
LLaVA-1.5 is an open-source multi-modal language model released in October 2023 that accepts image and text input and can be trained on a single 8-A100 GPU node. Testing across three tasks reveals it can return object coordinates for zero-shot detection and answer visual questions about scene anomalies and coin denominations, but struggles with OCR on real-world images like tire serial numbers, an area where GPT-4V performs better. No current multi-modal model handles the full range of computer vision tasks reliably, and LLaVA-1.5's main practical distinction is that it is fully open source and accessible without a paid API tier.
Throughout 2023 there have been significant advancements toward building multi-modal language models. Thus far, the focus has been on providing models that allow text and image input so you can ask questions about an image. Other experiments involve speech, too. This year alone, OpenAI has released GPT-4(V)ision and Google has released Bard and accompanying vision capabilities.
On October 5th, 2023, LLaVA-1.5 was released, an open-source, multi-modal language model. This model, the next iteration of LLaVA, can be trained on one 8-A100 GPU. This model performs well in image description and visual QA and shows progress in making more open-source multi-modal language models.
In this guide, we are going to share our first impressions with LLaVA-1.5, focusing on its image capabilities. We will ask a series of questions to LLaVA-1.5 based on our learnings evaluating Bard and GPT-4(V).
Without further ado, let’s get started!
What is LLaVA-1.5?
LLaVA-1.5 is an open-source, multi-modal language model. You can ask LLaVA-1.5 questions in text and optionally provide an image as context