
How do you know when your computer vision model is ready for production? Metrics such as mAP provide an insight into the overall performance of your model, but there are many lenses through which you can evaluate a model to know whether it is ready for production.
Roboflow now features a model evaluation tool, available to all paid customers, that lets you analyze confusion matrices for object detection models hosted on Roboflow. These matrices are generated by comparing ground truth from your dataset – your annotations – to predictions from your model. This adds to our existing features allowing you to view accuracy, recall, and mAP for your models, and our interactive web tool for running inference on images and videos.
By analyzing a model confusion matrix, you can identify issues in your model before going to production and take less guesswork out of the question “is my model ready for production?”
In this guide, we are going to demonstrate how to evaluate computer vision models on Roboflow. Without further ado, let’s get started!
How to Analyze Model Evaluations
In this section, we are going to evaluate the performance of a retail cooler model. This model detects the number of empty spaces on drinks shelves, useful in retail scenarios for ensuring shelves are fully stocked.
After you train a model, a model evaluation will be scheduled. This is only available for customers on a paid Roboflow tier. This evaluation may take a while depending on how many images are in your dataset. Evaluations are triggered for all new models trained on Roboflow; models trained before today will not have evaluations.
Once evaluation is complete, a “View Detailed Model Evaluation” button will appear on the Versions page associated with your model:
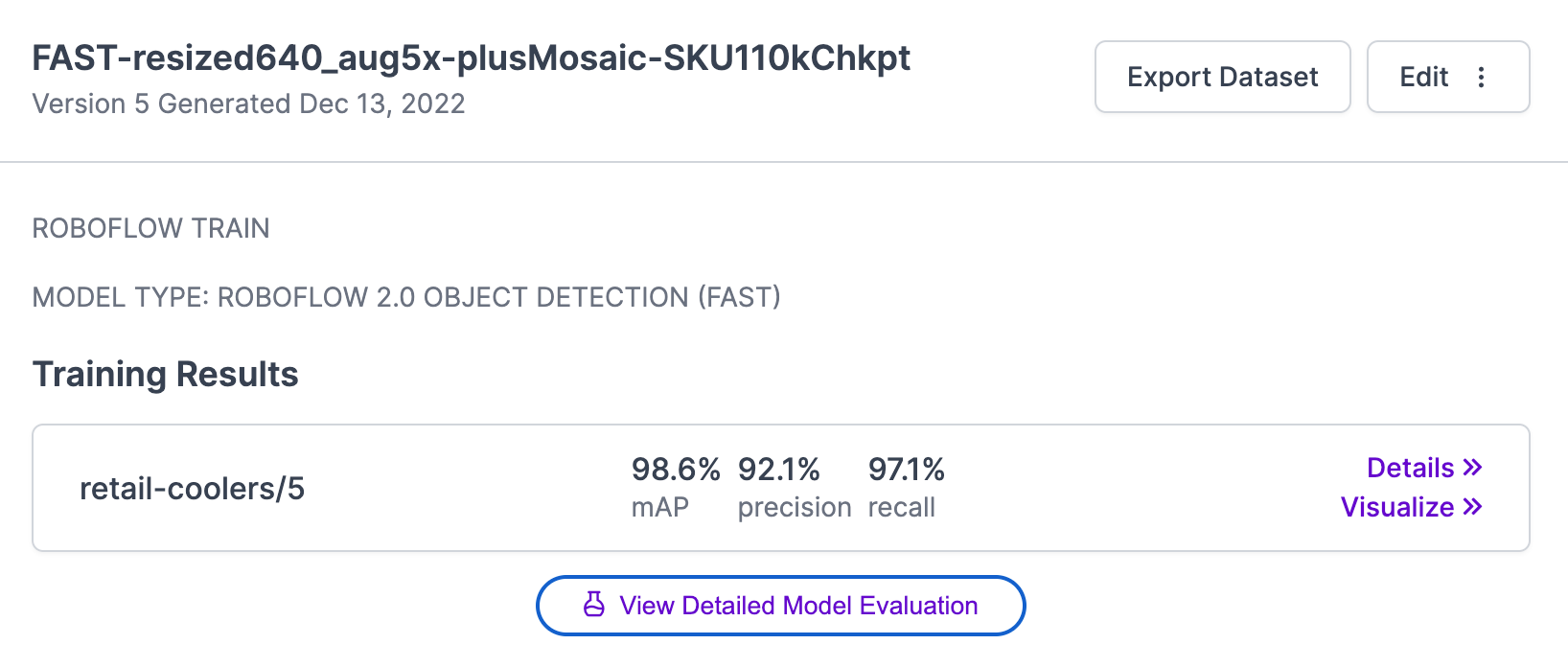
When you click this button, a confusion matrix will appear showing performance of your model. Here is the confusion matrix for our retail cooler model:
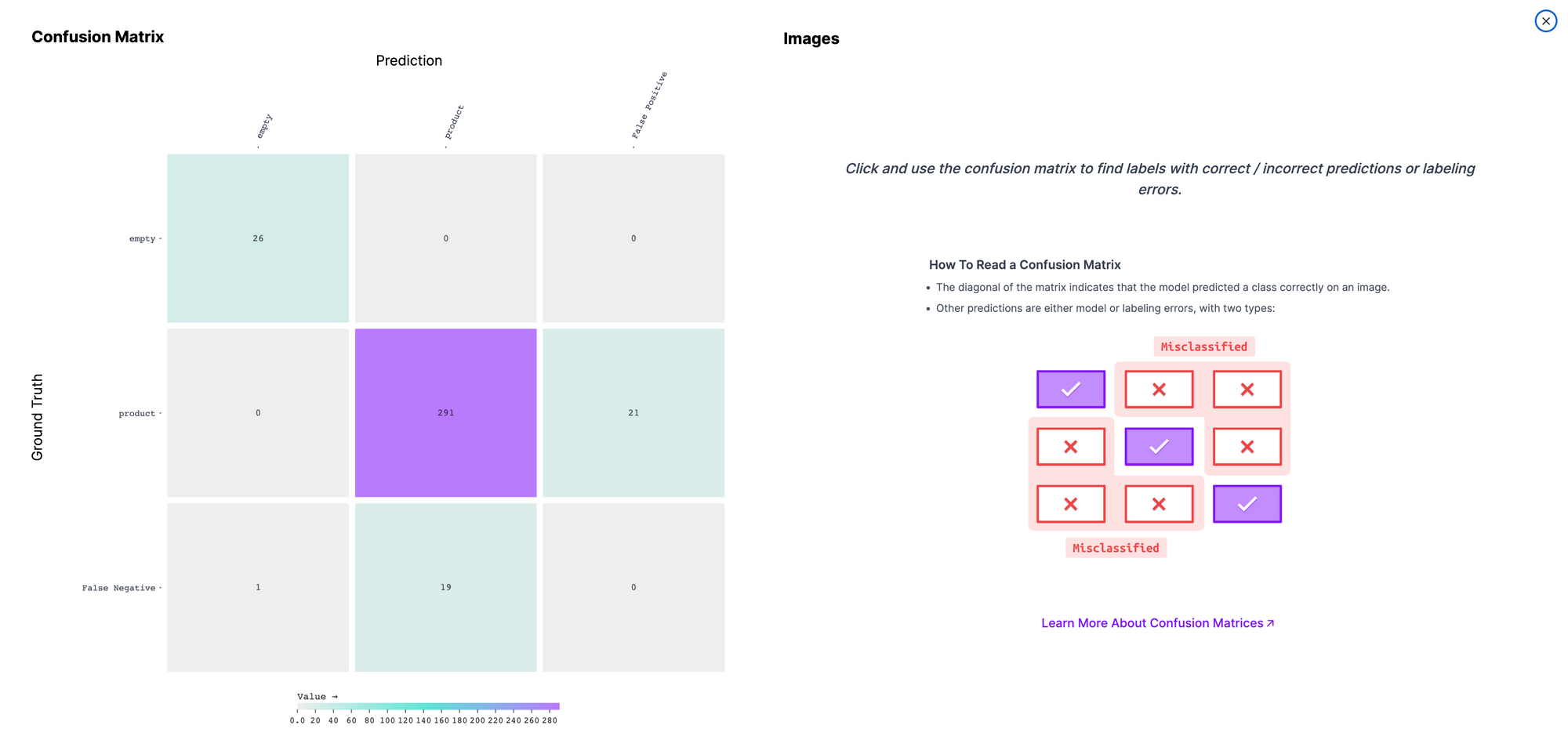
On the left is the model confusion matrix. On the right, there is some guidance showing how to read a confusion matrix.
