
Humans excel at identifying new objects with minimal examples. This is a feat for many machine learning methods that typically demand thousands of instances to match such proficiency.
Earlier in the last decade, computer vision research concentrated on addressing specific tasks using vast image datasets. In recent years, however, there has been greater exploration of “few-shot learning” (FSL). FSL is an inference strategy that enables you to show a few examples of an image to a pre-trained model and retrieve an accurate response to an object detection, segmentation, or classification task.
Introduction to Few-Shot Learning
In this blog post, we will discuss what few-shot learning is, architectural approaches for implementing few-shot learning, and specific implementations of few-shot learning techniques. We will also talk about how few-shot learning is applied with Large multimodal Models (LMMs).
Without further ado, let’s get started!
What is Few-Shot Learning?
Few-shot learning is a technique that lets you provide a few examples that a model can use to inform its answer to a vision task. For example, you can use few-shot learning in a classification task. You can give a model an example of each class you want to classify and the model will use this to return the probability that each provided class relates to an image. You can use few-shot learning with segmentation to help a pre-trained model identify specific objects.
Few-shot learning is a progression from zero-shot and one-shot learning. In the former, a large model is trained to identify a vast range of objects. But, zero-shot tasks don’t allow you to provide images as context, which means performance can be limited.
One-shot learning, on the other hand, allows you to provide one example of an image. This is ideal if you have some data that you want to use as a reference for the model.
With that said, few-shot learning can boost performance further than zero- and one-shot learning.
The following graphic shows how a “support set” of data can be used to inform a model with zero-shot learning:
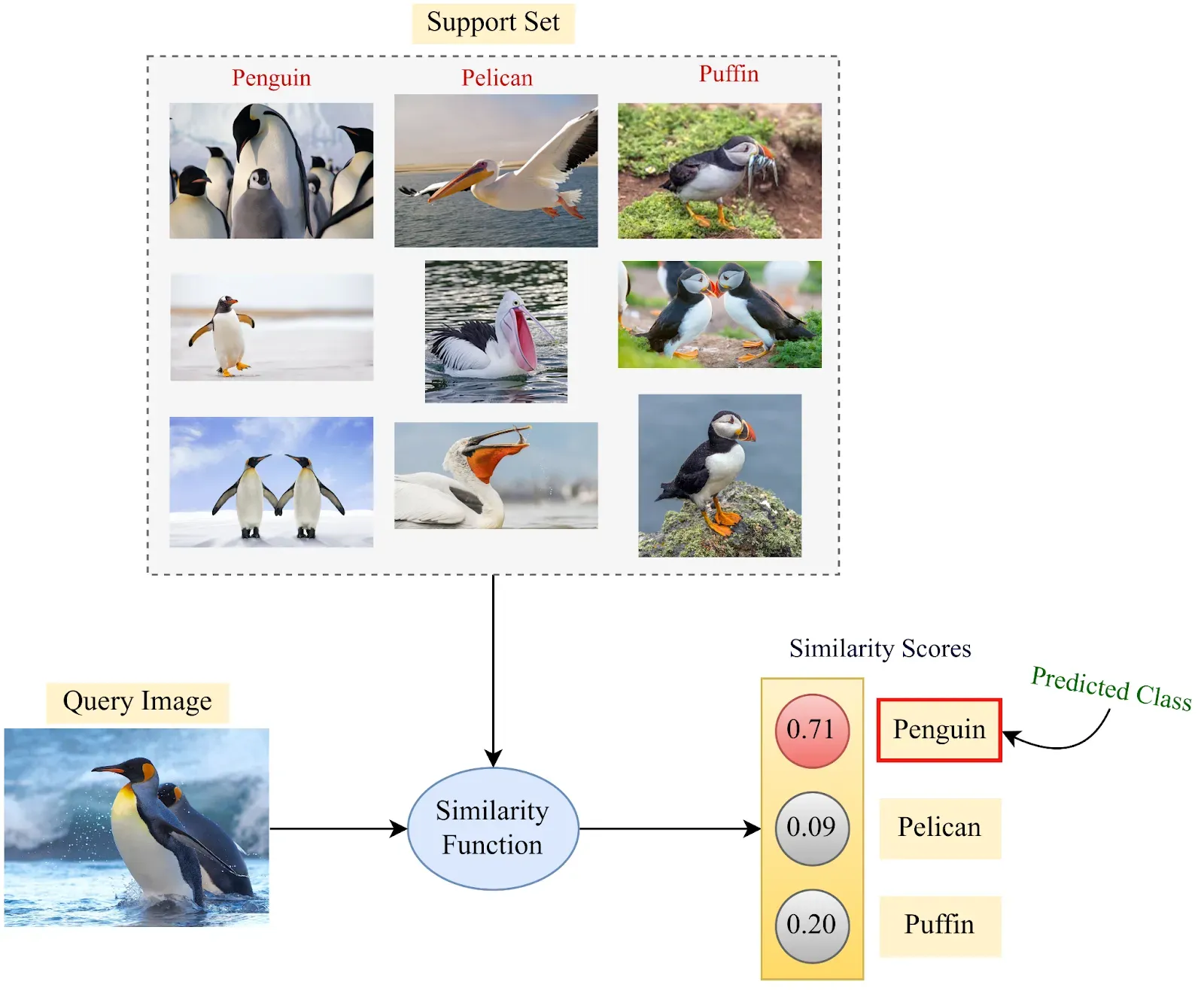
Few-Shot Learning example. Source
Few-Shot Learning Approaches
There are two main ways in which few-shot learning can be implemented in a machine learning model:
- Meta-learning
- Metric learning
Let’s talk about each of these approaches in depth.