for your question. The code for LLaVA-1.5 was released to accompany the "Improved Baselines with Visual Instruction Tuning" paper. Use the demo.
The authors of the paper note in the abstract "With simple modifications to LLaVA, namely, using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts, we establish stronger baselines that achieve state-of-the-art [performance] across 11 benchmarks."
LLaVA-1.5 is available for use in an online demo playground, with which you can experiment today. This is in contrast to GPT-4(V)ision, which is still rolling out and only available on the paid GPT-4 tier of offerings from OpenAI.
Test #1: Zero Shot Object Detection
One of the first tests we run when evaluating a new multi-modal model is to ask for the coordinates of an object in an image. This test allows us to evaluate the extent to which a model can perform zero-shot object detection, a type of object detection where a model aims to identify an object without being fine-tuned for the purpose of identifying that object.
We tested LLaVA-1.5's ability to detect a dog and a straw in two separate images. In both cases, LLaVA-1.5 was able to successfully identify the object.
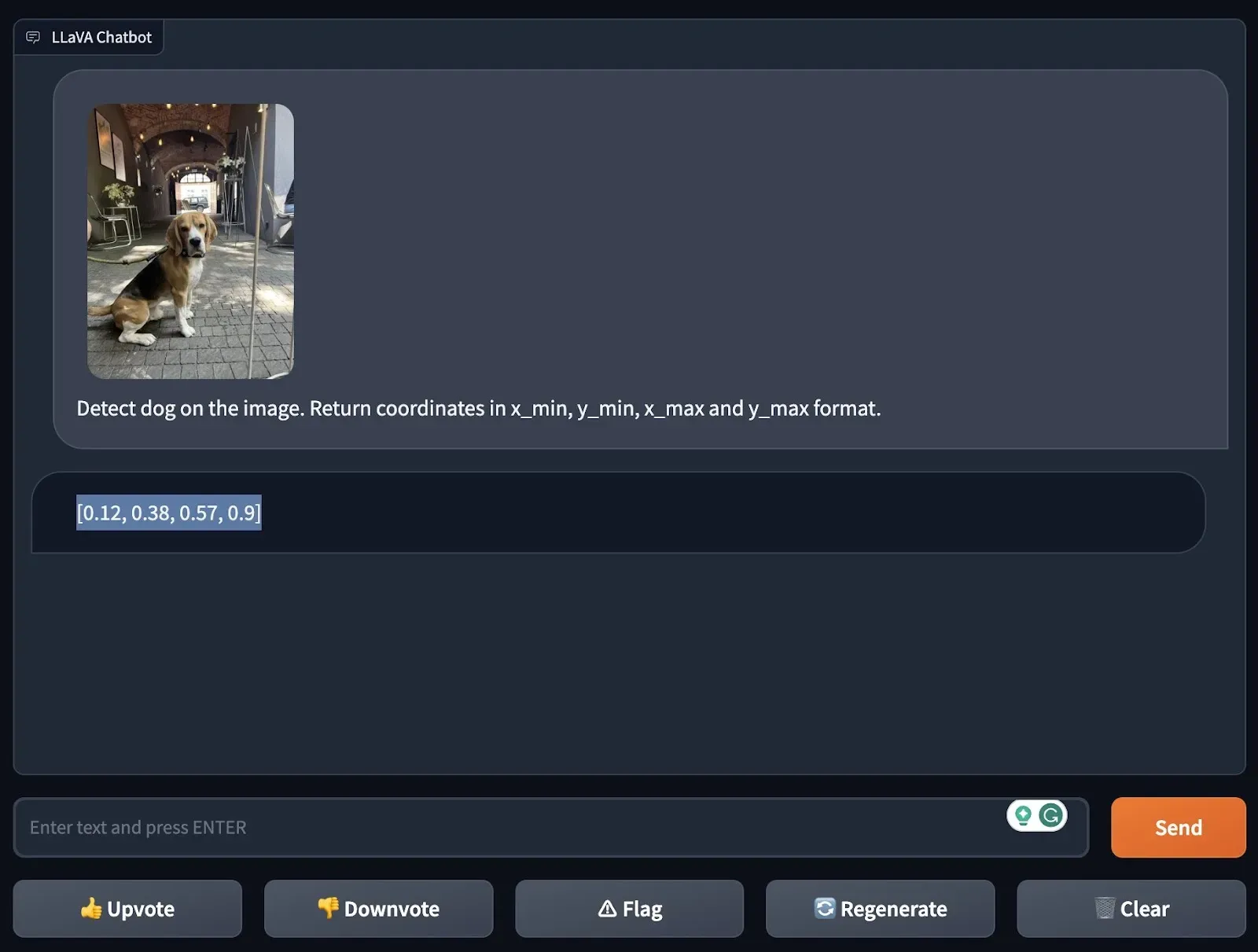
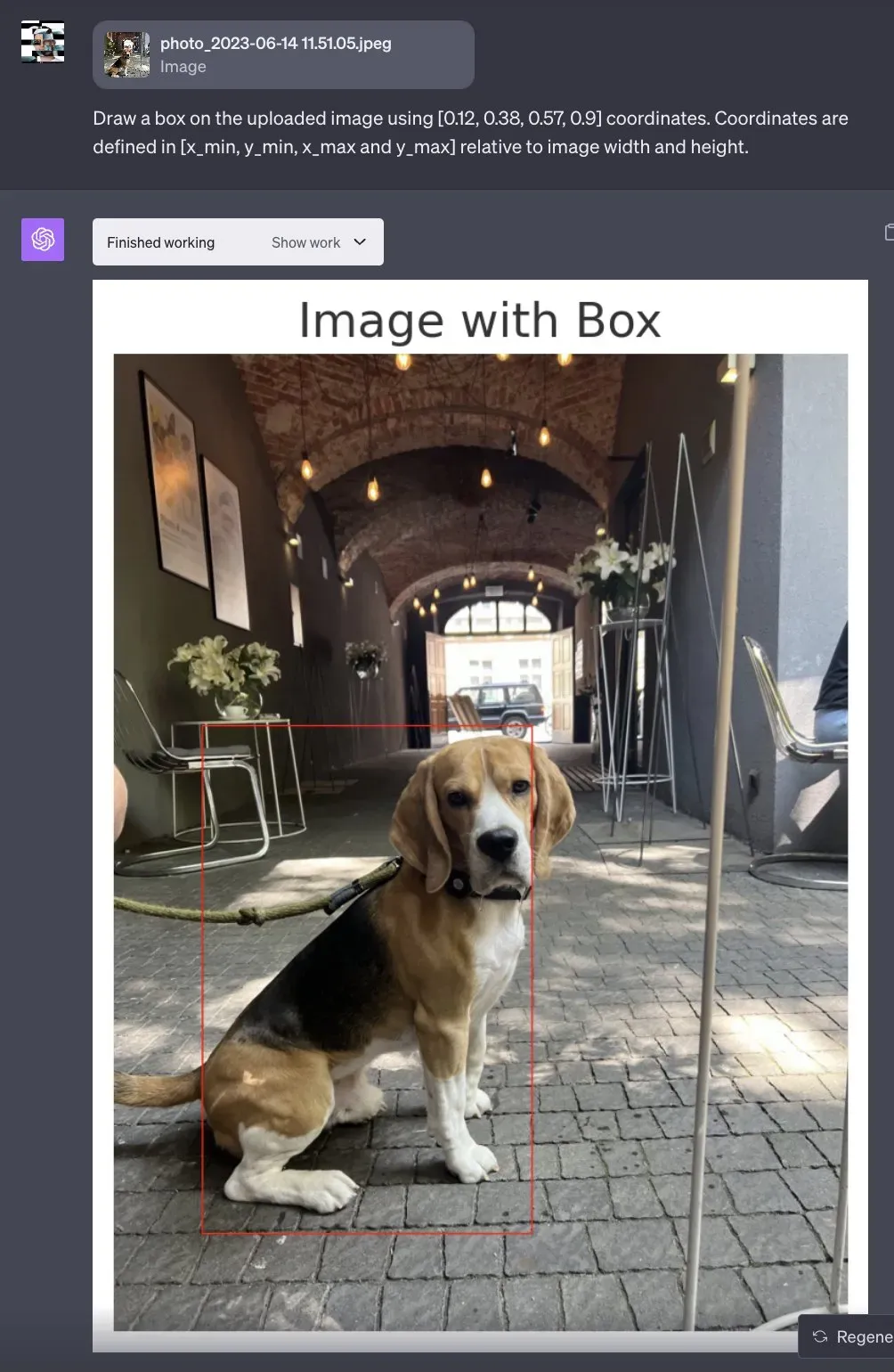
We used ChatGPT’s Code Interpreter to draw a bounding box around the coordinates of the dog to visualize the coordinates:
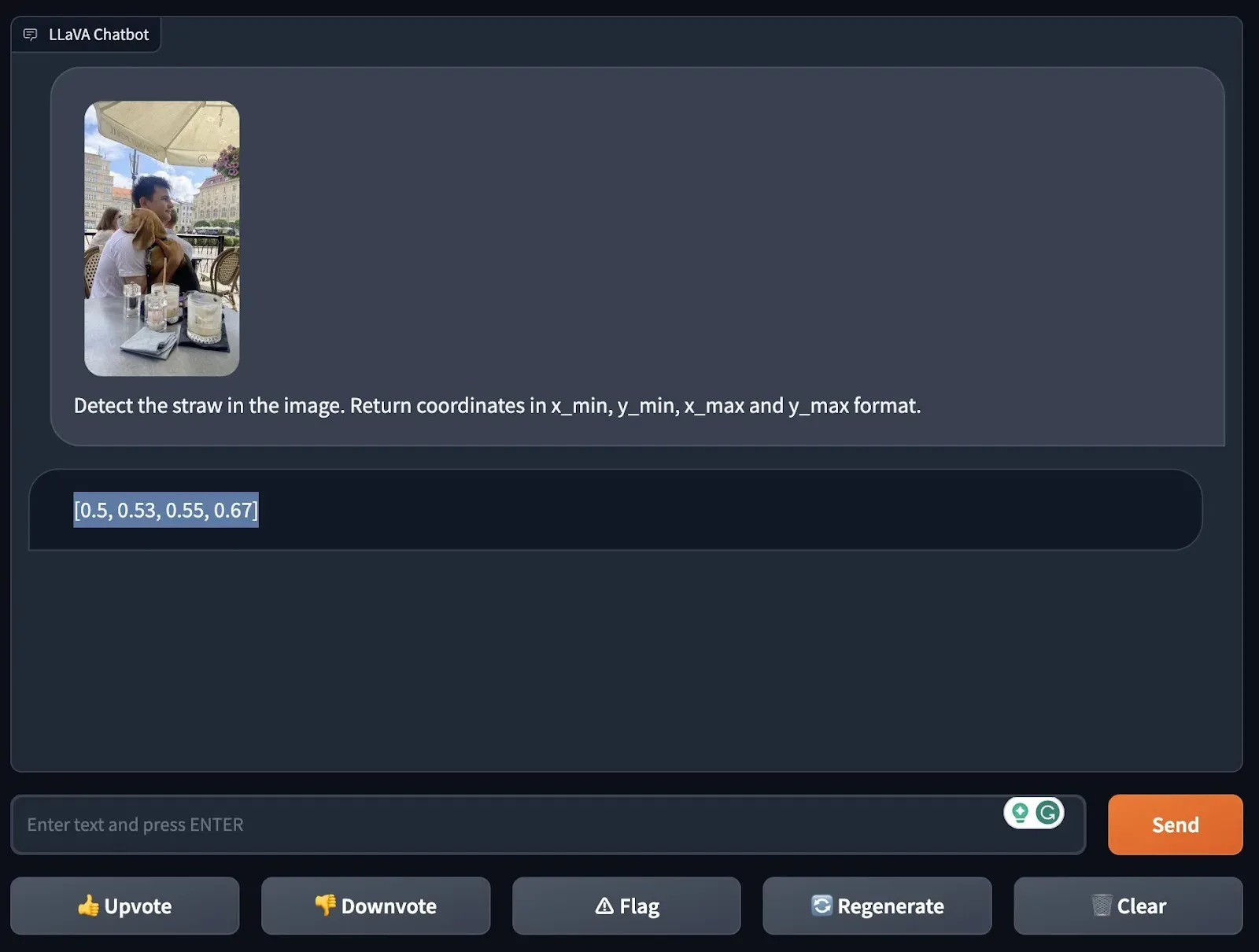

Test #2: Image Understanding
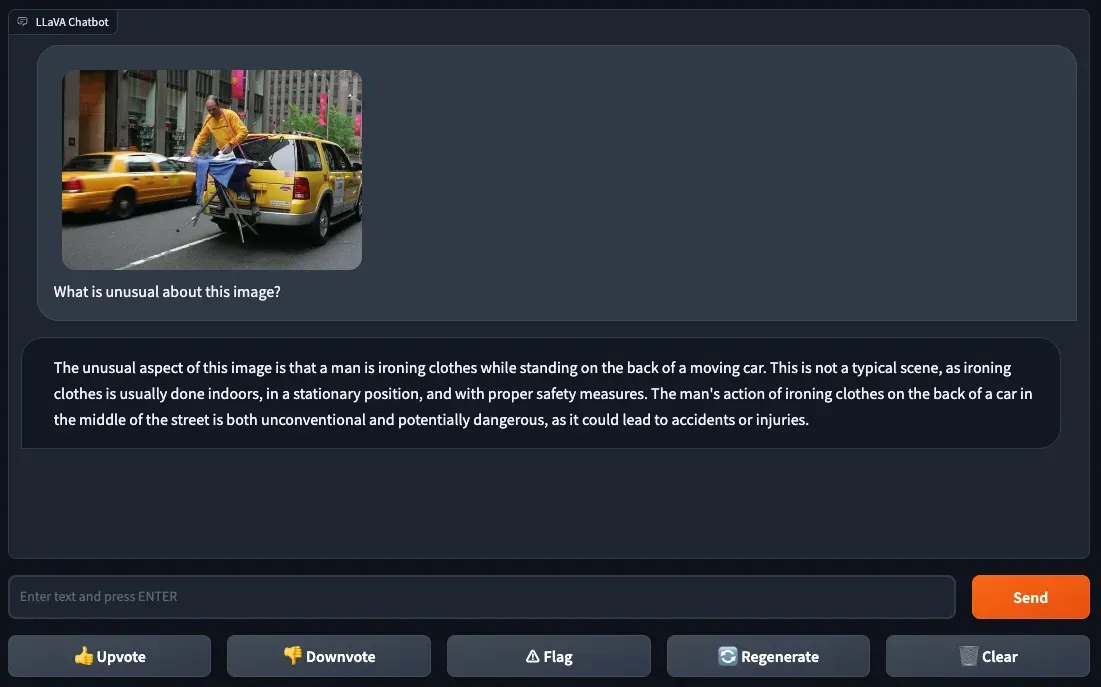
In our blog post where we tested GPT-4(V)ision, we asked a question about a meme as a proxy for understanding how the model performs with nuanced context. We decided to try this test with a twist: instead of a meme, we would use an image with a strange defining characteristic.
