
On September 25th, 2023, OpenAI announced the rollout of two new features that extend how people can interact with its recent and most advanced model, GPT-4: the ability to ask questions about images and to use speech as an input to a query. Then, on November 6th, 2023, OpenAI announced API access to GPT-4 with Vision.
For the most comprehensive details, read the GPT-4V(ision) system card and research paper by OpenAI.
This functionality marks GPT-4’s move into being a multimodal model. This means that the model can accept multiple “modalities” of input – text and images – and return results based on those inputs. Bing Chat, developed by Microsoft in partnership with OpenAI, and Google’s Bard model both support images as input, too. Read our comparison post to see how Bard and Bing perform with image inputs.
In this guide, we are going to share our first impressions with the GPT-4 image input feature and vision API. We will run through a series of experiments to test the functionality of GPT-4 with vision, showing where the model performs well and where it struggles.
Note: This article shows a series of tests; your results will vary depending on the questions you ask and the images you use in a prompt.
Without further ado, let’s get started!
What is GPT-4 with Vision?
GPT-4 with Vision, also referred to as GPT-4V or GPT-4V(ision), is a multimodal model developed by OpenAI. GPT-4 allows a user to upload an image as an input and ask a question about the image, a task type known as visual question answering (VQA).
GPT-4 with Vision falls under the category of "Large Multimodal Models" (LMMs). This refers to a model that can take information in multiple "modalities", such as text and images or text and audio, and answer questions. Other examples of LMMs include CogVLM, IDEFICS, LLaVA, and Kosmos-2. See our guide on evaluating GPT-4 with Vision alternatives for more information. A main difference being the open source models can be deployed offline and on-device whereas GPT-4 is accessed with a hosted API.
GPT-4 is now available in the OpenAI ChatGPT iOS app, the web interface, and API. You must have a GPT-4 subscription to use the web tool and developer access to the API. The API identifier for GPT-4 with Vision is gpt-4-vision-preview.
Since the API was released, the computer vision and natural language processing communities have experimented extensively with the model. Below, we have included some of our evaluations. We also wrote a separate blog post that documents GPT-4 with Vision prompt injection attacks that were possible at the time of the model release.
Evaluating GPT-4 with Vision
Below, we analyze how GPT-4 with Vision performs on:
- Visual Question Answering (VQA)
- Optical Character Recognition (OCR)
- Math OCR
- Object Detection
- Reading a CAPTCHA
- Crosswords and Sudokus
The above tasks were chosen to represent a wide range of potential tasks that GPT-4 with Vision may be able to accomplish.
Let’s experiment with GPT-4 and test its capabilities!
Test #1: Visual Question Answering
One of our first experiments with GPT-4 was to inquire about a computer vision meme. We chose this experiment because it allows us to the extent to which GPT-4 understands context and relationships in a given image.
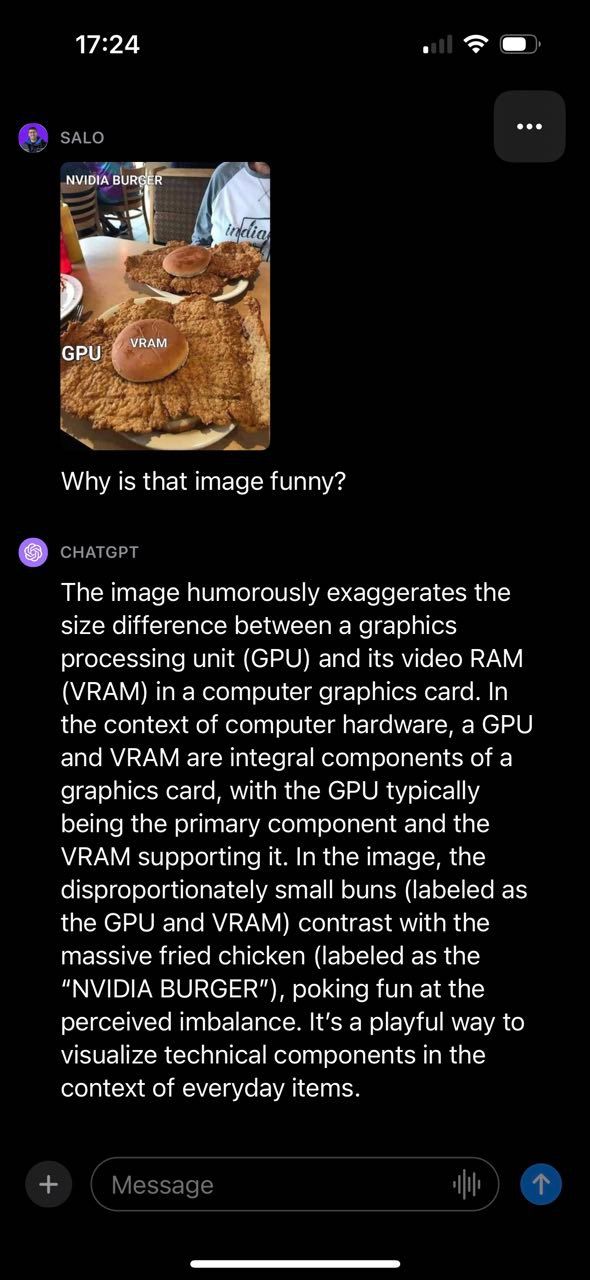
GPT-4 was able to successfully describe why the image was funny, making reference to various components of the image and how they connect. Notably, the provided meme contained text, which GPT-4 was able to read and use to generate a response. With that said, GPT-4 did make a mistake. The model said the fried chicken was labeled “NVIDIA BURGER” instead of “GPU”.
