
Splitting a dataset into training, validation, and test sets is the primary defense against overfitting in computer vision: the training set teaches the model, the validation set guides training decisions without contaminating held-out evaluation, and the test set gives a final unbiased performance read. A common starting split is 70-80% training, with the remaining data divided between validation and test. The post also covers pitfalls like train/test bleed and over-relying on validation metrics as a proxy for real-world performance.
At Roboflow, we often get asked:
"What is the train, validation, test split and why do I need it?"
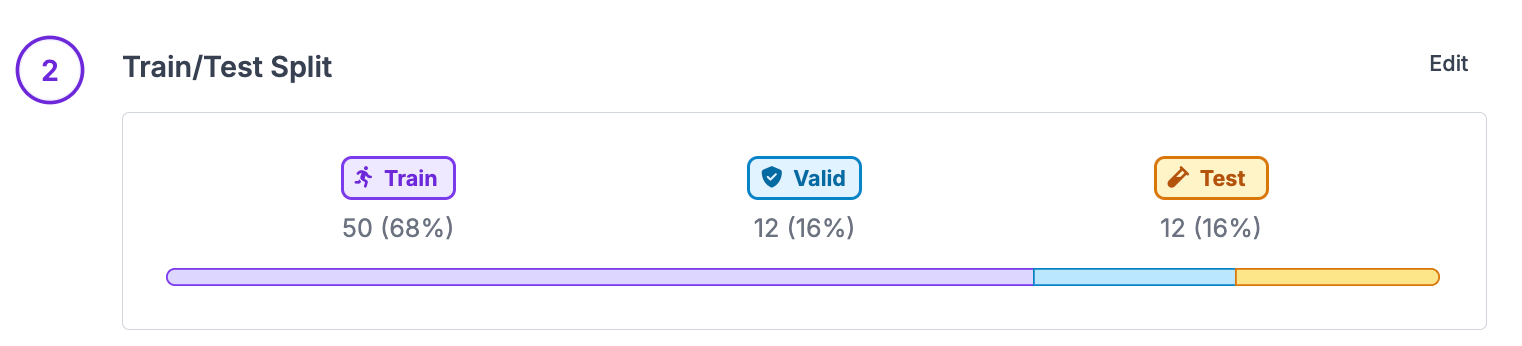
The motivation is quite simple: you should separate your data into train, validation, and test splits to prevent your model from overfitting and to accurately evaluate your model. The practice is more nuanced.
What is Overfitting in Computer Vision?
When training a computer vision model, you show your model example images to learn from. In order to guide your model to convergence, your model uses a loss function to inform the model how close or far away it is from making the correct prediction. A loss function is a way of describing the "badness" of a model. The smaller the value of the loss function, the better the model.
The model formulates a prediction function based on the loss function, mapping the pixels in the image to an output.
The danger in the training process is that your model may overfit to the training set. That is, the model might learn an overly specific function that performs well on your training data, but does not generalize to images it has never seen.
This is a 2D example.
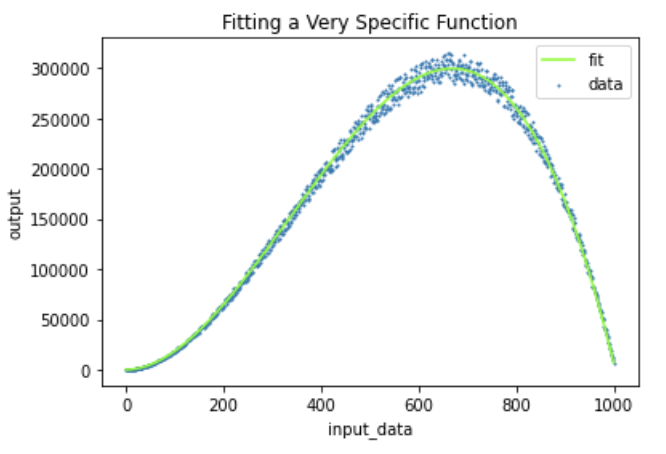
If your model hyper-specifies to the training set, your loss function on the training data will continue to show lower and lower values, but your loss function on the held-out validation set will eventually increase. You can see this plotted below with two curves visualizing the loss function values as training continues:
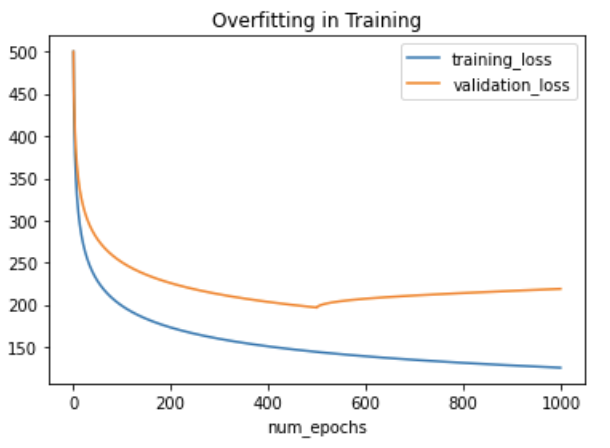
This means that your model isn't learning well, but is basically memorizing the training set. This means that your model will not perform well on new images it has never seen before.
