23 Jun 2026 • 9 min read Synthetic Image Generation in Roboflow Workflows with Stability AI In this guide, learn how to use Roboflow to generate synthetic data with DALL-E and GPT-4 Vision for use in training vision models.
4 May 2026 • 7 min read Vision Token Counts: What does it cost to process an image with a frontier vision model? Understand the cost, per-provider tokenization rules, and a comparison across image sizes for Claude, GPT, and Gemini.
16 Mar 2026 • 5 min read Which is the Best Coding Agent for Vision tasks? SUMMARY This benchmark pits four coding agents (Claude Code with Opus 4.6, Cursor with Composer 2, Gemini CLI with Gemini 3.1 Pro, and Codex with GPT 5.4) against five computer vision tasks including bird counting with SAM 3, car counting in video and RTSP streams, avocado detection,
4 Feb 2026 • 7 min read Best Multimodal Models in 2026 From SAM 3’s record-breaking segmentation speed to Gemini 3’s massive 2-million-token context window, explore the top models that can "see," reason, and deploy in production today.
19 Nov 2025 • 6 min read Launch: Use Segment Anything 3 (SAM 3) with Roboflow SUMMARY Roboflow has integrated SAM 3, Meta's foundation model for Promptable Concept Segmentation, across every major part of its platform, covering the Playground for interactive testing, the inference API, edge and private-cloud deployment, Roboflow Workflows for building production pipelines, and the Label Assist annotation tool for accelerating
30 Sep 2025 • 9 min read How to Detect, Track, and Identify Basketball Players with Computer Vision Build a computer vision pipeline that detects, tracks, and identifies NBA players during a game. Using models like RF-DETR, SAM2, SigLIP, SmolVLM2, and ResNet, the system handles motion blur, occlusion, and uniform similarity to reliably map jersey numbers to player identities.
26 Aug 2025 • 10 min read How to Fine-Tune Qwen2.5-VL with a Custom Dataset Learn how to fine-tune Qwen2.5-VL for document processing using a custom dataset.
7 Aug 2025 • 5 min read GPT-5 for Vision: Results from 80+ Real-World Tests SUMMARY Roboflow tested GPT-5 across more than 80 structured visual tasks spanning document understanding, defect detection, object counting, and the RF100-VL object detection benchmark. On Vision Checkup, GPT-5 tied for first place with GPT o4 Mini, driven largely by strong spatial reasoning, but scored only 4 of
18 Jul 2025 • 5 min read Use Qwen2.5-VL for Zero-Shot Object Detection SUMMARY Qwen2.5-VL is an open source vision-language model available in 3B, 7B, and 72B sizes that can locate and label objects in an image from a plain-text prompt, with no labeled training data or fine-tuning required. This tutorial runs the 7B variant on a T4
23 Jun 2025 • 7 min read How to Fine-Tune a SmolVLM2 Model on a Custom Dataset Learn how to fine-tune SmolVLM2 for visual question answering using a custom dataset.
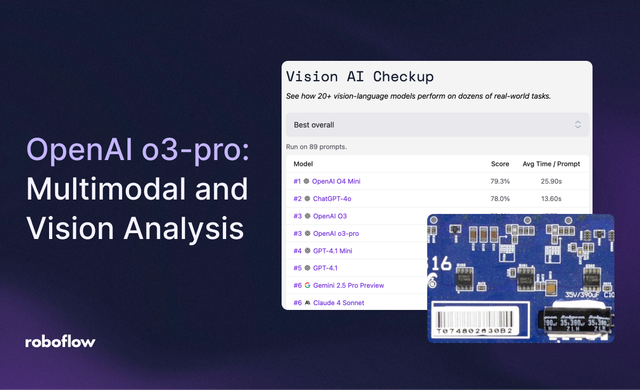
11 Jun 2025 • 4 min read OpenAI o3-pro: Multimodal and Vision Analysis Explore how OpenAI o3-pro does on a range of use cases, from defect detection to object counting to VQA.
17 Apr 2025 • 6 min read OpenAI o3 and o4-mini: Multimodal and Vision Analysis Read our analysis of how OpenAI's O3 and O4-Mini models perform on a range of vision tasks.