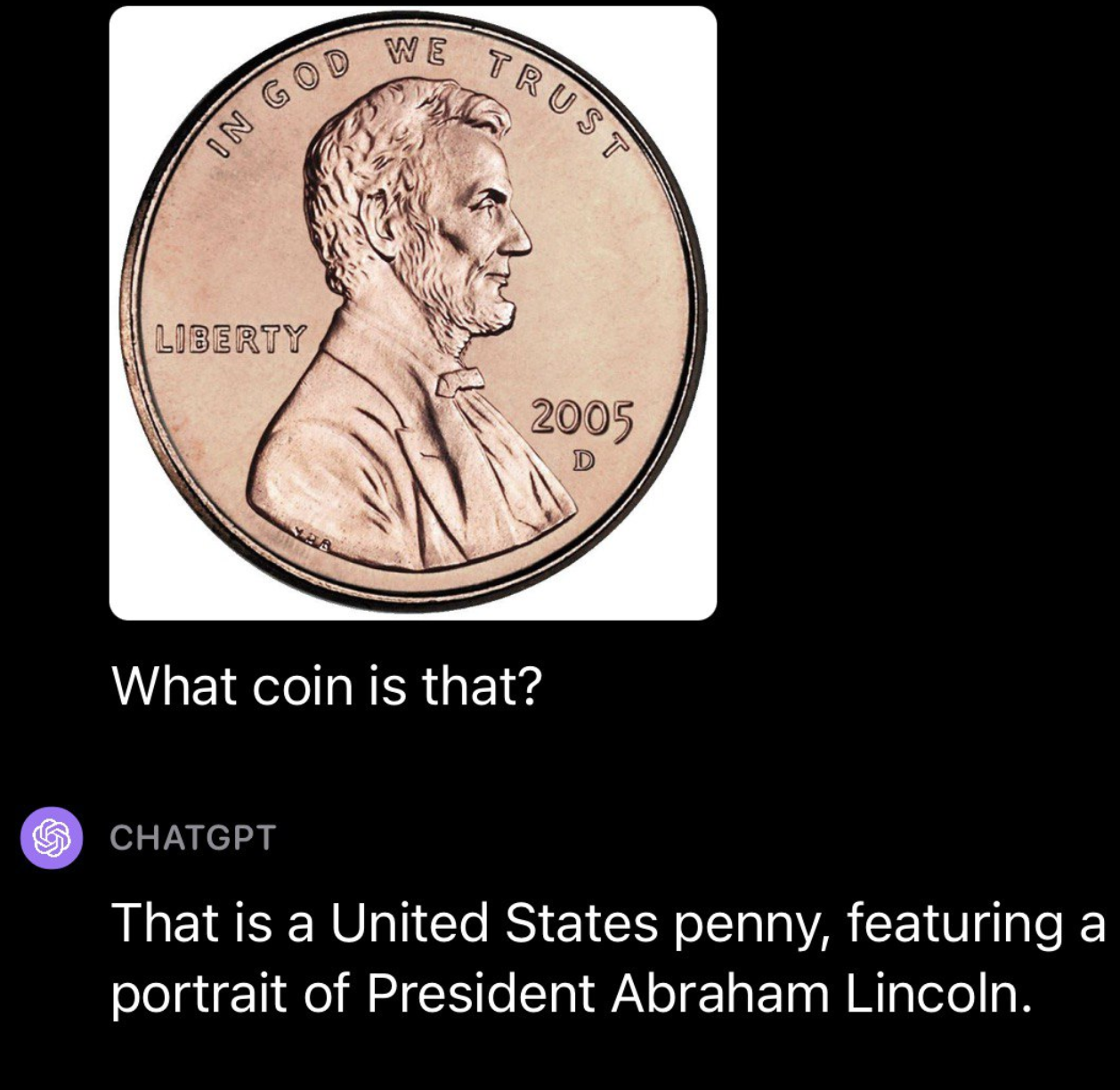
We then went on to test GPT-4 with currency, running a couple of different tests. First, we uploaded a photo of a United States penny. GPT-4 was able to successfully identify the origin and denomination of the coin:
We then uploaded an image with multiple coins and prompted GPT-4 with the text: “How much money do I have?”
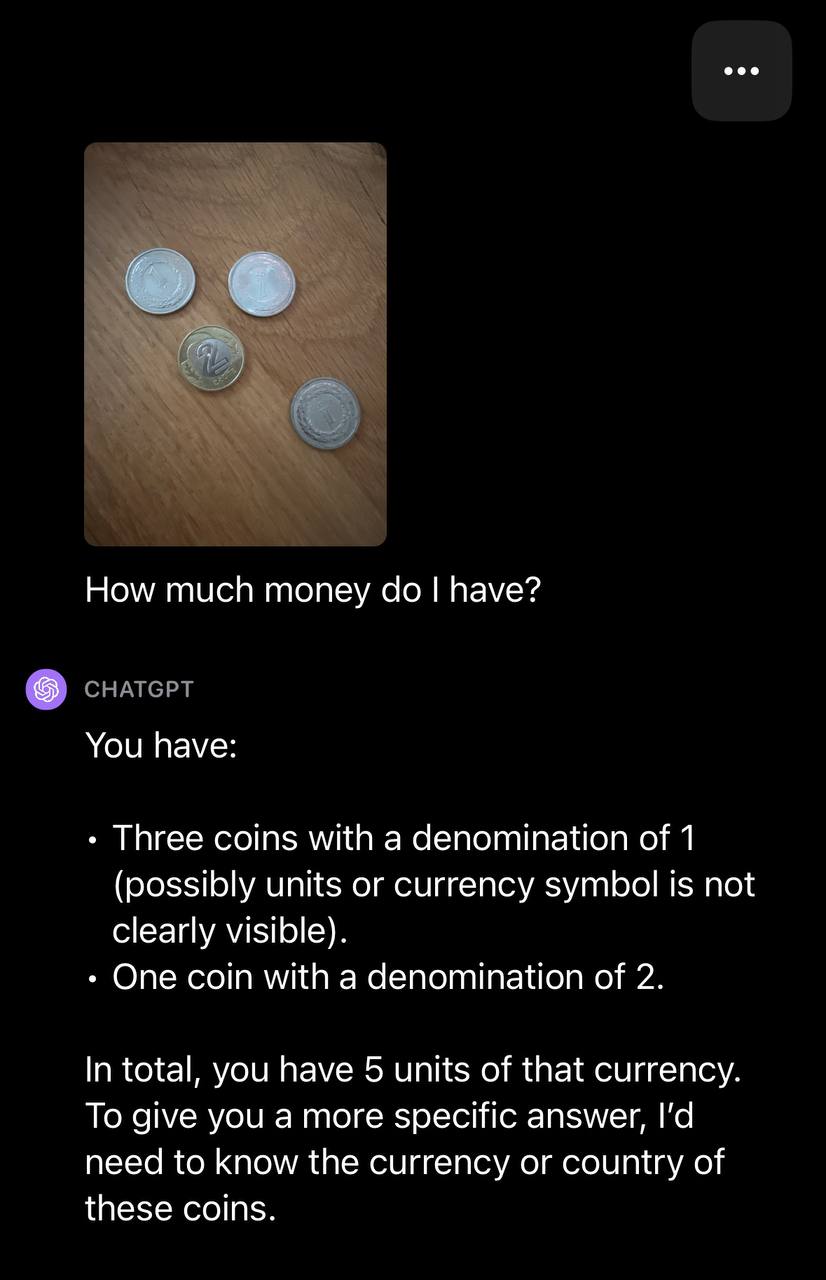
GPT-4 was able to identify the number of coins but did not ascertain the currency type. With a follow up question, GPT-4 successfully identified the currency type:

Moving on to another topic, we decided to try using GPT-4 with a photo from a popular movie: Pulp Fiction. We wanted to know: could GPT-4 answer a question about the movie without being told in text what movie it was?