1. Meta-Learning
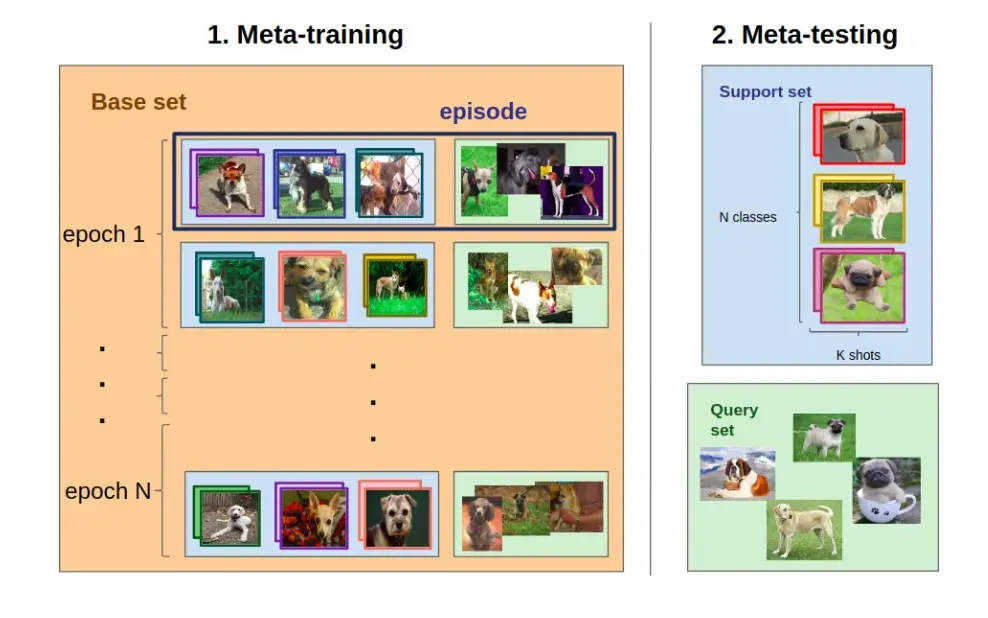
Meta-learning, also known as “learning to learn”, is a machine learning paradigm where a model is trained to perform multiple learning tasks in a way that enables it to quickly adapt to new, unseen tasks with minimal data. In the context of few-shot classification, one type of few-shot learning, meta-learning is employed to enhance the model's ability to generalize and make accurate predictions when presented with limited examples for new classes or tasks.
Here's how meta-learning is used in few-shot classification:
- Training on Diverse Tasks: In the meta-learning paradigm, the model is exposed to a variety of learning tasks during training. Each task involves a set of classes, and the model learns to adapt its parameters based on the experience gained from solving these tasks. The training process is often organized into episodes. In each episode, a subset of tasks (composed of classes and examples) is sampled from a larger dataset. This setup simulates the few-shot scenario where the model encounters new tasks with limited examples.
- Support Set and Query Set: Within each episode, the sampled tasks are divided into a support set and a query set. The support set contains examples used to update the model's parameters, while the query set is used to evaluate the model's performance. The model's parameters are adapted based on the support set examples to improve its ability to generalize to new tasks. This adaptation process is crucial for the model to efficiently learn from a few examples.
- Evaluation on Unseen data: After the model has undergone episodic training, its performance is evaluated on unseen tasks, which may have different classes or examples not encountered during training. The goal is to assess the model's generalization capabilities.
