
Adding noise to images is a data augmentation that makes a computer vision model more robust by training it on slightly corrupted versions of your data. It teaches the model to ignore small pixel-level imperfections instead of latching onto them. This guide covers what noise is, why it helps, when to use it (and when not to), the common types, and how to add noise to a dataset in Roboflow.
We seek to build computer vision models that generalize to as many real world situations as we can, even when we cannot anticipate them. It's a bit of a catch-22: build deep learning models that predict a world that you may have not anticipated.
But that's what is at the crux of preventing overfitting. Unintentionally, we build models that best predict our training data, but not the real world (or the test set).
Thus, deliberately introducing noise is one way to help hold our models accountable. We seek to have them learn the patterns of the training data – not memorize. The difference is subtle. But models (including convolutional neural networks) are far more brittle than humans are in their ability to reason, so simple perturbations in data can yield serious unintended consequences.
What Is Image Noise? Why Care?
Noise is deliberately altering pixels to be different than what they may should have represented. Old-fashioned films are famous for having speckles black and white pixels present where they should not be. This is noise!
Noise is one kind of imperfection that can be particularly frustrating for machines versus human understanding. While humans can easily ignore noise (or fit it within appropriate context), algorithms struggle. This is the root of so-called adversarial attacks where small, human-imperceptible pixel changes can dramatically alter a neural network's ability to make an accurate prediction.
Researchers from Arizona State University considered the impact various image imperfections have on classification models. Of the the methods tested, blurring and noise had the most adverse effect on top-1 and top-5 accuracy classification.
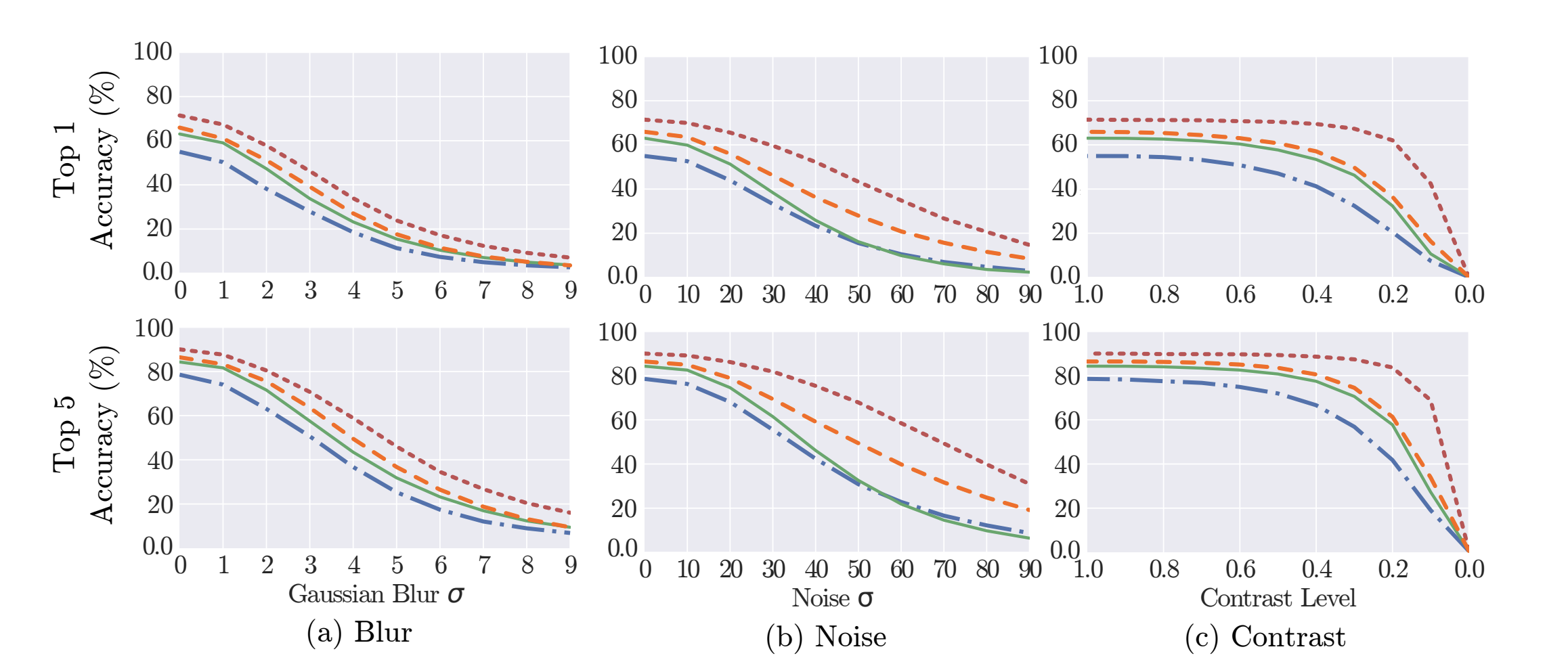
While other imperfections like JPEG compression and contrast took their toll only when significantly increased, noise and gaussian blurring showed near immediate smoothing on tested models (VGG16, GoogleNet, VGG-CNN-S, Caffe Reference).