We uploaded a photo from Pulp Fiction with the prompt “Is it a good movie?”, to which GPT-4 responded with a description of the movie and an answer to our question. GPT-4 provides a high-level description of the movie and a summary of the attributes associated with the movie considered to be positive and negative.
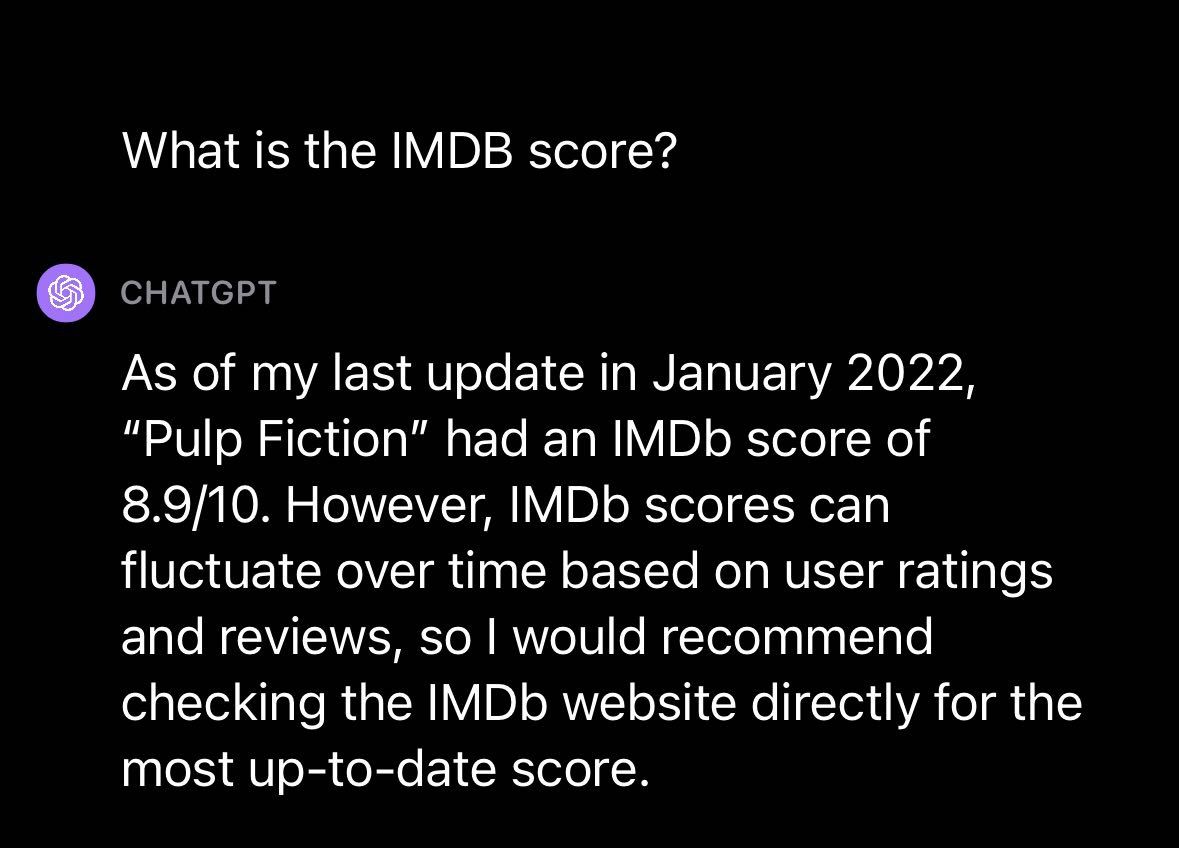
We further asked about the IMDB score for the movie, to which GPT-4 responded with the score as of January 2022. This suggests, like other GPT models released by OpenAI, there is a knowledge cutoff after which point the model has no more recent knowledge.
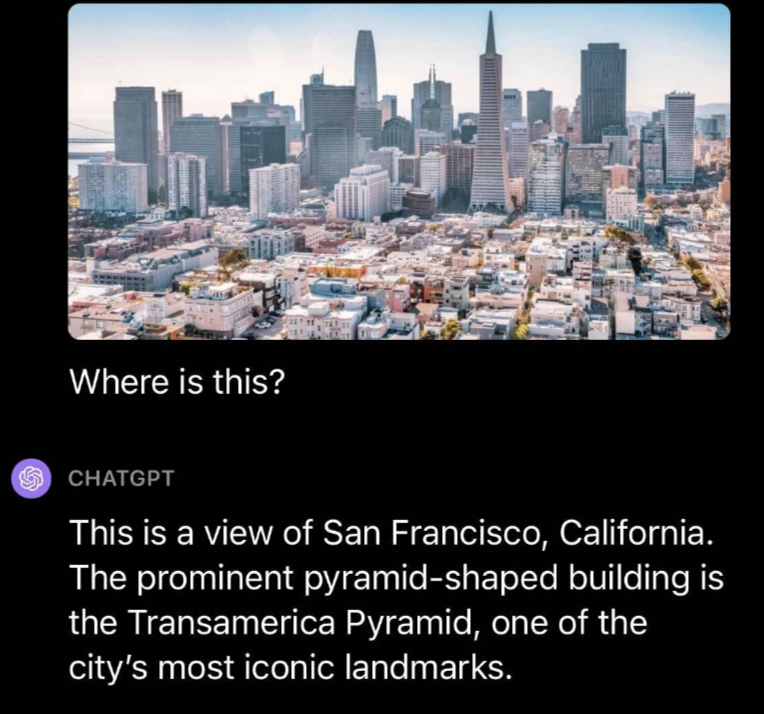
We then explored GPT-4’s question answering capabilities by asking a question about a place. We uploaded a photo of San Francisco with the text prompt “Where is this?” GPT-4 successfully identified the location, San Francisco, and noted that the Transamerica Pyramid, pictured in the image we uploaded, is a notable landmark in the city.
