
Class imbalance causes models to underperform on minority classes because the training distribution does not reflect the real-world distribution of what matters. Five strategies address this: gathering more data from underrepresented classes, generating synthetic samples through augmentation, undersampling the majority class via random selection, oversampling the minority class via bootstrapping, and reweighing loss so minority examples contribute more to gradient updates. Each method carries tradeoffs on the bias-variance spectrum, and all should be applied only to training data, not validation or test sets.
Dealing with unbalance classes is a common challenge that can significantly impact the performance of your models. When one class dominates the dataset algorithms become biased, leading to inaccurate predictions. Suppose you're trying to teach an alien – like one of the crew mates from the wildly popular game Among Us – to tell the difference between a human and a dog.

What you might do is show the alien 100 pictures of a human and 100 pictures of a dog. Hopefully, the alien picks up on patterns of humans (taller, stands on two legs, opposable thumbs) and of what makes a dog (shorter, stands on four legs, paws with no opposable thumbs, tail, usually much cuter).
If you've done your job, the alien should be able to look at a picture it's never seen before, and recognize the image contains either a human or a dog.

Suppose you're trying this again with a new alien, but with you show 100 pictures of dogs and only 3 pictures of humans. Afterward, if this alien is presented with an image of a human, it may not know enough about what humans look like to accurately guess "human."
Which alien will have the harder time – the first, or the second?
This is a great analogy for how a classification model performs. Generally speaking, classification models tend to perform better when classes are balanced – that is, there's roughly the same number of samples in each class.
Practically speaking, there are a lot of scenarios in which classes are likely to be unbalanced (also called imbalanced). It's probably easier to get pictures of dogs than it is pictures of bald eagles, so an animal image dataset is likely to naturally have more dogs than bald eagles. This isn't limited to images!
- If you're running a website that sells something, it's unlikely that exactly 50% of people who go to your website will purchase an item.
- If you're surveying who voters support for an upcoming election, some candidates may have very low support, causing unbalanced classes. In the United States, for example, most votes are cast for Democratic and Republican candidates, whereas Green and Libertarian Party candidates usually get much less support.
- If you're studying a rare event – like whether or not a deadly tsunami occurs on a given day – you'll notice that about 99% of your observations fall into one bucket.
Whenever you are doing a classification problem, it is strongly encouraged that you check your class distribution!
Roboflow has developed a dataset health check that makes this easier. In the below image, the class balance for this public breast cancer dataset shows that red blood cells (RBC) are significantly overrepresented, whereas white blood cells (WBC) and platelets are significantly underrepresented. (Important side note: this dataset is actually intended to be used for object detection. Object detection problems are different from, but related to, image classification problems. If you want to learn more about their difference, check out our introduction to computer vision.)
