
Domain-specific models consistently outperform large general-purpose offerings from cloud providers in speed and accuracy on narrow tasks, but covering multiple object classes usually means running several models in parallel. Autodistill lets you combine two or more specialized models to automatically annotate a single dataset, then train one compact model that inherits accuracy from each specialist. In tests on a self-driving car dataset, the combined model trained through Roboflow outperformed COCO-pretrained models and commercial APIs from Google Cloud Vision and AWS Rekognition on both speed and accuracy.
In recent years, both computer vision and AI have focused on the allure of large, general-purpose multimodal models such as OpenAI’s GPT-4 with Vision or Google’s Gemini. However, recent experiments highlight how domain-specific models, like a specialized person or vehicle detection model, often outperform larger general-purpose models from Google Cloud and AWS in their respective use cases in speed and performance.

In this guide, we will explore how to take advantage of the expertise of two (or more) domain-specific models to label data and train a new model. Then, we will evaluate the new combined model to see how it compares to multiple domain-specific specialized models, as well as larger models like COCO and black-box offerings from Google Cloud Vision and AWS Rekognition.
Why Label with Multiple Models?
There are scenarios in which the benefits of combining a model, with the versatility of a larger model while maintaining the accuracy and speed of a domain-specific model, can be helpful.
- Train a model without collecting data: If you want to quickly bootstrap a model, you can combine various datasets and use multiple models to make consistent annotations across datasets
- Add an object on an existing model: In scenarios where you want to add a new class to your model, you can quickly use your existing model, as well as a model specialized to the additional object, to supplement your existing model.