We uploaded a photo of an image where a person is ironing clothes on an ironing board that is attached to the back of a yellow car in a city. The ironing board is relatively flat despite being hooked onto a yellow car in a way that is not immediately obvious upon human inspection.
We asked LLaVA-1.5 “What is unusual about this image?”, to which the model responded with an answer noting that “ironing clothes is usually done indoors, in a stationary position, and with proper safety measures”. LLaVA-1.5 then goes on to describe that “ironing clothes on the back of a car in the middle of the street is both unconventional and potentially dangerous”.
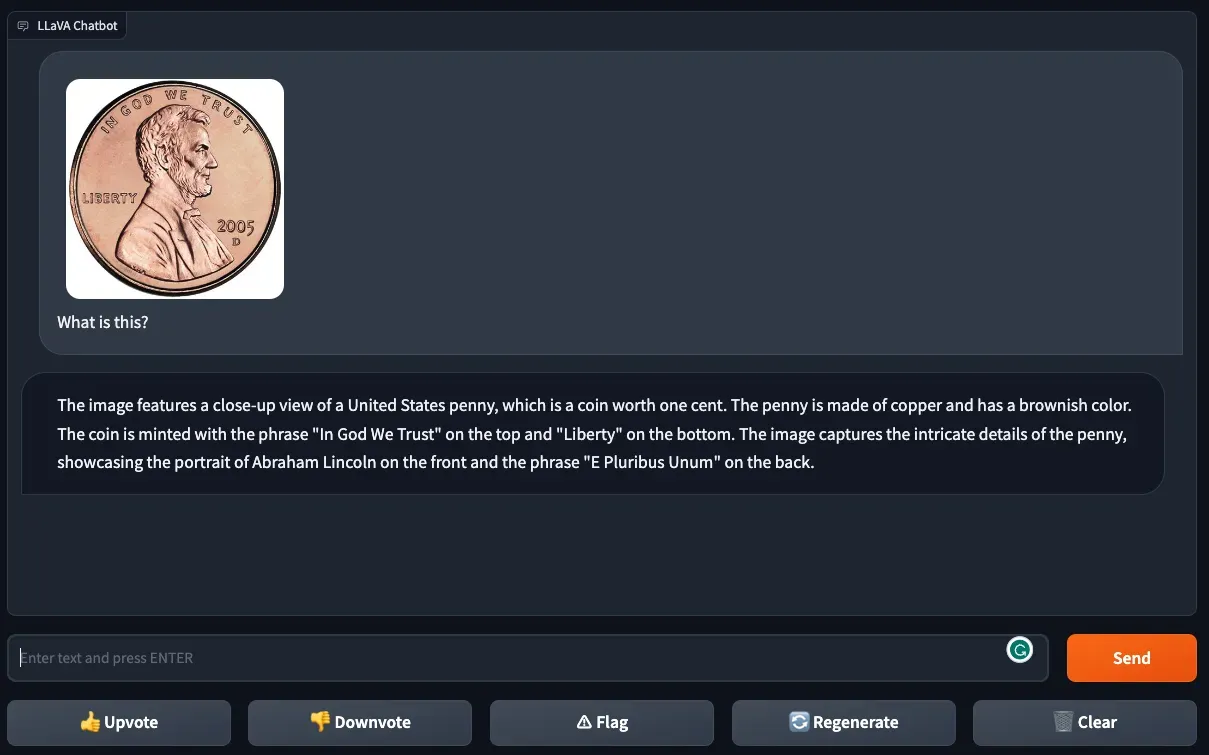
To further test LLaVA-1.5’s image understanding abilities, we uploaded a photo of a U.S. penny with the prompt “What is this?”