15 Apr 2025 • 6 min read OpenAI GPT-4.1: Multimodal and Vision Analysis Read our analysis of OpenAI's GPT-4.1 model on multimodal tasks like VQA, object detection, and more.
13 Mar 2025 • 6 min read Gemma 3: Multimodal and Vision Analysis Read our analysis of Google's Gemma-3 model and how it performs on a variety of common multimodal vision AI tasks.
13 Mar 2025 • 2 min read Foundational Few-Shot Object Detection Challenge [CVPR 2025] Roboflow & Carnegie Mellon University are releasing the second iteration of the Foundational Few-Shot Object Detection Challenge at CVPR 2025.
11 Mar 2025 • 5 min read SmolVLM2: Multimodal and Vision Analysis Read our analysis of how SmolVLM2 performs on a range of multimodal vision tasks.
11 Mar 2025 • 6 min read Moondream 2: Multimodal and Vision Analysis Read our analysis of how the multimodal Moondream 2 model performs on a range of vision tasks.
13 Feb 2025 • 8 min read OpenAI o3-mini: Vision and Multimodal Features Read our analysis of how OpenAI's O3 Mini model performs on various computer vision tasks.
2 Jan 2025 • 8 min read What is Few-Shot Learning? In this blog post, we discuss what few-shot learning is, architectural approaches for implementing few-shot learning, and specific implementations of few-shot learning techniques.
10 Dec 2024 • 13 min read How to Fine-tune PaliGemma 2 Learn how to fine-tune PaliGemma 2 to extract data from an image in JSON format.
16 Oct 2024 • 7 min read Launch: Use Florence-2 in Roboflow Workflows Learn how to use Florence-2 in Roboflow Workflows for zero-shot object detection, OCR, and more.
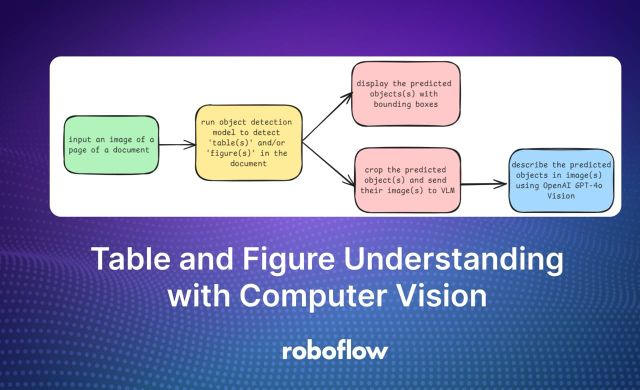
3 Sep 2024 • 7 min read Table and Figure Understanding with Computer Vision Learn how to use Roboflow Workflows and multimodal models to derive information about the contents of tables and figures.
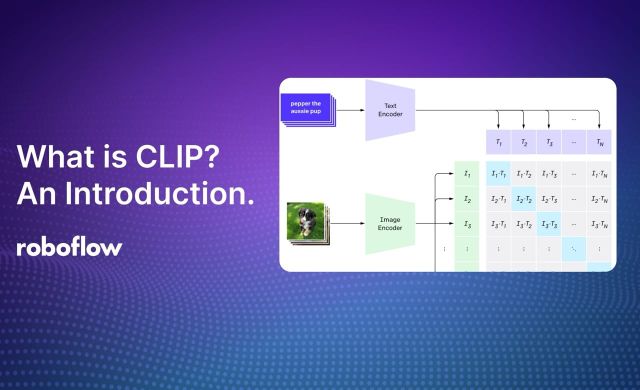
1 Sep 2024 • 15 min read What is CLIP? Contrastive Language-Image Pre-Training Explained. CLIP is an open source, multimodal computer vision model developed by OpenAI. Learn what CLIP is in this guide.
22 Jul 2024 • 7 min read How to OCR Hand-Written Notes with GPT-4 Learn how to OCR hand-written notes with GPT-4.











![Foundational Few-Shot Object Detection Challenge [CVPR 2025]](https://storage.ghost.io/c/2c/8d/2c8d8c0d-1c15-4b6d-825e-02b78d61d40a/content/images/size/w640/2025/03/img-foundational-few-shot-object-detection-challenge-1.png)