- Eliminate the need to run multiple specific models simultaneously: If you already have multiple specialized models for the same use, combine them for operational efficiency and speed.
For our example, we will label a dataset of images for a self-driving car that had some missing labels. To quickly get an initial version trained, we can automatically label this dataset using a person detection model and a vehicle detection model.
Step 1: Create or Download a Dataset
In order to use the specialized models to train a combined model for your use case, you need to collect or upload images for your dataset. You can also search for images on Roboflow Universe to quickly get started on building out your model.
For our example, we will be using a subset of images from the Udacity Autonomous Driving dataset on Roboflow Universe.
Step 2: Use Autodistill for Annotation
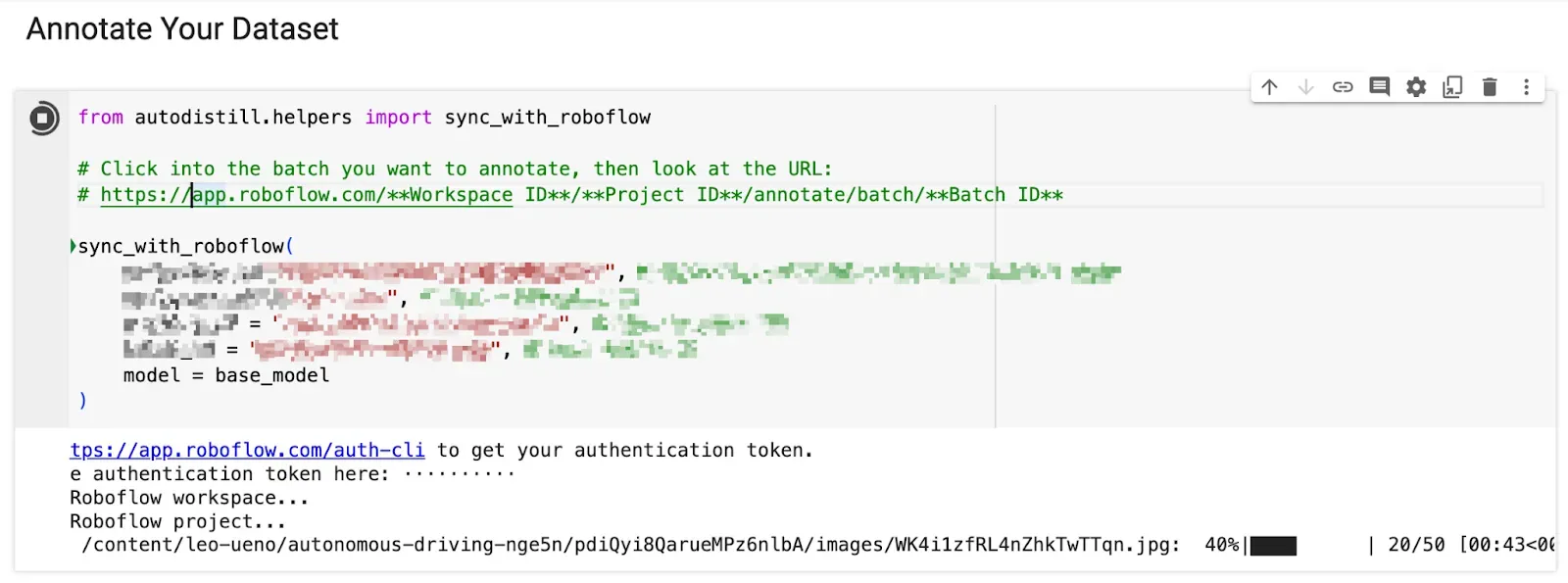
Usually, at this point, we would start labeling our images. Luckily, we have two specialized models we can use to quickly label our images using Autodistill. First, we configure Autodistill to label using our Universe models.
from autodistill_roboflow_universe import RoboflowUniverseModel
from autodistill.detection import CaptionOntology
model_configs = [
("vehicle-detection-3mmwj", 1),
{"people-detection-o4rdr", 7}
]
base_model = RoboflowUniverseModel(
ontology=CaptionOntology(
{
"person": "person",
"vehicle": "vehicle"
}
),
api_key="YOUR_ROBOFLOW_API_KEY",
model_configs=model_configs,
)Then, using a feature in Autodistill and Google Colab, we can run models against our images and have them sync directly within the Roboflow interface.
Once we kick off labeling, it took just a couple of minutes to label over 150 images. Once the dataset is labeled, we can review it for accuracy and correct mistakes before adding it to our dataset.
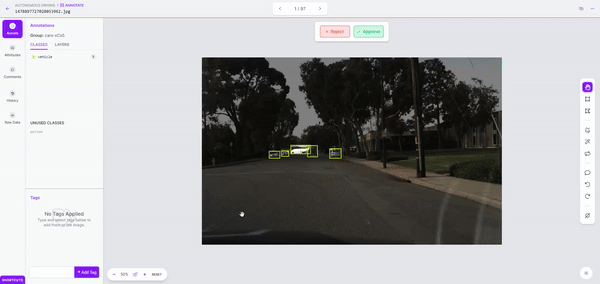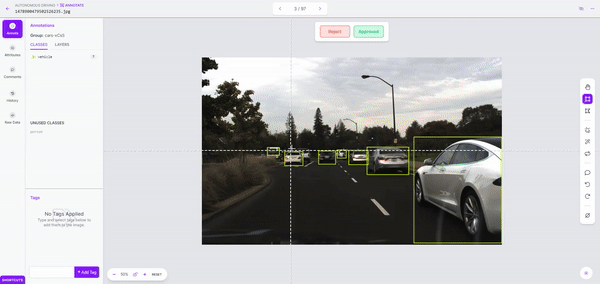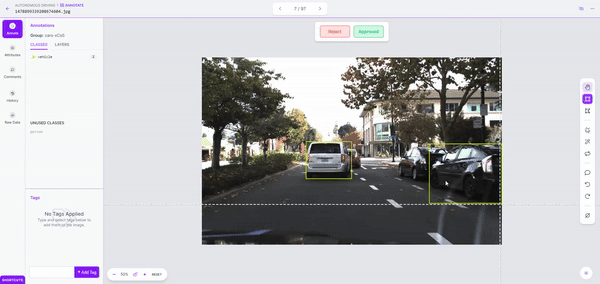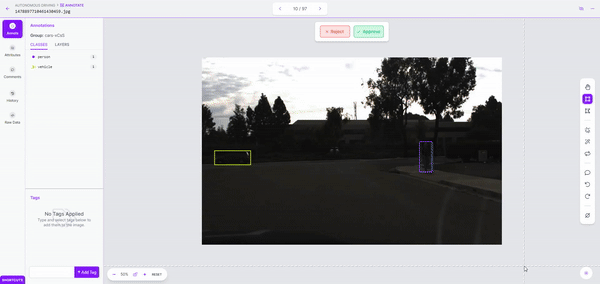
Step 3: Model Training
Once we have our images labeled, we can move on to training the first version of our model, achieving an accuracy of 83.4%.