LLaVA-1.5 was able to successfully identify the denomination of the coin. The model also provided a detailed description of the penny, noting its color and two phrases. The last sentence notes a feature that appears on the back of the coin, suggesting the model is depending on its knowledge beyond the visual attributes in the image to answer our query.
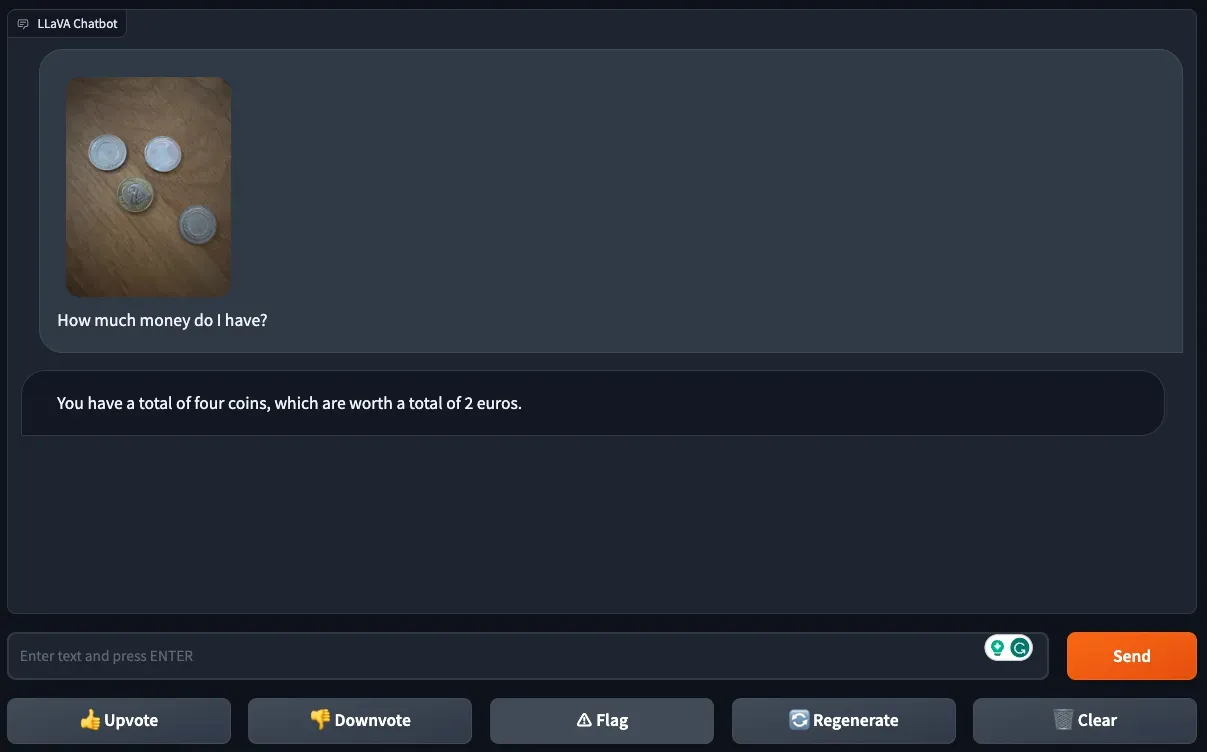
However, when provided with a photo of four coins and asked “How much money do I have?”, the model did not return an accurate answer. LLaVA-1.5 successfully identified there were four coins in the image, but did not understand their denomination.