When to Use Noise
So, when should we make noise?
There are two ways to apply an image transform. Preprocessing is applied to every image, training, validation, test, and inference. Augmentation is applied only to the training set to add strategic variation.
Noise is best used as an augmentation. You want to increase variability in training so the model learns to shrug off corruption and resist overfitting, but you do not want noise in your validation and test sets, because those should reflect clean, real evaluation conditions. Adding noise everywhere would just measure your model on artificially degraded images.
When Not to Add Noise
There are cases to go light or skip noise:
- Already-clean, controlled capture. If your production images come from a fixed, high-quality camera in steady lighting, heavy synthetic noise teaches variation the model will never see.
- Tiny or fine-detail targets. For small defects, thin cracks, or text in OCR, aggressive noise can obscure the very signal you need the model to read. Use a low amount, if any.
- Too much of it. Past a point, noise stops helping and starts erasing real features. Vary the amount and keep it modest.
Match the augmentation to the imperfections your model will actually encounter. If your cameras produce sensor noise in low light, training with noise is realistic and useful. If they never do, spend the budget elsewhere.
Types of Image Noise
Several kinds of noise show up in image processing:
- Salt-and-pepper. Randomly flips some pixels to pure white or pure black. The most common choice for this kind of augmentation.
- Salt. Adds only white pixels.
- Pepper. Adds only black pixels.
- Gaussian. Adds random variation drawn from a normal distribution, closer to real sensor noise.
- Speckle. Adds noise uniformly across the image.
A good default is to replace a small share of pixels, often around 5 percent, and to vary the amount per image so the whole set does not get the same treatment.

How to Add Image Noise in Roboflow
You can add noise to a whole dataset without writing code:
- Open your project and create a dataset version under the Versions tab.
- Add the noise augmentation. Set the maximum share of pixels that any image may have replaced with noise. Each image then receives between zero and that maximum, sampled from a uniform distribution, so the variation is spread across the set rather than applied identically.
- Generate the version. Noise is applied only to the training set, and Roboflow records how each image was varied so you can trace which level of noise helps or hurts.
Applying augmentation at version-generation time, rather than during training, keeps your runs reproducible and faster.
Best practices
- Vary the amount per image instead of applying a single fixed level.
- Keep validation and test sets clean so evaluation reflects real conditions.
- Combine augmentations thoughtfully. Noise pairs with brightness and blur, but stacking everything at once can drift your data away from reality.
- Tie the noise type and amount to your real sensors. Gaussian for sensor-like grain, salt-and-pepper for dropout-style artifacts.
Does adding noise improve accuracy?
It often helps when your real images can be noisy, because the model becomes robust to that corruption. As with any augmentation, validate the change against a clean test set rather than assuming it helps.
What is the difference between salt-and-pepper and Gaussian noise?
Salt-and-pepper flips random pixels to pure black or white, simulating dropout-style artifacts. Gaussian noise adds smooth random variation drawn from a normal distribution, which is closer to real camera sensor noise.
Should I add noise to my validation and test sets?
No. Apply noise only to the training set. Validation and test images should stay clean so your metrics reflect real performance.
Get Started
Add noise and other augmentations to your dataset in Roboflow, generate a version, and train a model such as RF-DETR on the result. For the full set of options and when to reach for each, see our guide to data augmentation, and to grow a small dataset further, see synthetic augmentation with SAM 3. Happy building!
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Mar 9, 2026). Why to Add Noise to Images for Machine Learning. Roboflow Blog: https://blog.roboflow.com/why-to-add-noise-to-images-for-machine-learning/