The train, validation, and testing splits are built to combat overfitting.
What is the Training Dataset?
The difference between the training set and the validation set is the training set is the largest corpus of your dataset that you reserve for training your model. After training, inference on these images will be taken with a grain of salt, since the model has already had a chance to look at and memorize the correct output.
For a default, we recommend allocating 70% of your dataset to the training set. (If you're an advanced user and feel comfortable not using defaults, we've made it easier for you to change these defaults in Roboflow.)
What is the Validation Dataset?
The validation set is a separate section of your dataset that you will use during training to get a sense of how well your model is doing on images that are not being used in training.
During training, it is common to report validation metrics continually after each training epoch such as validation mAP or validation loss. You use these metrics to get a sense of when your model has hit the best performance it can reach on your validation set. You may choose to cease training at this point, a process called "early stopping."
As you work on your model, you can continually iterate on your dataset, image augmentations, and model design to increase your model's performance on the validation set.
We recommend holding out 20% of your dataset for the validation set.
What is the Test Dataset?
After all of the training experiments have concluded, you probably have gotten a sense on how your model might do on the validation set. But it is important to remember that the validation set metrics may have influenced you during the creation of the model, and in this sense you might, as a designer, overfit the new model to the validation set.
Because the validation set is heavily used in model creation, it is important to hold back a completely separate stronghold of data - the test set. You can run evaluation metrics on the test set at the very end of your project, to get a sense of how well your model will do in production.
We recommend allocating 10% of your dataset to the test set.
How Train Validation and Test Relate to Preprocessing and Augmentation
Naturally, the concept of train, validation, and test influences the way you should process your data as you are getting ready for training and deployment of your computer vision model.
Preprocessing steps are image transformations that are used to standardize your dataset across all three splits. Examples include static cropping your images, or gray scaling them. All preprocessing steps are applied to train, validation, and test.
Image augmentations are used to increase the size of your training set by making slight alterations to your training images. These occur only to the training set and should not be used during evaluation procedures. For evaluation, you want to use the ground truth images, residing in the validation and test sets.
Common Pitfalls in the Train, Validation, Test Split
Here are some common pitfalls to avoid when separating your images into train, validation and test.
Train/Test Bleed
Train Test bleed is when some of your testing images are overly similar to your training images. For example, if you have duplicate images in your dataset, you want to make sure that these do not enter different train, validation, test splits, since their presence will bias your evaluation metrics. Thankfully, Roboflow automatically removes duplicates during the upload process, so you can put most of these thoughts to the side.
Overemphasis on the Training Set
The more data, the better the model. This mantra might tempt you to use most of your dataset for the training set and only to hold out 10% or so for validation and test. Skimping on your validation and test sets, however, could cloud your evaluation metrics with a limited subsample, and lead you to choose a suboptimal model.
Overemphasis on Validation and Test Set Metrics
At the end of the day, the validation and test set metrics are only as good as the data underlying them, and may not be fully representative of how well you model will perform in production. That said, you should use them as a guide post, pushing your models performance and robustness ever higher.
Test Set vs Training Set vs Validation Set
In this post, we have discussed the train, validation, test splits and why they can help us prevent model overfitting by choosing the model that will do best in production. We have also discussed some common pitfalls in the creation and use of train, validation, and test splits and how you can avoid them.
As always, happy training.
Frequently Asked Questions
What size should be used for training, test, and validation datasets?
The split between training, test, and validation data will vary depending on your project. A good place to start is for 80% of data to be in the training set and 10% of data to be in both test and validation datasets.
Can you add image augmentations to training and validation datasets?
Image augmentations should only be added to training datasets. These augmentations include adding greyscale images based on existing training data, adding occlusions to images, and other changes to add artificial data to improve the size of your dataset.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Sep 4, 2020). Train, Validation, Test Split for Machine Learning. Roboflow Blog: https://blog.roboflow.com/train-test-split/