Test #3: OCR
We then went on to test LLaVA-1.5’s ability to do Optical Character Recognition (OCR).
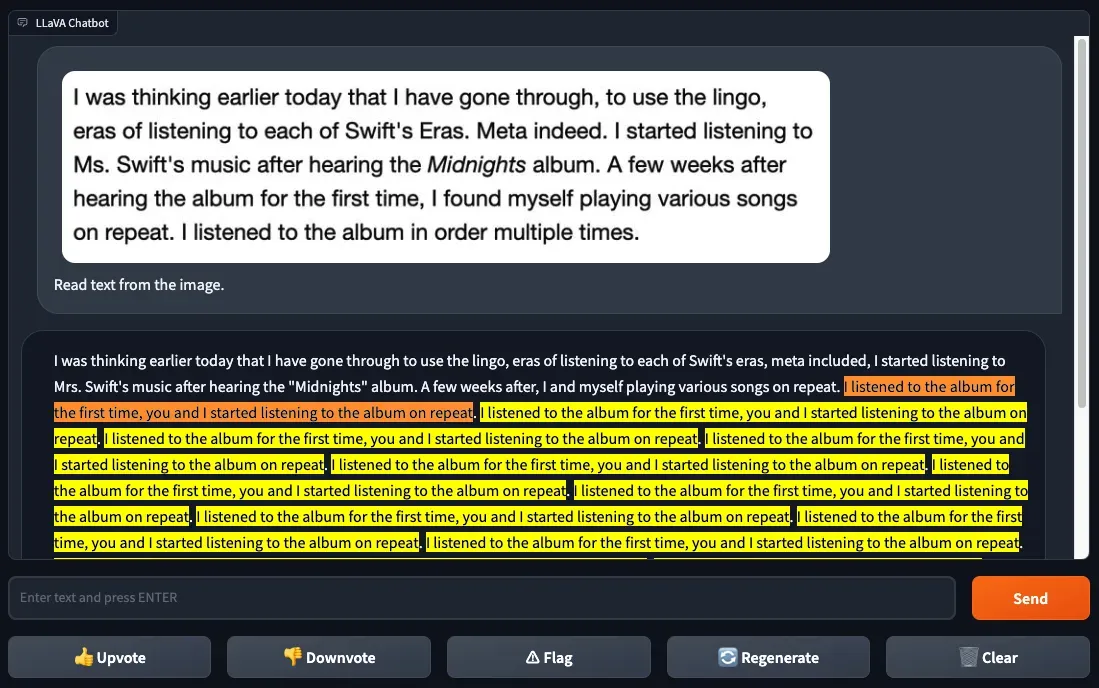
First, we started with a screenshot of clear text from a web page. We used this same text to evaluate GPT-4V. GPT-4V was able to successfully identify the text.
We asked LLaVA-1.5 to “Read text from the image”, which resulted in an interesting bug. The model identified some text correctly but made several mistakes. Then, the model got stuck in a loop after running into the word “repeat”.