Meta-learning, with its focus on acquiring the ability to adapt to new tasks, is instrumental in addressing the challenges posed by limited labeled data in few-shot classification scenarios. It allows models to leverage prior knowledge gained from diverse tasks to perform effectively with minimal examples for novel tasks.
2. Metric Learning
Metric learning plays a pivotal role in few-shot learning within computer vision, aiming to improve the discriminatory power of feature representations. In the context of few-shot learning, where the model is tasked with recognizing objects or patterns with very limited examples, traditional methods often struggle due to the scarcity of labeled data.
Metric learning addresses this challenge by learning a similarity metric that measures the likeness between instances in the feature space.
By employing techniques such as Siamese networks or triplet networks, the model can grasp subtle differences and similarities, allowing it to generalize effectively from a few examples. This approach enhances the model's ability to distinguish between classes, enabling more robust recognition even in scenarios with minimal training samples.
The emphasis on learning a meaningful metric not only facilitates better generalization but also aligns with the fundamental goal of few-shot learning: extracting and utilizing valuable information from limited labeled data to make accurate predictions in novel situations.
Algorithms for Few-Shot in Computer Vision
In the last discussion, we discussed the high-level architectures that can be used to implement few-shot learning. Now, let’s talk about the specific algorithms used to implement few-shot learning in machine learning models.
In this section, we will discuss:
- Model-Agnostic Meta-Learning (MAML)
- Matching Networks
- YOLOMAML
Let’s get started!
1. Model-Agnostic Meta-Learning (MAML)
Model-Agnostic Meta-Learning (MAML) is a meta-learning algorithm designed to enhance the ability of machine learning models to quickly adapt and learn from new tasks with limited data.
Let’s talk about the MAML approach, step-by-step:
- Initialization: MAML begins with the initialization of a base model, typically a neural network. This initial model is trained on a set of tasks, each with a few examples.
- Task-Specific Adaptation: For each task, MAML aims to quickly adapt the base model using a small number of examples from that task. It does this by computing task-specific gradients and updating the model's parameters to better suit the current task.
- Meta-Training: After adapting to multiple tasks, the model's parameters are updated in a way that allows it to generalize well across a range of tasks. The objective is to find a set of model parameters that make it easy for the model to fine-tune quickly on new tasks.
- Meta-Testing: When faced with a new, unseen task during testing, MAML fine-tunes the base model using a minimal number of examples from the new task. The model, having learned task-agnostic representations during meta-training, is expected to quickly adapt and perform well on the new task.

The key strength of MAML is its ability to learn a set of model parameters that are conducive to fast adaptation across various tasks. By explicitly optimizing for quick adaptation, MAML addresses the challenges posed by Few-Shot Learning scenarios where labeled data is limited. This makes it particularly suitable for tasks like image classification where the model needs to generalize effectively with only a small number of examples per class.
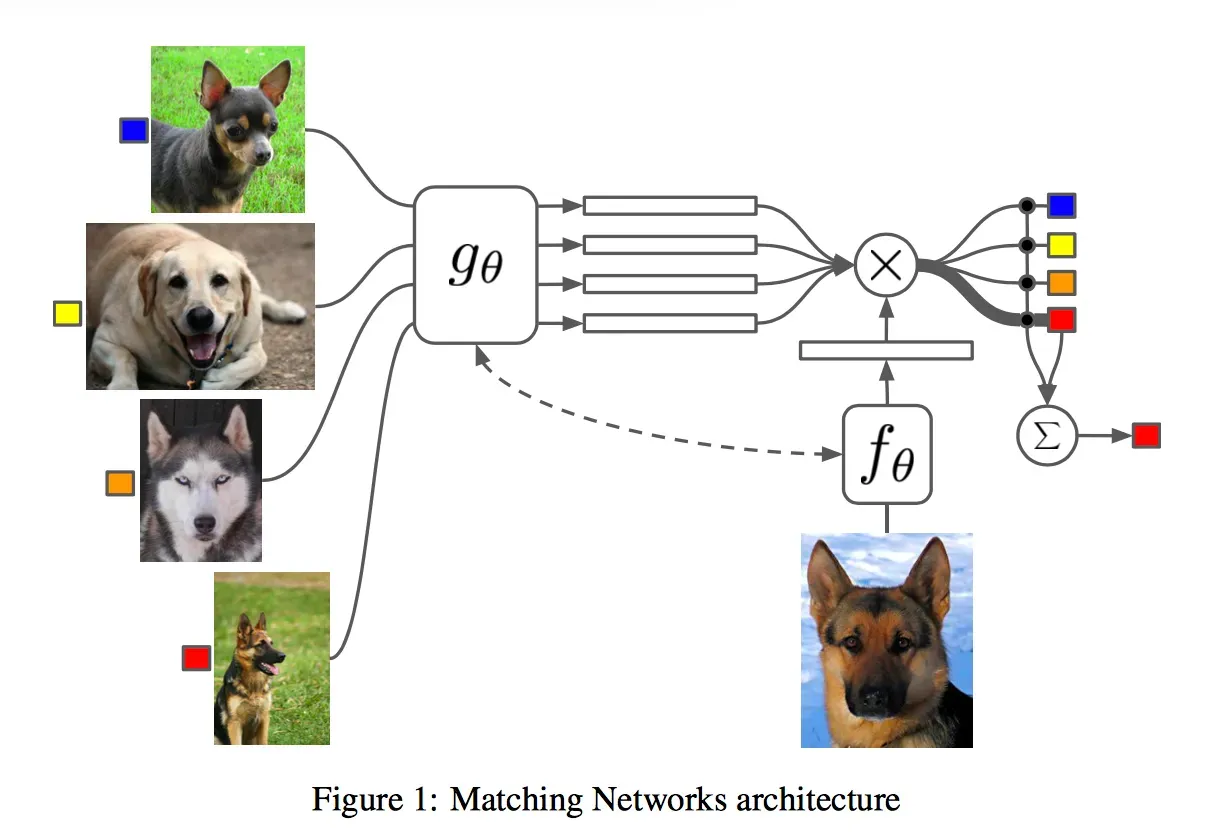
2. Matching Networks
Matching networks is another meta-learning algorithm, specifically designed for few-shot learning tasks, such as image classification where a limited number of examples per class are provided.