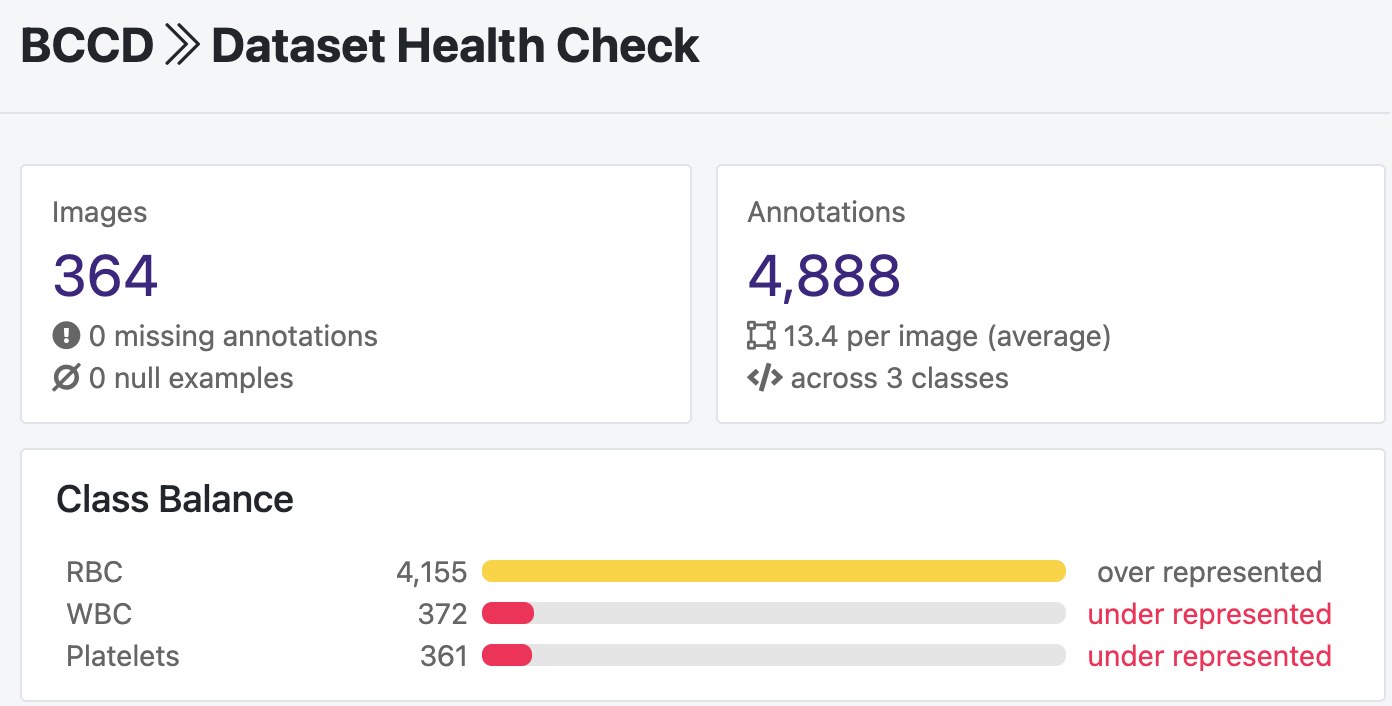
There are many real-world examples involving unbalanced classes. If you're looking to fit a machine learning model to that data, you may find that your model doesn't perform well. We need strategies to address this!
In this post, we'll describe why unbalanced classes are an issue and we'll cover five strategies for handling unbalanced classes in your data. In most cases, the goal is to turn our unbalanced classes into balanced ones – only in our training data.
Explore Strategies for Handling Unbalanced Classes
1. Gather More Data
Ideally – just gather more data! Going back to the dog/human example from earlier, if you have 100 images of dogs and 3 images of humans, your model will probably perform better if you can get 1,000 images of dogs and 30 images of humans. Even though that doesn't change how the classes are distributed, we are increasing our sample size. (Once you gather more data, you might try labeling your data in Roboflow!)
You might also try gathering more data that just focus on the minority class(es) – in this case, set out to gather data on humans. There is a significant downside to this approach, though: gathering more data is often time- and money-intensive. While this is a good approach in theory, the practical limitations often lead us to other strategies.
2. Synthetic Augmentation
Synthetic augmentation artificially increases our sample size by generating new data. (At first glance, this may feel unethical – creating new data – but it's based on existing data, not made up out of thin air!) We'll discuss two clever approaches for generating data: image augmentation and SMOTE.
- With images, we can use image augmentation. Imagine you take a picture of a dog for our dog/human dataset. If you happened to take a small step forward, or a step backward, or to the side, or a cloud caused the image to be a bit darker, these resulting pictures would also be of the same dog. We can simulate these types of conditions with image augmentation! By adding rotation or brightness or a bit of noise, we can improve how well our model generalizes to new data. If you generate new data, be sure to note that it's not exactly new. Since it's based on existing data, it's by definition correlated with your existing images. You can't generate a million data points and expect your model to perform as well as if there actually were a million unique data points that you originally gathered. Still, image augmentation can pretty easily address even substantial class imbalance.
