
A model that hits strong accuracy or mAP scores during training can still fail in deployment because many different models can fit the same training data equally well, a problem called underspecification. A 60-page Google paper documents this gap and outlines practical countermeasures: stress-testing models against distribution shifts, using ensemble disagreement to surface instability, running sensitivity analysis on inputs, auditing intentional and implicit modeling choices, and keeping pipelines reproducible enough to trace when real-world performance diverges.
We read the 60-page Google underspecification paper (so you don't have to). Want to jump straight to the tips? Click here.
Here's a problem you've probably had: You build a model with a great accuracy score or a really high mAP (mean average precision).
Then, you deploy your model... and your model does worse than expected.
You took the right steps! You split your data into training, validation, and testing sets. You checked to make sure there weren't errors importing your data and thoroughly cleaned your data. Your feature engineering steps were rooted in subject-matter expertise.
What's happening?
Your model did well when you built it, but it's doing worse now that you've deployed it. One main cause of this phenomenon is called underspecification. A team of (mostly Google) researchers published a paper earlier this week about machine learning models performing poorly when they're "deployed in real-world domains" and how underspecification causes this.
What is underspecification?
Chances are, when you build your model, there are a lot of models that perform well on your data. This is underspecification.
Let's start with a simple example, then dive into a more real-world one: Take this scatterplot of data. You want to generate a line of best fit to this data.
There are a lot of lines that could do pretty well on this data. Let's look at two example lines:
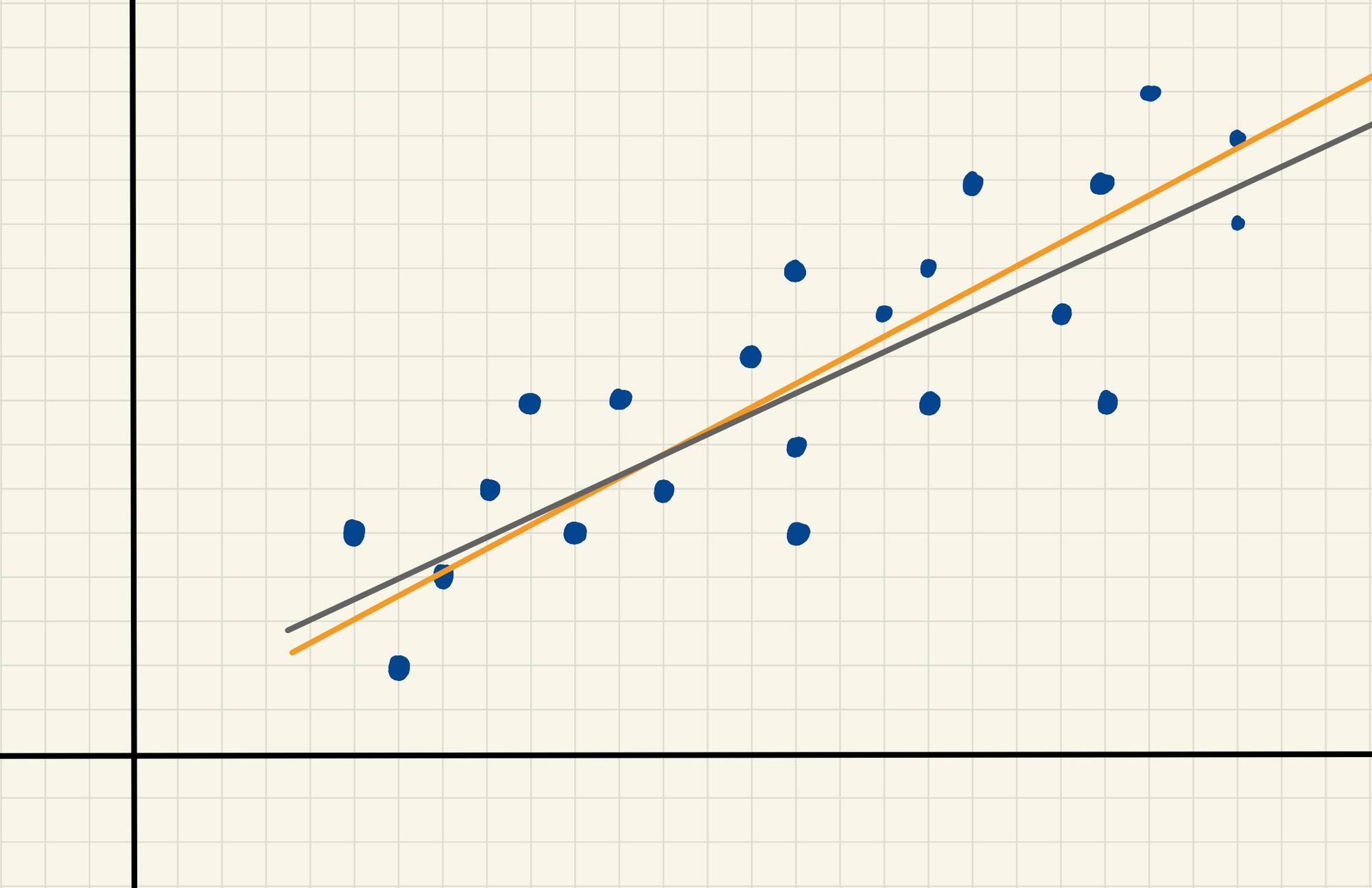
The orange and silver lines in this image are pretty similar to one another. When we quantify model performance, both are probably going to do pretty well. The computer will easily pick the "best" one – but the one that the computer calls "best" isn't guaranteed to be "the best one in the real world."