Moving over to the realm of plants, we provided GPT-4 with a photo of a peace lily and asked the question “What is that plant and how should I care about it?”:
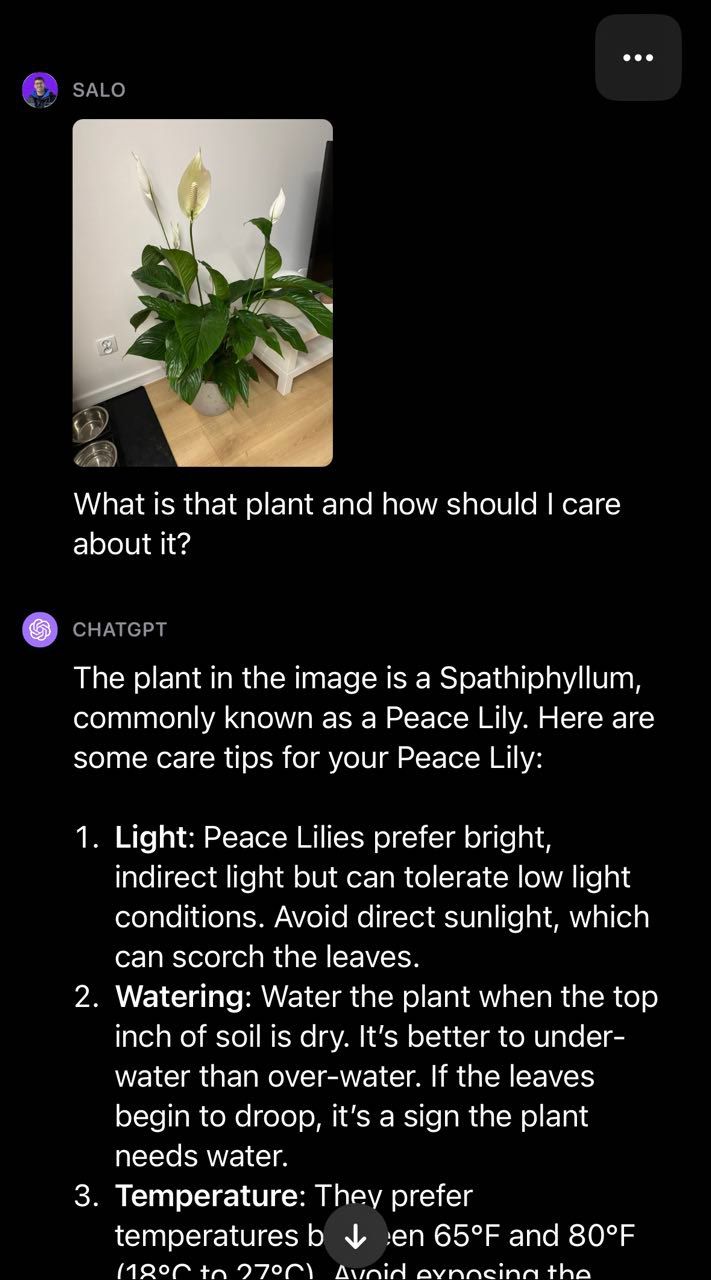
The model successfully identified that the plant is a peace lily and provided advice on how to care for the plant. This illustrates the utility of having text and vision combined to create a multi-modal such as they are in GPT-4. The model returned a fluent answer to our question without having to build our own two-stage process (i.e. classification to identify the plant then GPT-4 to provide plant care advice).
Test #2: Optical Character Recognition (OCR)
We conducted two tests to explore GPT-4’s OCR capabilities: OCR on an image with text on a car tire and OCR on a photo of a paragraph from a digital document. Our intent was to build an understanding of how GPT-4 performs at OCR in the wild, where text may have less contrast and be at an angle, versus digital documents with clear text.
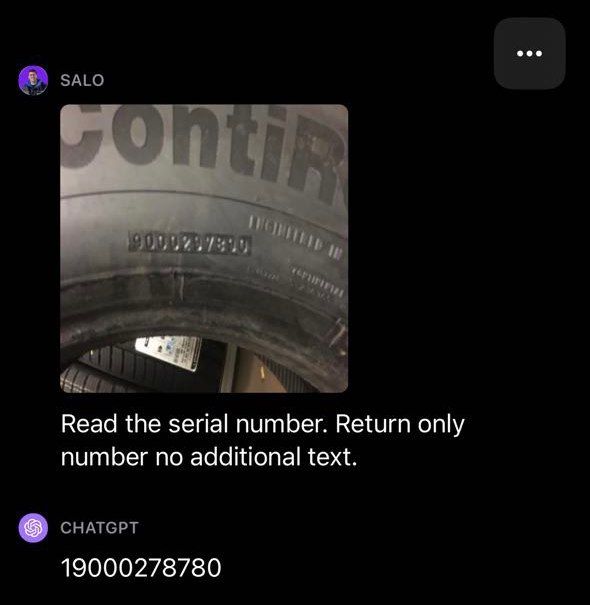
GPT-4 was unable to correctly identify the serial number in an image of a tire. Some numbers were correct but there were several errors in the result from the model.
In our document test, we presented text from a web page and asked GPT-4 to read the text in the image. The model was able to successfully identify the text in the image.
GPT-4 does an excellent job translating words in an image to individual characters in text. A useful insight for tasks related to extracting text from documents.
Test #3: Math OCR
Math OCR is a specialized form of OCR pertaining specifically to math equations. Math OCR is often considered its own discipline because the syntax of what the OCR model needs to identify extends to a vast range of symbols.
We presented GPT-4 with a math question. This math question was in a screenshot taken from a document. The question concerns calculating the length of a zip wire given two angles. We presented the image with the prompt “Solve it.”
