12 Jul 2024 • 4 min read Document Understanding with Multimodal Models Learn how to use the PaliGemma multimodal model to ask questions about the contents of a document.
12 Jul 2024 • 4 min read Visual Question Answering with Multimodal Models Learn how to use the PaliGemma multimodal model to ask questions about images.
12 Jul 2024 • 5 min read Understand Website Screenshots with a Multimodal Vision Model Learn how to use the Florence-2 multimodal model to generate rich descriptions of website screenshots.
12 Jul 2024 • 4 min read How to Caption Images with a Multimodal Vision Model Learn how to caption images using a multimodal vision model.
10 Jul 2024 • 5 min read How to Use Florence-2 for Optical Character Recognition Learn how to use the Florence-2 model for Optical Character Recognition tasks.
10 Jul 2024 • 5 min read What Is Dense Image Captioning? Learn what dense image captioning is and how to use the MIT-licensed Florence-2 model to generate dense image captions.
25 Jun 2024 • 12 min read How to Fine-tune Florence-2 for Object Detection Tasks This tutorial will show you how to fine-tune Florence-2 on object detection datasets to improve model performance for your specific use case.
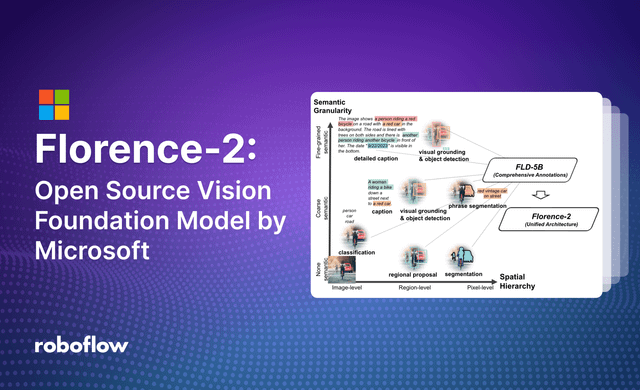
20 Jun 2024 • 5 min read Florence-2: Vision-language Model Florence-2 is a lightweight vision-language model open-sourced by Microsoft under the MIT license.
17 May 2024 • 8 min read How to Fine-tune PaliGemma for Object Detection Tasks Learn how to fine-tune the PaliGemma multimodal model to detect custom objects.
17 May 2024 • 8 min read Finetuning Moondream2 for Computer Vision Tasks In this guide, we finetune and improve Moondream2, a small, local, fast multimodal Vision Language Model, for a computer vision task.
15 May 2024 • 10 min read PaliGemma: An Open Multimodal Model by Google PaliGemma is a vision language model (VLM) developed and released by Google that has multimodal capabilities. Learn how to use it.
14 May 2024 • 10 min read GPT-4o: The Comprehensive Guide and Explanation Learn what GPT-4o is, how it differs from previous models, evaluate its performance, and use cases for GPT-4o.
26 Mar 2024 • 9 min read Ultimate Guide to Using CLIP with Intel Gaudi2 Learn how to use CLIP on the Intel Gaudi2 chip. This guide discusses training and deploying a custom CLIP model on Gaudi2.
21 Mar 2024 • 5 min read Launch: YOLO-World Support in Roboflow Learn how you can use YOLO-World with Roboflow.
16 Mar 2024 • 7 min read Best OCR Models for Text Recognition in Images See how nine different OCR models compare for scene text recognition across industrial domains.
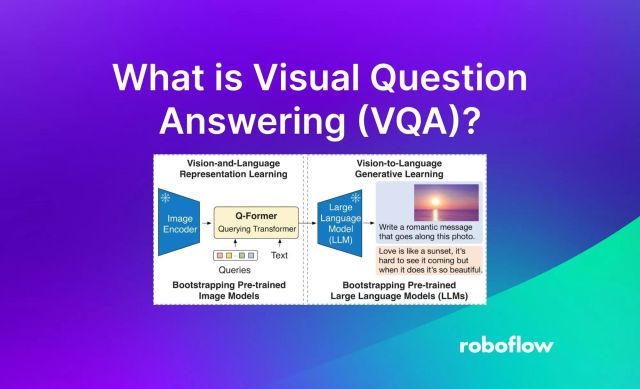
13 Mar 2024 • 10 min read What is Visual Question Answering (VQA)? Learn what Visual Question Answering (VQA) is, how it works, and explore models commonly used for VQA.
5 Mar 2024 • 7 min read First Impressions with the Claude 3 Opus Vision API The Roboflow team ran several computer vision tests using the Claude 3 Opus Vision API. Read our results.
3 Mar 2024 • 7 min read Multimodal Video Analysis with CLIP using Intel Gaudi2 HPUs Learn how to use CLIP and the Intel Gaudi2 chip to run multimodal analyses and classification on videos.
28 Feb 2024 • 9 min read Build an Image Search Engine with CLIP using Intel Gaudi2 HPUs Learn how to use the Intel Gaudi2 chip to build an image search engine with CLIP embeddings.
23 Feb 2024 • 6 min read Tips and Tricks for Prompting YOLO World Explore six tips on how to effectively use YOLO-World to identify objects in images.
20 Feb 2024 • 8 min read Build Enterprise Datasets with CLIP for Multimodal Model Training Using Intel Gaudi2 HPUs In this guide, learn how to use CLIP on Intel Gaudi2 HPUs to deduplicate datasets before training large multimodal vision models.
13 Feb 2024 • 6 min read YOLO-World: Real-Time, Zero-Shot Object Detection YOLO-World is a zero-shot, real-time object detection model.
8 Feb 2024 • 7 min read First Impressions with Gemini Advanced Read our first impressions using the Gemini Ultra multimodal model across a range of computer vision tasks.
5 Jan 2024 • 4 min read Launch: GPT-4 Checkup GPT-4 Checkup is a web utility that monitors the performance of GPT-4 with Vision over time. Learn how to use and contribute to GPT-4 Checkup