- With standard tabular data, we might use SMOTE, or Synthetic Minority Oversampling Technique. Imagine a two-dimensional plot of dots, where many dots are blue and a handful of dots are orange. SMOTE takes examples in the orange class, then creates new ones in the same region. You can imagine this like adding new orange dots in a random pattern around where the existing orange dots are. (This is an oversimplified version, but illustrates what SMOTE is doing.)
3. Undersampling via Random Selection
In the dog/human example with 100 dog images and 3 human images, we can balance our data by undersampling the majority class. This means we take a random sample of our 100 dog images and use those in our data. If our goal is to perfectly balance the classes we take a random sample of 3 dog images so that we have 3 dogs and 3 humans. Surely, you can see how this tactic may not work well – our sample size has gone from 103 down to 6! This is a recommended technique if you have lots of data, but not when you're working with low sample sizes.
4. Oversampling via Bootstrapping
In the dog/human example with 100 dog images and 3 human images, we can also balance our data by oversampling the minority class. This involves bootstrapping, or resampling with replacement. (This means when you take a sample of size N, you pull one observation, record it, replace it in the full sample, then pull another observation, record it, and so on until you have your sample of size N.)
If we wanted to balance our data by oversampling, we need to generate 97 additional human images. So we would pull one of our existing human images, make a copy, then put that existing human image back, and repeat 96 more times. If our goal is to perfectly balance the classes, we now have 100 dogs and 100 humans. Each of the 100 humans is a copy of the 3 original human images we had at the beginning. There's a limit to what you can do – here we see that we're making a lot of copies of the same handful of images – but hopefully you have more than a sample size of 3 in your classes. In most cases, your underrepresented classes won't be quite so sparse. You can also try using oversampling and undersampling simultaneously if using one approach isn't sufficient.
5. Reweighing
Reweighing is closely related to oversampling and undersampling – and is a specific case of applying both techniques. Balancing your classes can be thought of giving each class an "equal vote." Thinking back to the dog/human example with 100 dog images and 3 human images, if the goal is to give dogs and humans an "equal vote" or "equal say" in your model, then we could give each dog 1 vote and give each human 33.3 votes. This means that each class has 100 votes. Lots of software packages allow for weighing – Python's scikit-learn package has a class_weight parameter that allows you to fit machine learning models that weigh each observation to a value of your specification and R's weights package allows you to conduct hypothesis tests and calculate statistical summaries with weighted observations. This is very common in surveys and polling – if you conduct a political poll and get a sample that is significantly younger or significantly more educated than the voting population, you may want to reweigh the results of your poll based on age and/or education to better match the electorate. Reweighing tends to decrease your model's bias at the risk of increasing your model's variance. Be wary of the bias-variance tradeoff; reweighing is not a silver bullet!
IMPORTANT: Only apply these techniques to your training data!
When you apply any of these 5 strategies to address your unbalanced classes, be sure to only apply these to your training data! When you evaluate your model on validation and testing data, your goal is to get an unbiased estimate of how your model will perform in the "real world." If you apply these strategies to your validation or testing data, those data no longer reflect the actual real world! (We've written about a closely related issue, underspecification, here.)
Techniques to Handle Imbalanced Data
These are strategies for handling unbalanced classes. None of them are perfect – and it's important to know the limitations before applying any of these methods. Of course, we can't generate something from nothing, and there are lots of examples of naturally occurring unbalanced classes! Hopefully you're now aware of why unbalanced classes are an issue, and of five strategies for tackling unbalanced classes.
Cite this Post
Use the following entry to cite this post in your research:
Matt Brems. (Jan 3, 2025). 5 Strategies for Handling Unbalanced Classes in Machine Learning. Roboflow Blog: https://blog.roboflow.com/handling-unbalanced-classes/