
Google Bard's image input capabilities, tested against counting, object detection, and classification tasks using datasets from Roboflow Universe, fall short of Bing/GPT-4 for structured computer vision work. Bard refuses images containing human faces entirely rather than blurring them, and it undercounts objects even in straightforward scenes. Its strongest area is zero-shot image captioning and classification, making it better suited to general consumer search than to developer or industrial computer vision pipelines.
Google Bard Accepts Images in Prompts
Google’s large language model (LLM) chatbot Bard recently unveiled a feature to accept image prompts, making it multimodal. It strikes comparisons with a similar feature recently released from Microsoft’s Bing chat, powered by OpenAI’s GPT-4.
In our review of Bing’s multimodality, we concluded that although it had good image context and content awareness, as well as captioning and categorization, Bing lacks in its ability to perform task-specific object localization and detection tasks.
In this article, we will examine how Bard’s image input performs, how it stacks up against GPT-4, and how we believe it works.
Testing Bard’s Image Capabilities
Using the same tests as the ones performed on Bing Chat, we asked Bard questions using three different datasets from Roboflow Universe to assess the performance of Bard:
- Counting People: Hard Hat Workers Universe dataset
- Counting Objects: Apples Universe dataset
- Captioning/Classification: ImageNet
Counting People with Google Bard
In this task, we used the Hard Hat Workers dataset to ask Bard to count the number of people present in an image to determine how it performs in counting tasks. Unfortunately, Bard was unable to count any image of people
This highlights a notable difference between Bard’s capabilities and those of Bing in how it handles humans. Both take extensive efforts to ensure human faces are not used as input into the model. While Bing selectively blurs faces, Bard rejects the input of images containing human faces entirely.
Google’s care to avoid responding to human images also prevents Bard’s usability to some extent. Not only does Bard refuse any image with a human as the main subject figure, but it also makes attempts to refuse any image with a human present, significantly narrowing the number of images that can be used with it.
Counting Objects with Bard
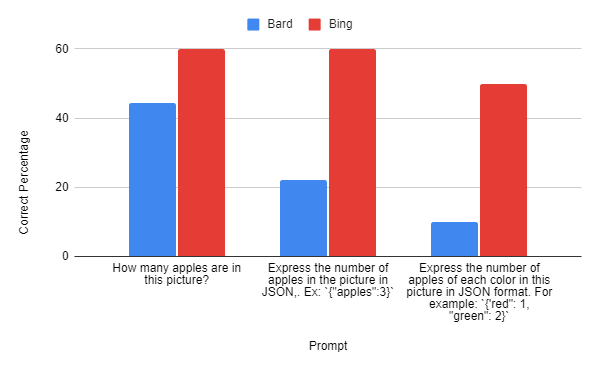
For this task, we used the apples dataset to ask Bard to count the number of apples that exist in an image. We extend this to three different prompts of increasing difficulty to assess Bard’s quantitative and qualitative deduction skills, as well as its ability to format data in a structured way.
Bard was able to complete this task but with unimpressive results:

Bard had a lot of difficulty telling the number of objects in an image, which only got worse when asked to structure the data or sort it by qualitative characteristics.
Can Bard Understand Images from ImageNet?
For this task, we present Bard with a series of images from ImageNet, an image classification benchmark dataset, and ask it to caption it with a label.
