1 Jul 2026 • 12 min read Fastest Object Detection Models in 2026 Compare the fastest object detection models. Learn how to test models in Roboflow Workflows and use local Inference profiling to choose the best model for your data.
24 Jun 2026 • 3 min read Roboflow and Standard Bots Partner to Bring Custom Visual Intelligence to Every Robot Roboflow and Standard Bots are announcing a partnership to enable robots to see, understand, and act with visual intelligence.
22 Jun 2026 • 4 min read Launch: RF-DETR Keypoint in Roboflow RF-DETR Keypoint beats YOLO26-pose on accuracy and speed, learns keypoint uncertainty, and is Apache 2.0. Label, train, and deploy in Roboflow.
18 Jun 2026 • 9 min read Off-the-Shelf vs. Custom Models for Industrial Computer Vision SUMMARY Use off-the-shelf models for rapid prototyping or when your task relies on detecting common, everyday objects that pre-trained models already recognize. However, to achieve the reliability required for specialized industrial production, you must deploy a custom, fine-tuned model trained specifically on your own domain'
10 Jun 2026 • 4 min read What Is YOLO27? YOLO27 brings 3D perception to YOLO with YOLO-Depth and YOLO-StereoDepth.
3 Jun 2026 • 12 min read Train a Computer Vision Model with Roboflow Train Discover how Roboflow Train automates computer vision model training. Eliminate infrastructure setup, leverage NAS, and deploy to production.
1 Jun 2026 • 9 min read How to Create a Synthetic Dataset for Computer Vision Accelerate computer vision model development by generating synthetic images. Learn to build an automated Stability AI pipeline in Roboflow.
28 May 2026 • 5 min read What Is YOLO-StereoDepth? YOLO-StereoDepth brings stereo depth for robotics to the YOLO family in September 2026. See what we know and how to read metric depth today.
27 May 2026 • 4 min read What Is YOLO-Anomaly? YOLO-Anomaly brings purpose-built anomaly detection for manufacturing QA. See what to expect.
27 May 2026 • 7 min read The Best Free Computer Vision Models The best free computer vision models, compared by task, speed, and license.
25 May 2026 • 4 min read What Is YOLO-VLM? YOLO-VLM pairs a lightweight YOLO front-end with a deeper LLM layer for efficient vision-language pipelines.
20 May 2026 • 4 min read Roboflow MCP: Build Vision Apps with Claude, Codex, and More The new Roboflow MCP Server connects Claude, Codex, and other AI agents to Roboflow so they can label visual data, train custom models, and build deployable vision pipelines.
18 May 2026 • 8 min read Download Pretrained YOLO Weights Pretrained YOLO weights give your model a head start by initializing from COCO, a benchmark dataset of 80 real-world object categories. This guide covers what pretrained weights are, how Roboflow uses them for custom training, and how to get started.
1 May 2026 • 11 min read What is Mean Average Precision (mAP) in Object Detection? What is mean average precision? How do we calculate mAP?
1 May 2026 • 13 min read How to Train a YOLO26 Oriented Bounding Box (OBB) Model Learn how to train a YOLO26 Oriented Bounding Boxes model with a dataset labeled on Roboflow.
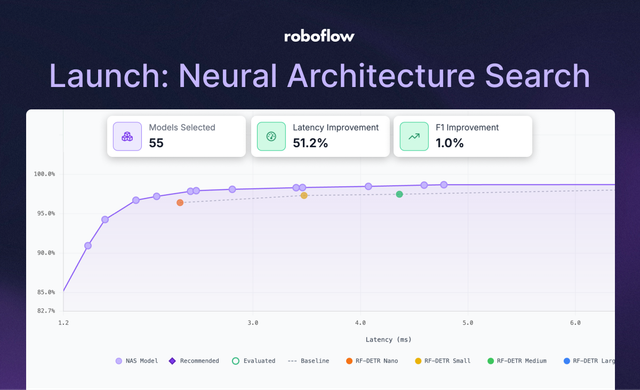
27 Apr 2026 • 5 min read Neural Architecture Search: Train the best vision model for your data Balancing inference speed and accuracy just got easier. Learn how Neural Architecture Search evaluates thousands of configurations simultaneously to deliver the highest-performing model for your target hardware.
6 Apr 2026 • 15 min read Best Pose Estimation Models Pose estimation is transforming how we understand human movement, powering everything from fitness tracking and sports analytics to healthcare rehabilitation. This guide explores the best pose estimation models, and shows how to deploy them efficiently across mobile, edge, and cloud environments.
2 Apr 2026 • 6 min read Using Videos as Training Data Turn video files into training data. Learn how to extract frames, set sampling rates, and use Roboflow to speed up computer vision labeling.
24 Mar 2026 • 4 min read How to Create a TFRecord File for Computer Vision and Object Detection How to create a TFRecord file for object detection: what it is, when you need it, and how to export one from a labeled dataset in Roboflow.
16 Mar 2026 • 25 min read Gemini 3 Guide: Master Google’s Deep Think Model in Roboflow Explore Gemini 3’s native multimodality and Deep Think reasoning. Learn how to deploy Gemini 3.1 Pro for object detection, OCR, and VQA using Roboflow Workflows and Playground.
11 Mar 2026 • 18 min read Training a TensorFlow Faster R-CNN Object Detection Model on a Custom Dataset Train a Faster R-CNN style detector on a custom dataset in your browser: no GPU, no code. Label, train RF-DETR, and deploy from cloud to edge.
11 Mar 2026 • 4 min read The Importance of Blur as an Image Augmentation Technique Learn about the efficacy of blur as an image augmentation step in computer vision model training.
2 Mar 2026 • 7 min read How to Train YOLOv4 on a Custom Dataset Want to train YOLOv4? Train a custom object detector without Darknet, a config file, or a GPU: Learn how with Roboflow.
2 Mar 2026 • 10 min read How to Train an EfficientDet Object Detection Model with a Custom Dataset Learn how to train an EfficientDet object detection model with a custom dataset.