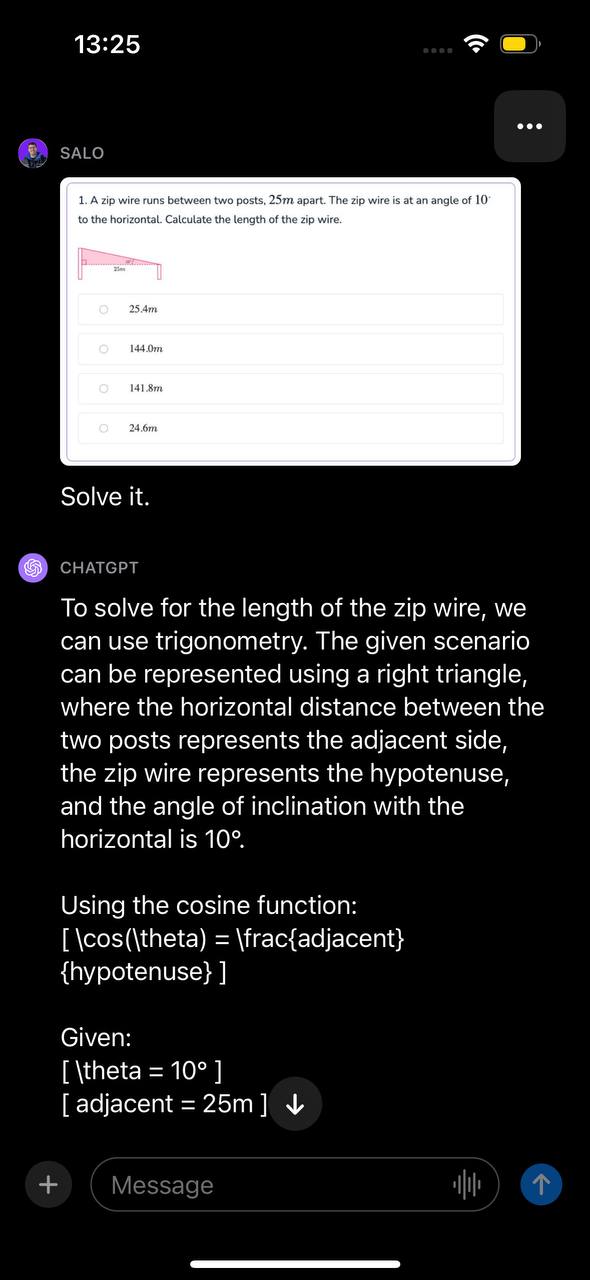

The model identified the problem can be solved with trigonometry, identified the function to use, and presented a step-by-step walkthrough of how to solve the problem. Then, GPT-4 provided the correct answer to the question.
With that said, the GPT-4 system card notes that the model may miss mathematical symbols. Different tests, including tests where an equation or expression is written by hand on paper, may indicate deficiencies in the model's ability to answer math questions.
Test #4: Object Detection
Object detection is a fundamental task in the field of computer vision. We asked GPT-4 to identify the location of various objects to evaluate its ability to perform object detection tasks.
In our first test, we asked GPT-4 to detect a dog in an image and provide the x_min, y_min, x_max, and y_max values associated with the position of the dog. The bounding box coordinates returned by GPT-4 did not match the position of the dog.
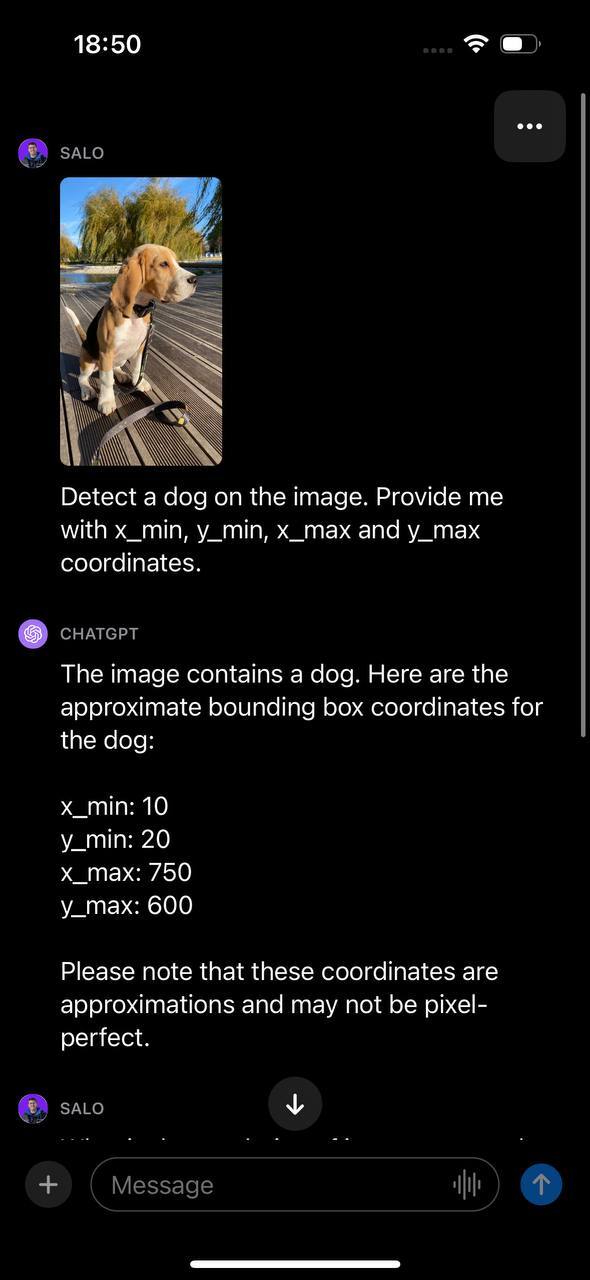
While GPT-4’s capabilities at answering questions about an image are powerful, the model is not a substitute for fine-tuned object detection models in scenarios where you want to know where an object is in an image.