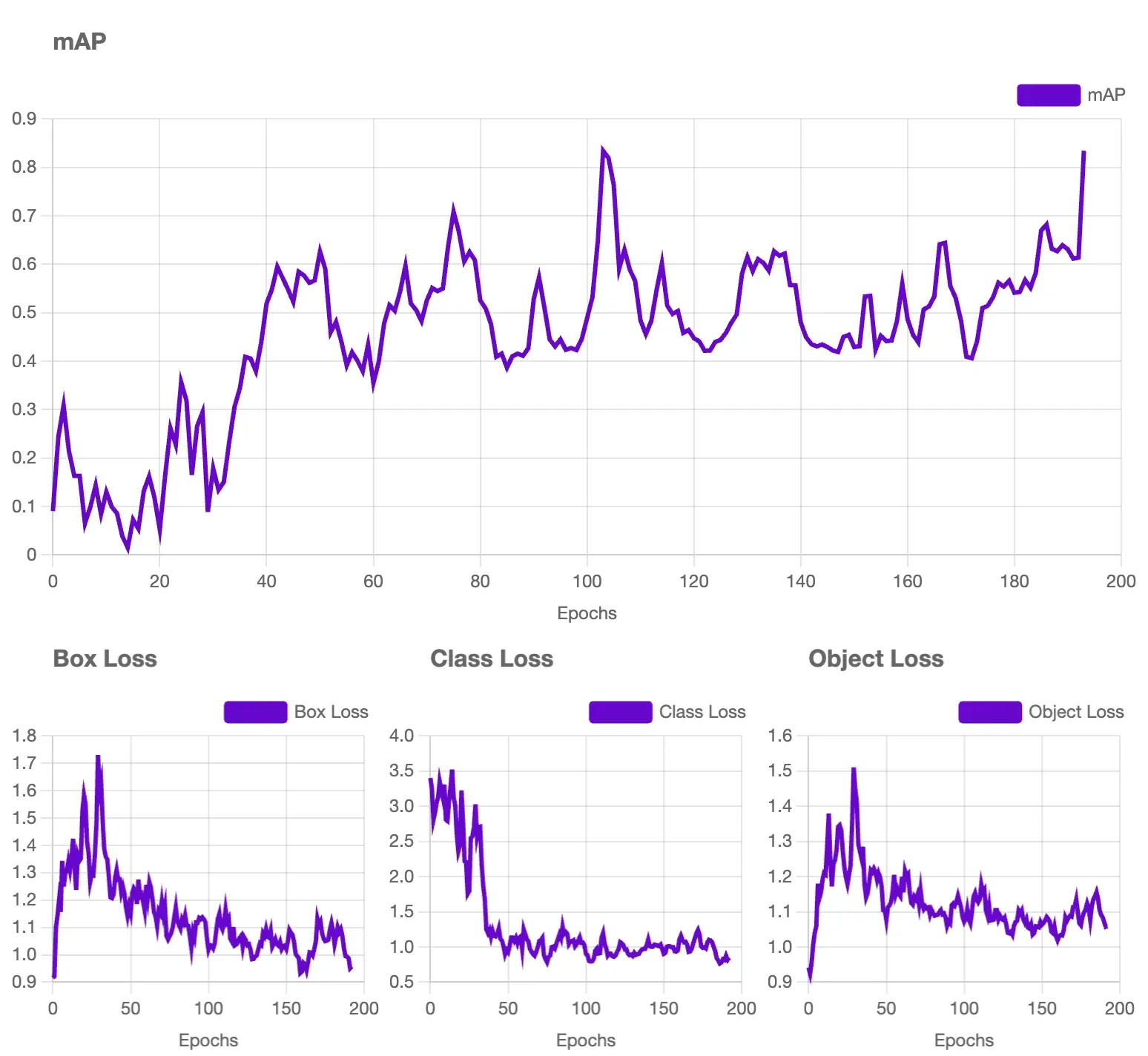
Evaluating the Combined Model
Now that we have our model trained, we can run some evaluations to see if the reasons for combining the models hold true.
