, action recognition, fitness tracking, and other fields, making OpenPose a valuable tool for human pose estimation.
The general OpenPose pipeline is shown in the picture below:

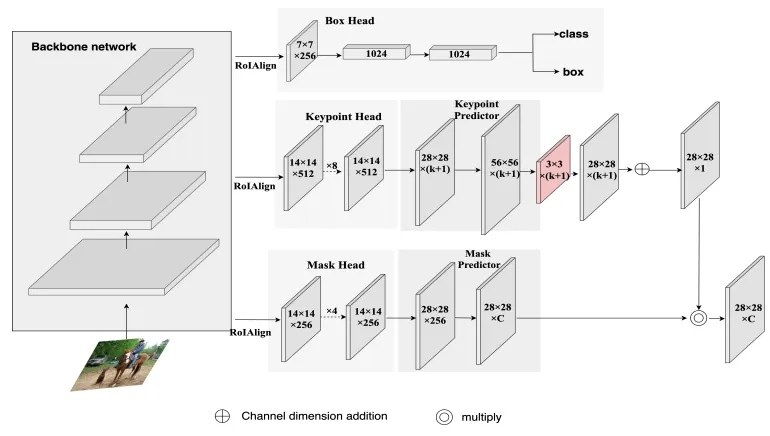
Keypoint-RCNN
Keypoint-RCNN is a keypoint detection framework that extends the Faster R-CNN object detection model. It first employs a Region Proposal Network (RPN) to generate region proposals and then fine-tunes these proposals using a CNN-based object detection head.
In addition to object bounding boxes, Keypoint-RCNN simultaneously predicts keypoint locations within each proposal, leveraging a keypoint head.
The model is trained using annotated datasets that include both object labels and keypoint annotations, and it employs a multi-task loss function to optimize both object detection and keypoint estimation. This enables Keypoint-RCNN to accurately locate and predict key points for objects within images, making it valuable for applications such as human pose estimation and object manipulation tasks.
The Keypoint-RCNN architecture is shown below:
CenterNet
CenterNet is an object detection framework that works by identifying object centers and their associated keypoint locations. It adopts a single-stage approach by predicting object center points as heatmaps and their size as regression values. Keypoint locations are simultaneously predicted within each object's bounding box.
By using a keypoint head, CenterNet can detect and estimate key points in a unified model. This architecture simplifies the object detection process, reduces computation, and has shown strong performance in tasks like human pose estimation and object detection, making it a versatile solution for various applications.
Applications of Keypoint Detection
Keypoint detection has a wide range of applications across various domains, enabling machines to understand and interact with the visual world. Here, we explore some of the diverse and impactful applications of keypoint detection:
- Object Recognition: Keypoint detection is crucial for object recognition tasks, as it allows machines to identify and differentiate objects by locating specific characteristic points. This is fundamental in robotics, where robots need to recognize objects in their environment for manipulation and navigation.
- Augmented Reality (AR): Augmented reality applications heavily rely on keypoint detection to align virtual objects with the real world. By identifying key features in the camera feed, AR systems can overlay digital information onto the physical environment, enhancing experiences in gaming, marketing, and navigation.
- Human Pose Estimation: Keypoint detection is crucial in human pose estimation, enabling the precise identification of key joints and body parts. This is vital for applications like fitness tracking, sports analytics, and gesture recognition systems.
Conclusion
In conclusion, keypoint detection is a powerful tool in computer vision, offering precise identification of crucial features in images.
While traditional methods paved the way, deep learning techniques like YOLO, OpenPose, Keypoint-RCNN, and CenterNet have revolutionized the field. These techniques find applications in diverse areas, from pose estimation to augmented reality.
With that said, keypoint detection continues to drive innovation, promising a dynamic future for computer vision applications.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Oct 31, 2023). What is Keypoint Detection?. Roboflow Blog: https://blog.roboflow.com/what-is-keypoint-detection/