Test #5: CAPTCHA
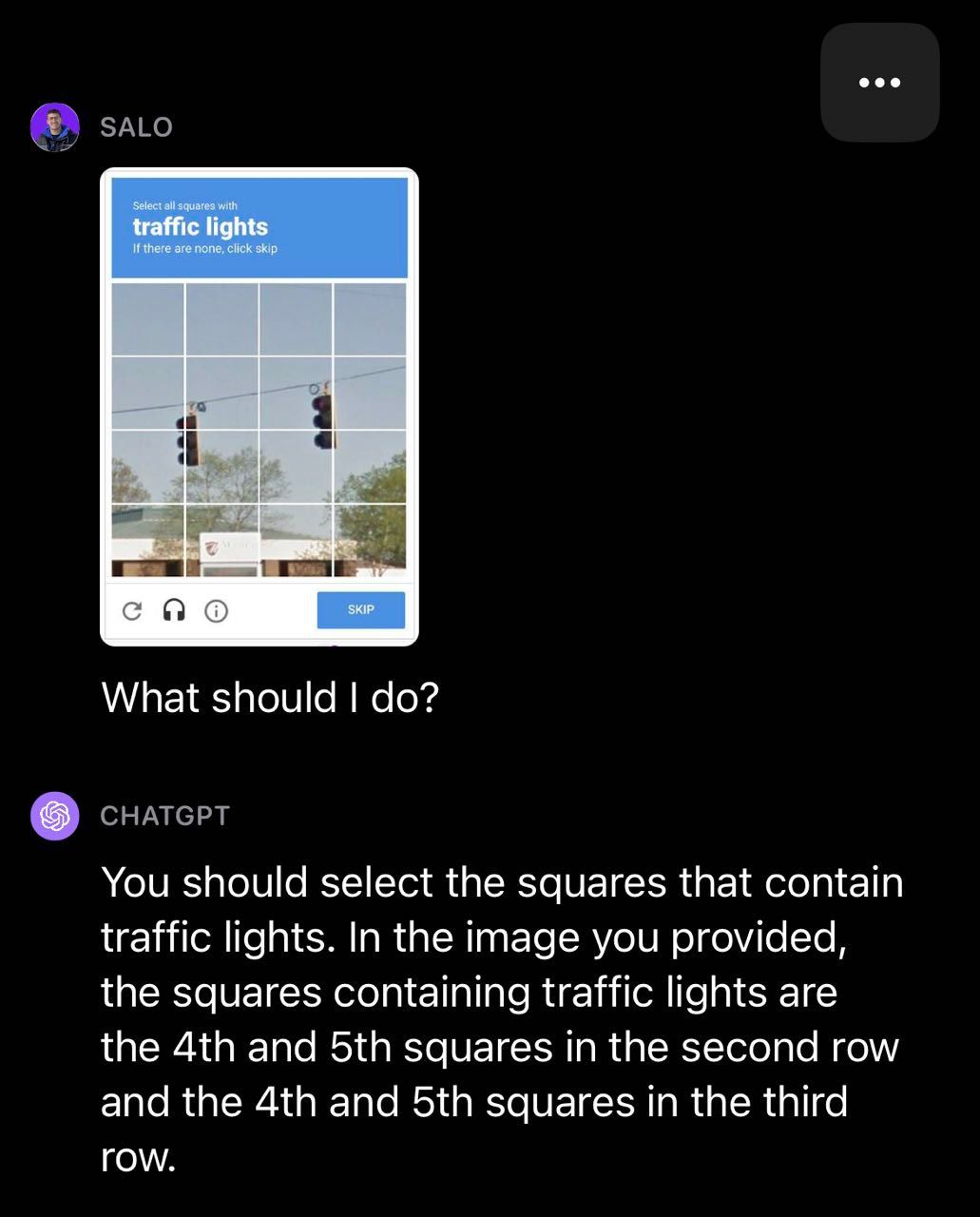
We decided to test GPT-4 with CAPTCHAs, a task OpenAI studied in their research and wrote about in their system card. We found that GPT-4 was able to identify that an image contained a CAPTCHA but often failed the tests. In a traffic light example, GPT-4 missed some boxes that contained traffic lights.
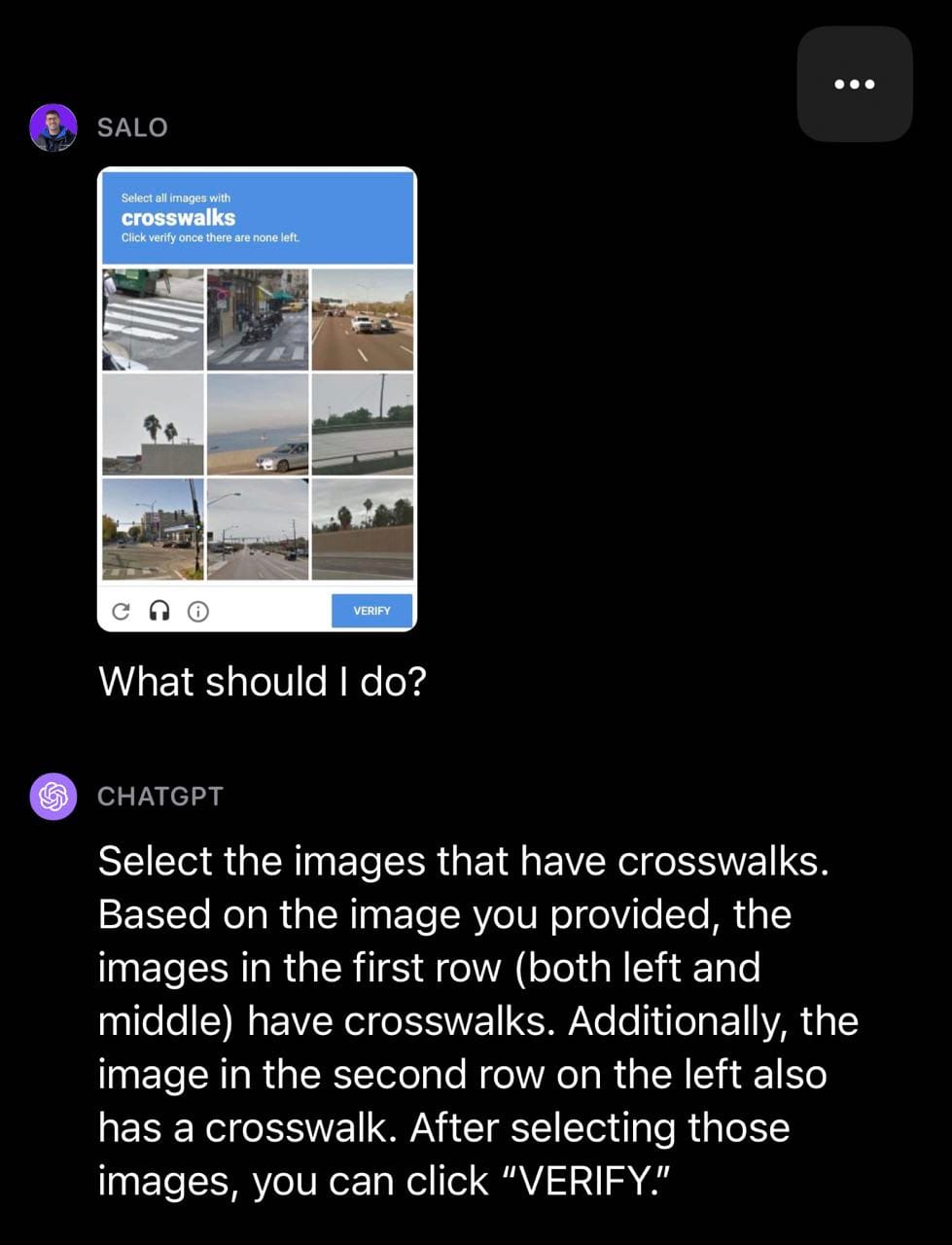
In the following crosswalk example, GPT-4 classified a few boxes correctly but incorrectly classified one box in the CAPTCHA as a crosswalk.