This is underspecification. A machine learning pipeline is underspecified if there are many different ways to get your model to realize the same performance on the held-out test set – even if you have the same training data and same model structure. In the above example, the training data (dots) and the model structure (simple line of best fit model) are the same, but the slopes and y-intercepts of the lines are a bit different. Despite these being two different lines, if they both get about the same level of performance on our test data, we'd describe this as underspecified.
The line of best fit is an intuitive example (different slopes, but similar performance) – but this is a problem with all sorts of machine learning models, including in computer vision, natural language processing, and more. It's just sometimes harder to detect in those models.
What's the big deal? Why is underspecification a problem?
Those two lines we saw earlier? Our computer picked the "best" one based on some measure of model performance. But the computer doesn't know which model is a better reflection of reality – just which model happened to be better on this specific set of data.
Let's say that, instead of fitting a line of best fit model, you're tackling an object detection problem with RF-DETR. (Aside: Learn how to train an RF-DETR model here.)
There are a lot of intentional and unintentional choices that go into fitting an object detection model.
- Intentional choices might include the types of image preprocessing you do or the amount of data you collect.
- Unintentional choices might include the random seed that is selected when fitting your model or the algorithm that fits your model to the data.
If we try fitting 20 different models, perhaps 5 of them perform pretty well. Among those 5 good models, our computer doesn't take any real-world meaning into account when selecting the "best" model.
At the end of the day, a model is a simplification of reality. Models are generally supposed to reflect or mimic the real world. But the way that models are fit, there's no guarantee that your computer selects a model that reflects the logic or science of your specific application.
Surprisingly, seemingly irrelevant decisions like your random seed may have a really big impact on your model performance!
You might think this doesn't happen a lot. Google research says otherwise. Your computer may select the "best" model – but it turns out, which model is "best" is shockingly dependent on small, seemingly arbitrary choices.
What this means: When you deploy your very accurate, high-performing-on-the-test-set model, there's a good chance your model immediately starts performing poorly in the real world, costing you time, money, and frustration.
What are 5 things we can do to avoid those negative consequences?
- Draw your testing data from somewhere other than the training distribution – ideally mirroring your deployment environment. When you gather data and randomly split it into training, validation, and testing sets, you may be setting yourself up for failure. Even though there isn't model leakage, your testing data that is used to evaluate your model comes from the exact same place as your training/validation data. If you can gather two separate sets of data (one for training/validation and a separate one for testing), you may better be able to mimic how your model will do in the real world. In a time series context, that's like using the most recent data as your testing data. In a computer vision context, if you're evaluating environmental health by counting fish, you might train your object detection model on data from one river, and test your model on data from another river.
- Minimize the gap between your training data distribution and the "real world" distribution. If you must draw your testing data from the training distribution (e.g. randomly splitting your data into training/validation/testing sets), consider perturbing your data so that the information in your testing set better mirrors the real world. In computer vision, this usually includes image augmentation techniques.
- Detect underspecification by running stress tests. Stress tests are common – for example, banks have to run stress tests to ensure that they can withstand surprising economic events. Researchers from Google used stress tests by running models under a variety of random seed values, then checked to see how the stress tests varied. Ideally, there's little to no variability observed based on the random seed; the research shows that random seeds did substantially affect stress test performance. The researchers share three types of stress tests that they use: A) Stratified Performance Evaluations, where evaluations are done for subgroups of observations to identify inequities. For example, calculating mean average precision among each class separately. B) Shifted Performance Evaluations, which generates a made up test distribution by intentionally perturbing existing data to check specific properties of the model. C) Contrastive Evaluations, which are similar to sensitivity analysis in that one input observation is manipulated to measure how significantly the output is affected.
- Identify the intentional and unintentional modeling choices you are making. If you detect or have reason to suspect that your model is suffering from underspecification, then start attempting to address it by making a list of all of your modeling choices. Some are intentional, like the inputs to your model and the type of model you select. Some are unintentional or implicit, like the random seed or the step size in a neural network. If your model is suffering from underspecification, see if tweaking these can improve your model's real world performance!
- Make sure your machine learning pipeline is reproducible. When evaluating your model on the training/validation/test sets and in the real world, it is critical to keep track of when your model performs well and when it doesn't. Identifying when model shift begins to occur or what parameter settings (the ones you hopefully listed in step 4 above!) generated the model that performs particularly well in the real world are key to ensuring that your model development is focused on achieving strong real-world performance.
Cite this Post
Use the following entry to cite this post in your research:
Matt Brems. (Nov 16, 2020). Google Researchers Say Underspecification is Ruining Your Model Performance. Here's Five Ways to Fix That.. Roboflow Blog: https://blog.roboflow.com/google-paper-underspecification-machine-learning/