First, we will evaluate the combined model against two of the specialized models we used. Then we will see how the model performs against other offerings like COCO, Google Cloud Vision, and Amazon Rekognition.
Specialized Models
To see how our new model performs, we can run predictions on the test splits of the specialized model datasets using the hosted inference API.
In our results, we see a small (5~10 milliseconds) hit on our inference time.
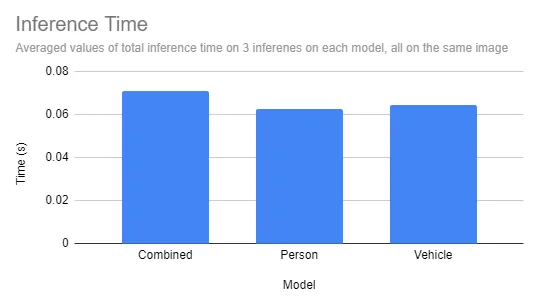
Other Large Vision Models
While having a comparable inference time to other specialized models is useful, the detections we are performing can often be done with large vision models. Along with comparing two cloud offerings from Google Cloud Vision and Amazon’s AWS Rekognition, we can also compare our “Fast” combined model trained on Roboflow against a similarly sized YOLOv8n Microsoft COCO model.
In terms of accuracy, the combined model, trained on images from our dataset and annotated by our domain-specific models, outperformed all other offerings by a considerable margin, which is to be expected of a model trained on similar images for the same use case.
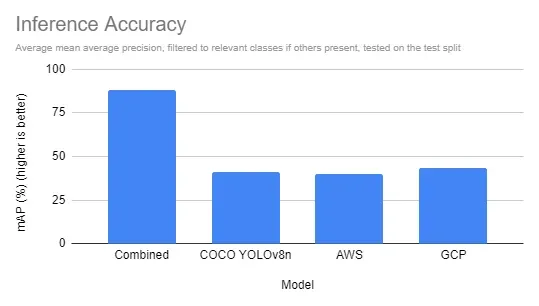
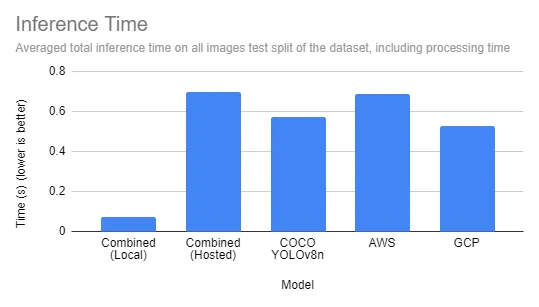
Additionally, a combined model, larger than a specialized model yet smaller than the other large models, provides an opportunity to host the model locally, using our open-source Inference package. Running models locally provides a drastic speed advantage, while a managed hosted inference API provides comparable speeds to other big-box models.
Conclusion
In this guide, we laid out use cases for why using domain-specific models for new model training can be useful, walked through the steps for training your own combined model, and then evaluated our model to prove the usefulness of combining the expertise of two specialized vision models on a custom dataset.
We saw that it not only performed similarly to the specialized models we used to create our model, but it outperformed other offerings in accuracy and speed.
Cite this Post
Use the following entry to cite this post in your research:
Leo Ueno. (Feb 16, 2024). How to Use Multiple Models to Label Datasets with Autodistill. Roboflow Blog: https://blog.roboflow.com/multi-model-dataset-labeling/