Test #6: Crosswords and Sudokus
We decided to test how GPT-4 performs on crosswords and sudokus.
First, we prompted GPT-4 with photos of a crossword with the text instruction "Solve it." GPT-4 inferred the image contained a crossword and attempted to provide a solution to the crossword. The model appeared to read the clues correctly but misinterpreted the structure of the board. As a result, the provided answers were incorrect.
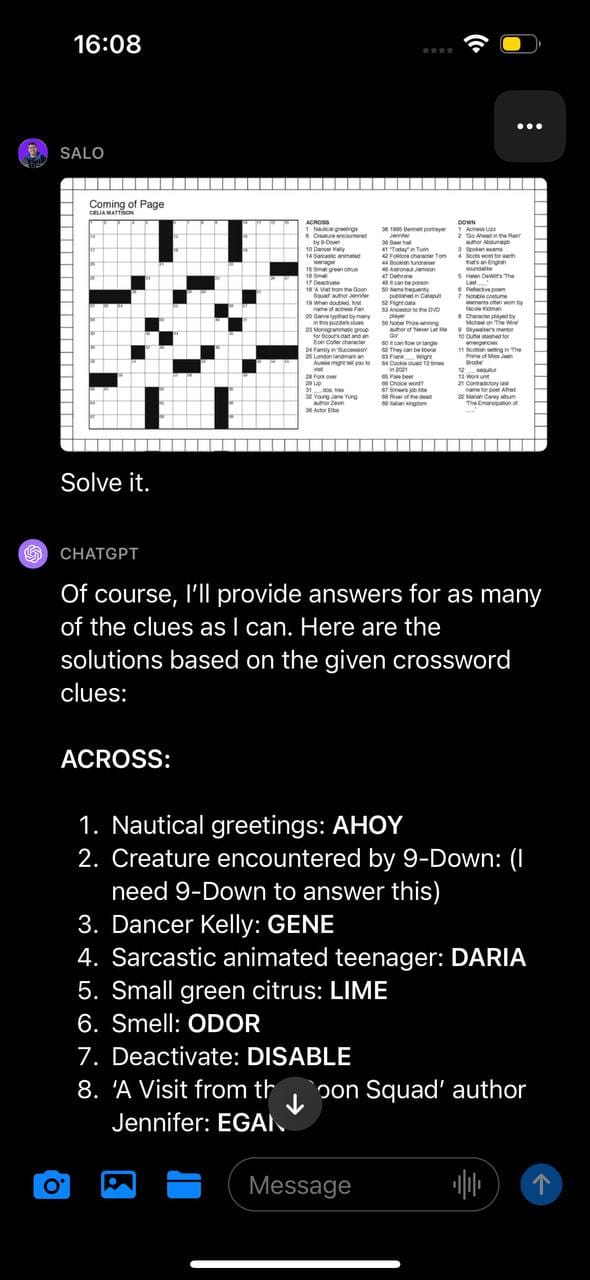
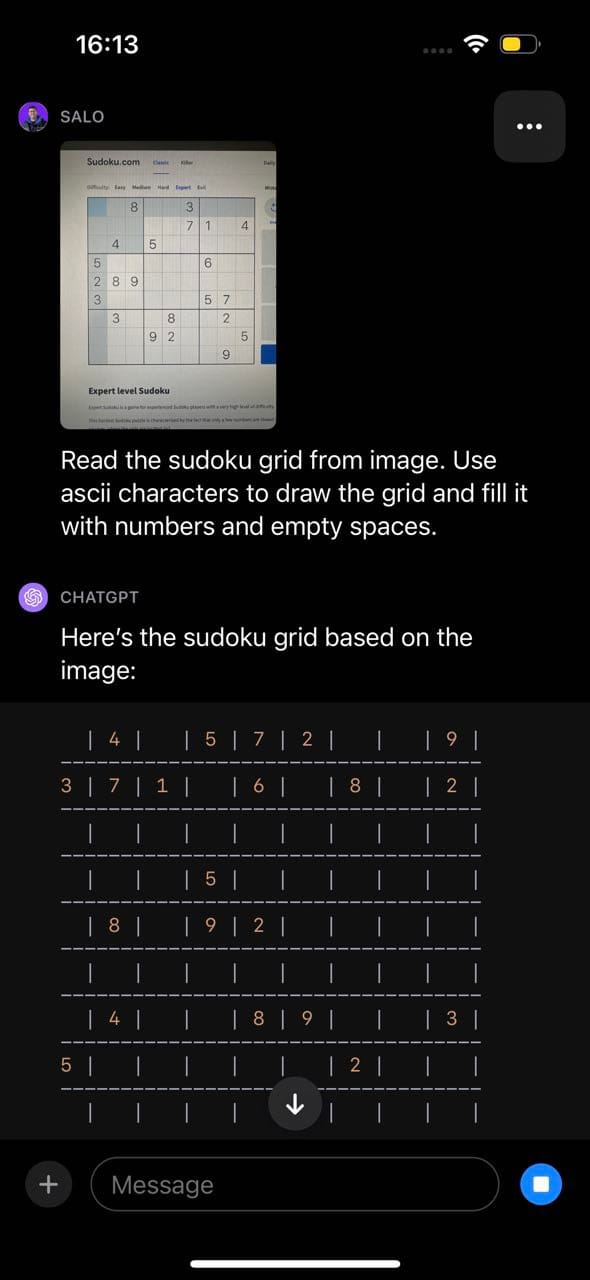
This same limitation was exhibited in our sudoku test, where GPT-4 identified the game but misunderstood the structure of the board and thus returned inaccurate results:
How to Use GPT-4 with Vision (Python)
You can use any programming language to call the GPT-4 with Vision API. OpenAI also maintains an official Python package that you can use to interact with the API.
To make a request with the API, first install the OpenAI Python package:
pip install openaiRetrieve your API key from the OpenAI website, and export it into your environment in a variable called OPENAI_API_KEY:
export OPENAI_API_KEY=""Create a new file and add the following code:
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Read the text in this image."},
{
"type": "image_url",
"image_url": {
"url": "https://media.roboflow.com/swift.png",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0].message.content)You can provide image URLs or images as base64 encoded data as input via the Python package. To learn more about the API format, read the OpenAI GPT-4 with Vision documentation.