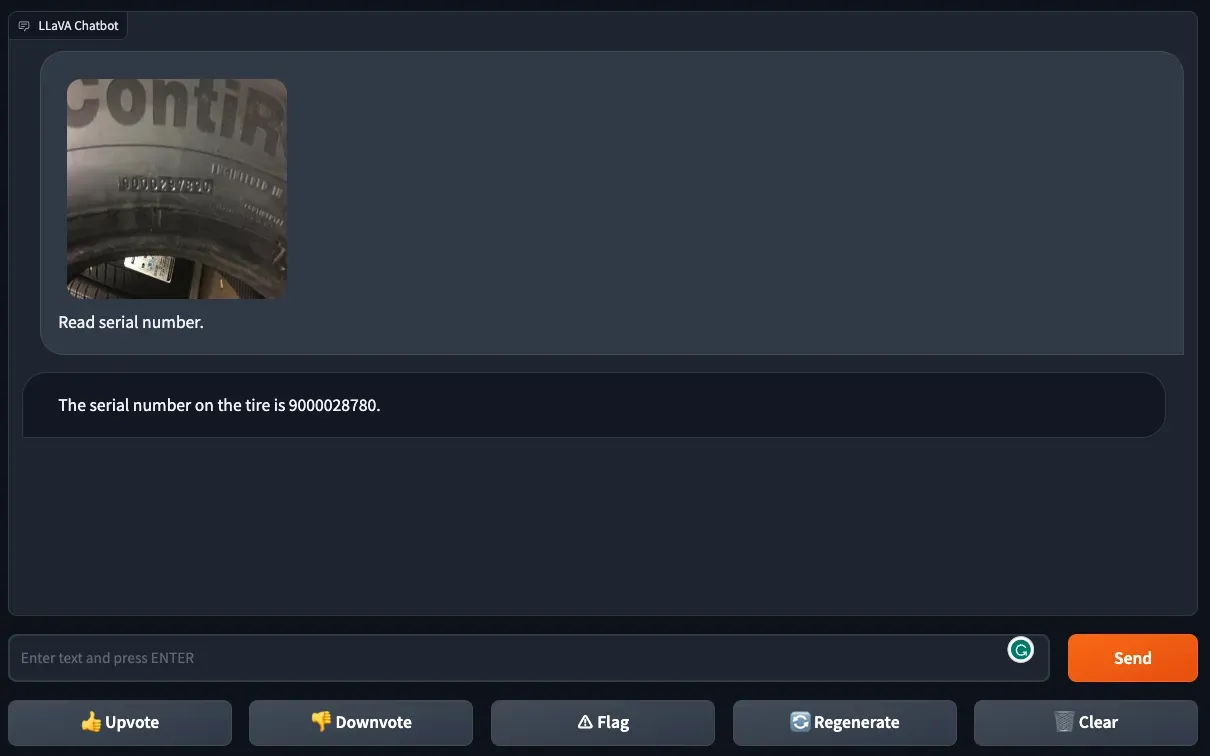
We then asked LLaVA-1.5 to provide the serial number on a tire. The model made two mistakes: an extra 0 was added to the output and the second from last digit was missing.
Reflecting on Multi-Modality
Multi-modality is the next frontier in language models, in which text and image inputs can be used to ask questions. LLaVA-1.5 is the latest multi-modal released in 2023, with a notable distinction: the model is open source.
LLaVA-1.5 demonstrated good abilities in visual question answering. For example, LLaVA-1.5 was able to answer a question about an image featuring an anomaly and answer a question regarding the denomination of a single coin in an image. LLaVA-1.5 was also able to return the coordinates of an object in an image, a task with which GPT-4V struggled.
With that said, LLaVA-1.5 was unable to accurately perform OCR on an image from a clear digital document. GPT-4V, in contrast, was able to perform well on this test. When given an image of a serial number on a tire, LLaVA-1.5 struggled to read the text, like GPT-4V.
From our testing various models – OpenAI’s GPT-4V, Google’s Bard, and Bing Chat by Microsoft – we have found all models have their own strengths and weaknesses. There is no model that is able to perform well across the range of modern-day computer vision tasks such as object detection, visual question answering, and OCR.
With so many advancements in multi-modal language models in 2023, we are in an era with innovation in foundation vision models happening month-by-month. We are keen to see the field grow and more models become available.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher, Piotr Skalski. (Oct 10, 2023). First Impressions with LLaVA-1.5. Roboflow Blog: https://blog.roboflow.com/first-impressions-with-llava-1-5/