Let’s talk through how matching networks work, step-by-step:
- Embedding and Representation: Matching networks start by embedding input examples into a feature space using a neural network. This network is typically a convolutional neural network (CNN) for image-based tasks. The goal is to create meaningful representations for each input example.
- Similarity Computation: Matching networks compute the similarity between examples in the support set and the examples in the query set. For each example in the query set, the algorithm calculates a similarity score with each example in the support set.
- Weighted Aggregation: The computed similarity scores are used to assign weights to the examples in the support set. These weights are then used to aggregate information from the support set, giving more emphasis to examples that are more relevant to the current query.
- Classification Head: The aggregated information is passed through a classification head, typically another neural network layer, to make predictions for the query set. The model is trained to minimize the classification loss on the query set.
The entire process is performed iteratively across multiple tasks during training, allowing the model to learn a generalized way of leveraging support set information to classify examples in the query set.
3. YOLOMAML
YOLOMAML algorithm is also used for few-shot learning. YOLOMAML is a direct application of the MAML algorithm to the YOLO detector. Combining two components, the YOLOv3 Object Detection architecture and the Model-Agnostic Meta-Learning algorithm, YOLOMAML addresses the challenges of adapting object detection models to new tasks with minimal labeled data.
Few-Shot Learning with Multimodal Models
Large Multimodal Models (LMMs) such as GPT-4 with Vision support few-shot learning. This involves providing a text prompt that asks the model to take into account given images as context. Microsoft Research, in a paper analyzing GPT-4 with Vision prompting techniques, noted a performance boost on a range of vision tasks when few-shot learning is used.
Few-shot learning in LMMs is implemented differently to few-shot learning for specific tasks like classification, detection, and segmentation. Whereas you need to adjust your model architecture to use few-shot learning in classification, detection and segmentation, you need to adjust your prompt to use few-shot learning in LMMs.
Roboflow is actively working on allowing you to use few-shot learning with LMMs like GPT-4 with Vision. We expect this work to fall under Multimodal Maestro, a library that implements prompting techniques for use with LMMs. At the time of writing this post, Maestro supports Set of Mark prompting, used for zero-shot object detection and segmentation. We expect to add few-shot learning utilities in the future.
Mastering Few Shot-Learning
Few-shot learning is a pivotal paradigm enabling models to make accurate predictions with minimal labeled examples, crucial for applications where you do not have enough data to train a fine-tuned model.
Meta-learning facilitates swift adaptation to new tasks, while metric learning enhances feature representations for robust generalization with limited data.
In computer vision, specialized algorithms, like YOLOMAML, integrate YOLOv3 and MAML, offering stability in Few-Shot Object Detection.
Despite its promising ability to revolutionize how models adapt to limited data scenarios, few-shot learning remains in its early stages, requiring significant research and development efforts before it can seamlessly integrate into mainstream applications.
Simplify model building with hosted training. Try Roboflow Train for free.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Jan 2, 2025). What is Few-Shot Learning?. Roboflow Blog: https://blog.roboflow.com/few-shot-learning/