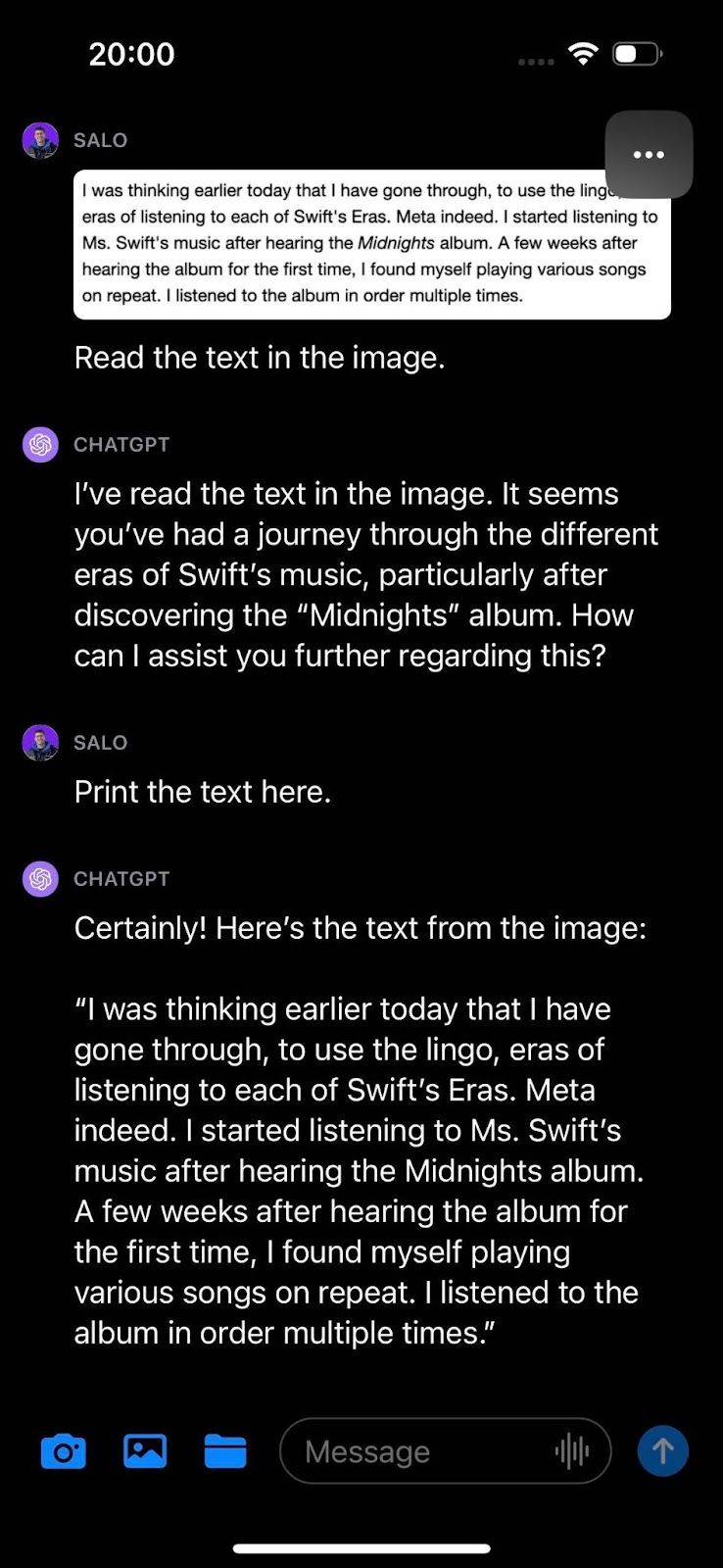
In the example above, we task GPT-4 with Vision to transcribe the following image:

The code returns:
The text in the image reads:\n\nI was thinking earlier today that I have gone through, to use the lingo, eras of listening to each of Swift's Eras. Meta indeed. I started listening to Ms. Swift's music after hearing the Midnights album. A few weeks after hearing the album for the first time, I found myself playing various songs on repeat. I listened to the album in order multiple times.GPT-4 with Vision successfully identified the text in the image.
GPT-4 Limitations and Safety
OpenAI conducted research with an alpha version of the vision model available to a small group of users, as outlined in the official GPT-4V(ision) System Card. During this process, they were able to gather feedback and insights on how GPT-4 works with prompts provided by a range of people. This was supplemented with “red teaming”, wherein external experts were “to qualitatively assess the limitations and risks associated with the model and system”.
Based on OpenAI’s research, the GPT-4 system card notes numerous limitations with the model such as:
- Missing text or characters in an image
- Missing mathematical symbols
- Being unable to recognize spatial locations and colors
In addition to limitations, OpenAI identified, researched, and attempted to mitigate several risks associated with the model. For example, GPT-4 avoids identifying a specific person in an image and does not respond to prompts pertaining to hate symbols.
With that said, there is further work to be done in model safeguarding. For example, OpenAI notes in the model system card that “If prompted, GPT-4 can generate content praising certain lesser known hate groups in response to their symbols.”,
GPT-4 for Computer Vision and Beyond
GPT-4 is a notable movement in the field of machine learning and natural language processing. With GPT-4, you can ask questions about an image – and follow up questions – in natural language and the model will attempt to ask your question.
GPT-4 performed well at various general image questions and demonstrated awareness of context in some images we tested. For instance, GPT-4 was able to successfully answer questions about a movie featured in an image without being told in text what the movie was.
For general question answering, GPT-4 is exciting. While models existed for this purpose in the past, they often lacked fluency in their answers. GPT-4 is able to both answer questions and follow up questions about an image and do so in depth.
With GPT-4, you can ask questions about an image without creating a two-stage process (i.e. classification then using the results to ask a question to a language model like GPT). There will likely be limitations to what GPT-4 can understand, hence testing a use case to understand how the model performs is crucial.
With that said, GPT-4 has its limitations. The model did “hallucinate”, wherein the model returned inaccurate information. This is a risk with using language models to answer questions. Furthermore, the model was unable to accurately return bounding boxes for object detection, suggesting it is unfit for this use case currently.
We also observed that GPT-4 is unable to answer questions about people. When given a photo of Taylor Swift and asked who was featured in the image, the model declined to answer. OpenAI define this as an expected behavior in the published system card.
Interested in reading more of our experiments with multi-modal language models and GPT-4’s impact on computer vision? Check out the following guides:
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher, Piotr Skalski. (Sep 27, 2023). GPT-4 with Vision: Complete Guide and Evaluation. Roboflow Blog: https://blog.roboflow.com/gpt-4-vision/