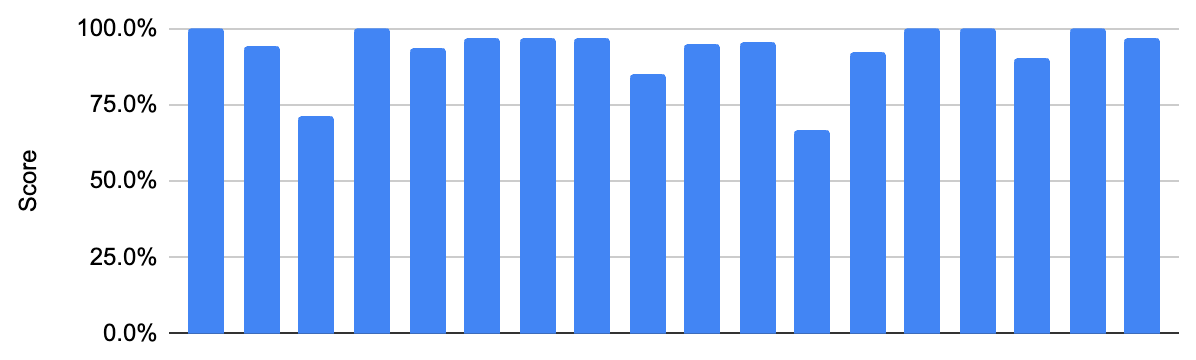
Labels getting an exact match will receive a 100% and any assigned label that isn’t an exact match will receive a semantic similarity score (similarity based on meaning) from 0-100%.
In this regard, Bard performed incredibly well, getting an average of 92.8%, with five exact matches and low variability, demonstrating its ability to consistently and accurately detect and communicate the content of an image. We didn’t test Bard on the full dataset, but the performance here is quite impressive compared to state-of-the-art model results.
How Bard Compares With Bing/GPT-4
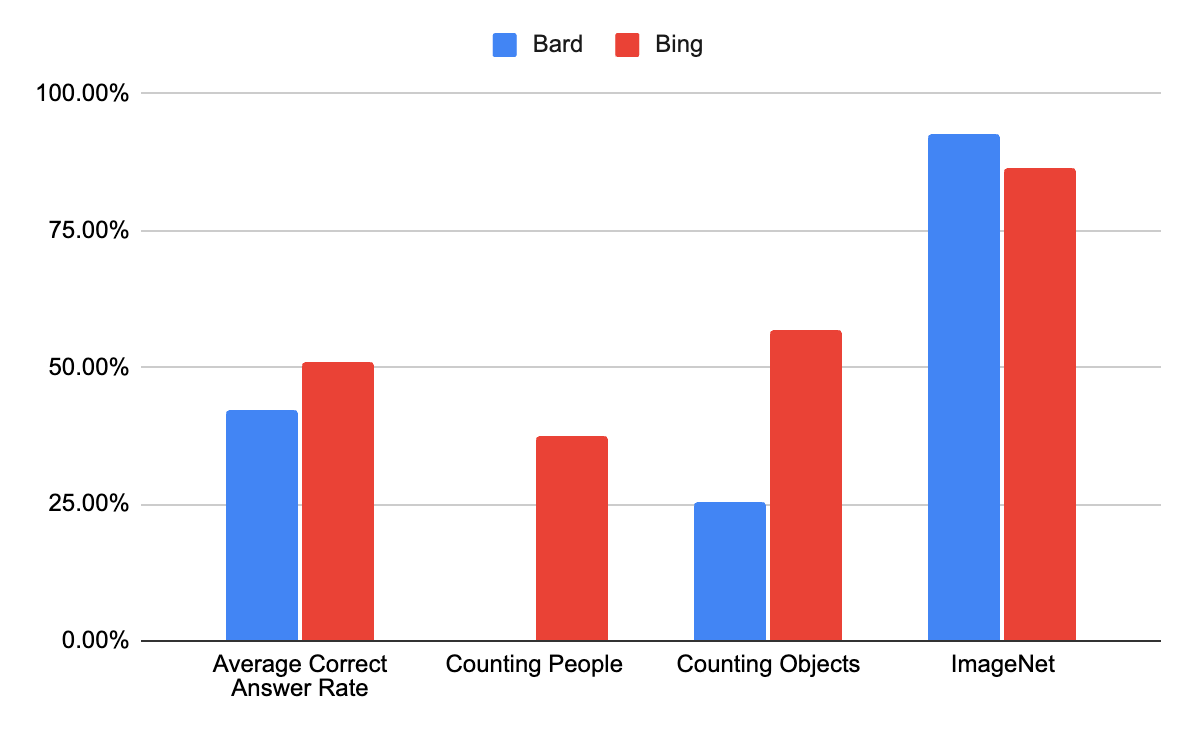
After previously performing the same tests on the GPT-4 powered Bing chat, we compiled and compared the performance of both LLMs.