Predictions in the diagonal row from the top left corner to the bottom right corner (excluding the False Negative and False Positive box) are true positives. This means there was an object in an image and your model successfully identified the object. Predictions that are not in this row are misidentifications. This means your model predicted the wrong class – or no class – for an object in an image.
Our model is able to accurately identify most products and empty positions on retail shelves. 291 "products" were successfully identified and 26 "empty" spaces were identified. With that said, there were some false positives and negatives.
False positives refer to instances where your model predicts a class when there is no instance of that class (i.e. when the model says there is an empty shelf when there is nothing there). False negatives are when your model does not identify a class (i.e. when there is an empty shelf but the model does not identify anything).
Review Misclassifications Per Image
We can give deeper into the results of our evaluation by clicking on any square in our confusion matrix. This will open up a window in which we can view images in which our model misclassified an object and the images where our model correctly identified objects.
Let’s click on the box representing missed predictions of the “product” class:
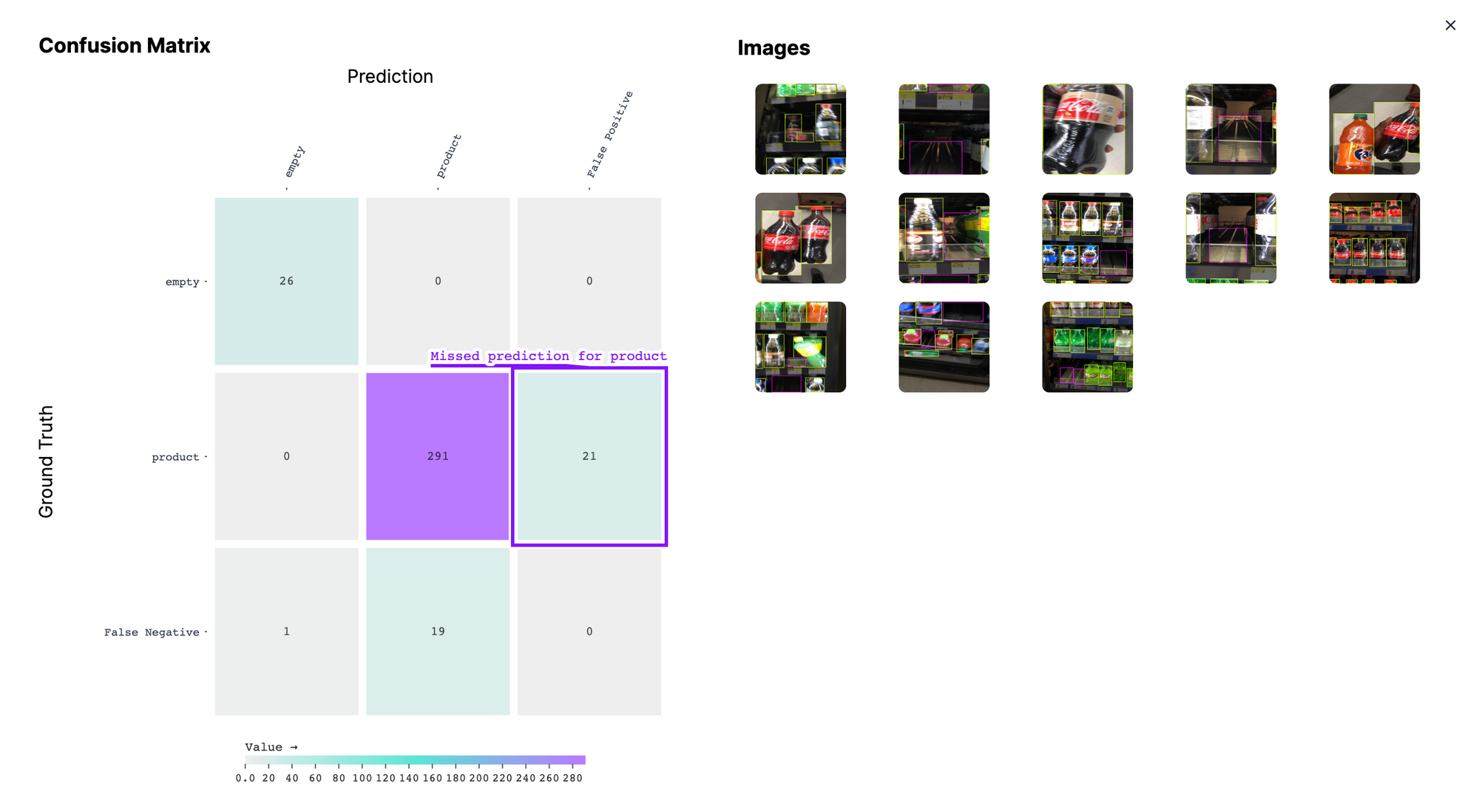
You can click on any image on the left side to see your annotations in the Roboflow platform.
Let’s click on one of the images:
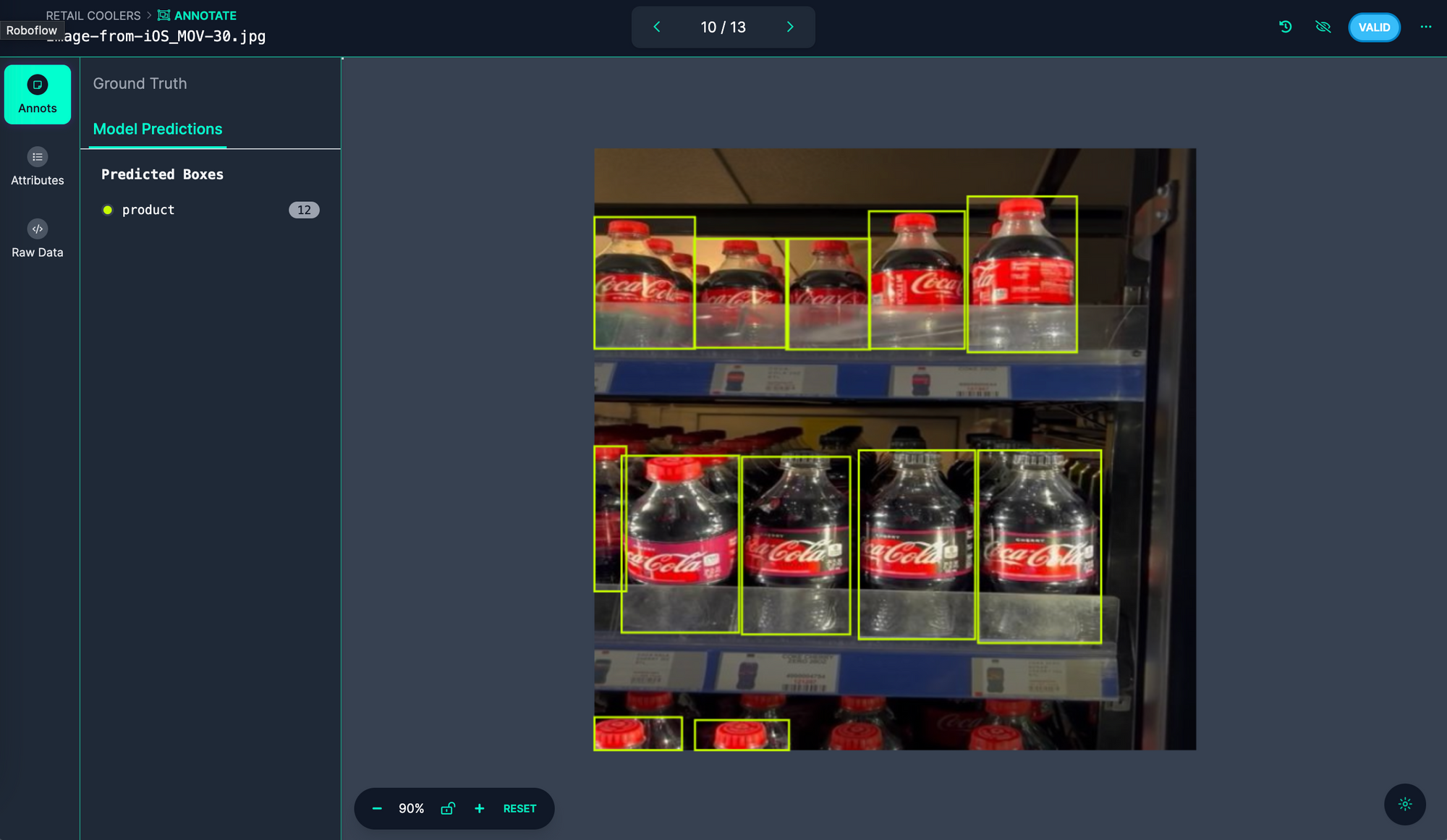
By default, predictions from the model will appear. To show ground truth – our annotations – click "Ground Truth" in the top left corner of the page:
Two bottles were annotated but not predicted by our model:

You can review images in your confusion matrices to identify patterns that come up frequently, then devise a plan to address issues.
To address the aforementioned issue we could add more bottles that are occluded, particularly at the bottom of an image, to our dataset. The more data we have showing this condition, the greater the ability of our model to identify a situation wherein only, for example, a bottle cap is present.
If a class is frequently misidentified, check whether the class is represented in your dataset. Are there any situations where data is mislabeled (the Roboflow ground truth viewer will help you find these)? If so, they may be impacting the quality of your model.
If a particular class is frequently missed, review the scenarios in which the object is not identified. Is the object occluded? Different to most images in your training data? If so, consider adding more representative data to your dataset to help your model generalize to identify the objects for which you are looking.
Conclusion
Using the new confusion matrix model evaluation features available in the Roboflow platform, you can develop a greater understanding of how your model performs. Your analysis of model evaluation results can guide you in making a decision about whether your model is ready for production.
If you identify issues – for example, a high number of false positives for a particular class – you can use our model evaluation tool to find what images were misclassified, and use this data to help guide your investigations. For instance, it may be the case that a class with a high number of false positives is not well represented, or instances of the class in your dataset are not fully representative of real-world conditions.
Model evaluation now runs automatically for paid Roboflow customers. We also have an open-source tool, CVevals, you can use to run evaluations on computer vision models, including those hosted on Roboflow. This tool is available for all users. You can learn more about CVevals in our walkthrough guide, and in the Roboflow model evaluation example.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Jun 13, 2023). Launch: Evaluate Computer Vision Models on Roboflow. Roboflow Blog: https://blog.roboflow.com/evaluate-roboflow-models/