One notable comparison is between Bing and Bard on the object counting task. Although Bard was able to complete some of the given tasks, it performed consistently poorly both generally and relative to Bing. Unlike Bing, Bard struggled even further when tasked with structuring the data or categorizing counts based on qualitative traits.
On the other hand, on the ImageNet classification/captioning task, Bard performed slightly better than Bing, performing 6.29% better than Bing. Despite that, Bard did perform generally worse than Bing, even when excluding the failed people counting task.
Thoughts on How Bard Might Work
After conducting our tests, we examined how it performed and inferred how it might work.
As Google stated in its release notes, Bard’s new image input features are not exactly a singular multimodal model. Rather, it is based on Google Lens, which uses a combination of multiple Google features and capabilities. It integrates many of Google’s products like Search, Translate, and Shopping.
Although unconfirmed, we believe that it uses Google Cloud’s Vision API that acts similarly to many of Google Lens’ capabilities, including its impressive OCR accuracy and ability to identify image content and context, being able to extract text and assign labels based on image content.
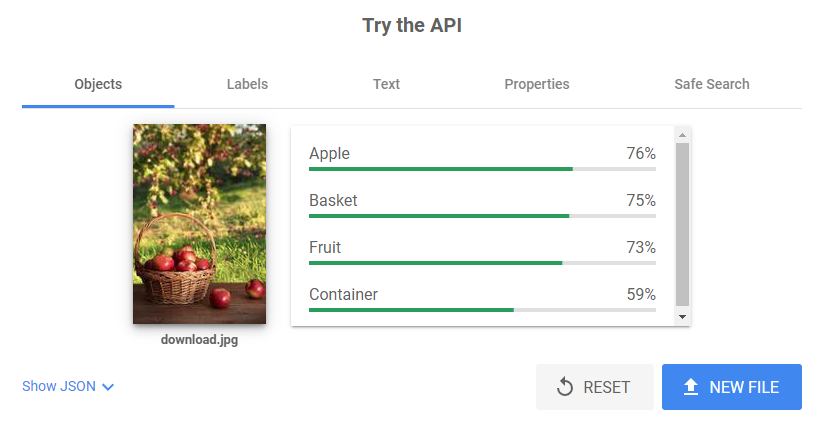
As seen in the example image, this could somewhat explain the inaccuracies that Bard made that were present in our testing, recognizing one apple, one fruit, one container, and one basket.
Conclusion
After experimenting with and examining Bard, computer vision tasks are not a strong use case yet, and as we concluded with Bing’s chat features, the main use case for Bard is likely for direct consumer use rather than computer vision tasks. The image context information, supplemented by the general knowledge of the LLM and Google’s other capabilities, will likely make it a very useful tool for generalized search and lookup of information.
Beyond that, any use for Bard in an industrial or developer context would likely be in zero-shot image-to-text, general image classification, and categorization since Bard, similar to GPT-4, was seen to perform incredibly well on image captioning and classification tasks with no training.
Models such as Bard have a lot of powerful, generalized information. But, running inference on it can be expensive due to the computation that Google has to do to return results The best use case for developers and companies might be to use the information and power of these large multimodal models to train smaller, leaner models as you can do with Autodistill.
Cite this Post
Use the following entry to cite this post in your research:
Leo Ueno. (Jul 21, 2023). Prompting Google Bard with Images & How it Compares to Bing. Roboflow Blog: https://blog.roboflow.com/using-google-bard-with-images/