
ImageNet is the foundational large-scale dataset that shaped modern computer vision research, built from images crawled and validated via Amazon Mechanical Turk to populate the WordNet concept hierarchy. The ILSVRC subset (1.28 million training images across 1,000 classes) became the standard benchmark for image classification and the primary pretraining corpus for deep learning models before fine-tuning on custom domains. Understanding its structure, statistics, and role in pretraining and benchmarking is useful context for anyone working with pretrained computer vision backbones.
The ImageNet dataset is long-standing landmark in computer vision.
The impact ImageNet has had on computer vision research is driven by the dataset's size and semantic diversity.
Let's dive into the ins and outs of the ImageNet dataset.
ImageNet Dataset Creation
The ImageNet dataset was created by a group of professors and researchers at Princeton, Stanford, and UNC Chapel Hill.
ImageNet was originally formed with the goal of populating the WordNet hierarchy with roughly 500-1000 images per concept. Images for each concept were gathered by querying search engines and passing candidate images through a validation step on Amazon Mechanical Turk.

Over the years, ImageNet has gained popularity as a large scale training corpus in computer vision, and also as an evaluation benchmark.
The subset of the ImageNet dataset, ImageNet Large Scale Visual Recognition Challenge (ILSVRC), has become the most popular subset of the dataset consisting of 1000 object classes to benchmark image classification algorithms.
ImageNet Dataset Statistics
ILSVRC
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is the most commonly used subset of the ImageNet dataset. Within this subset:
- ImageNet contains 1,281,167 training images
- ImageNet contains 50,000 validation images
- ImageNet contains 100,000 test images
- ImageNet contains 1000 object classes
{0: 'tench, Tinca tinca',
1: 'goldfish, Carassius auratus',
2: 'great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias',
3: 'tiger shark, Galeocerdo cuvieri',
4: 'hammerhead, hammerhead shark',
5: 'electric ray, crampfish, numbfish, torpedo',
6: 'stingray',
7: 'cock',
8: 'hen',
9: 'ostrich, Struthio camelus',
10: 'brambling, Fringilla montifringilla',The first 10 class labels for the 1000 imageNet object classes
ImageNet Applications
Pretraining
Until recent work such as CLIP, ImageNet and COCO have provided the main backbone for pre-training in computer vision. During pre-training, the deep learning algorithm learns to extract features from the images that are relevant, generally. Then, during finetuning on a custom dataset, the pretrained network is honed into a specific domain of interest.
Benchmarking
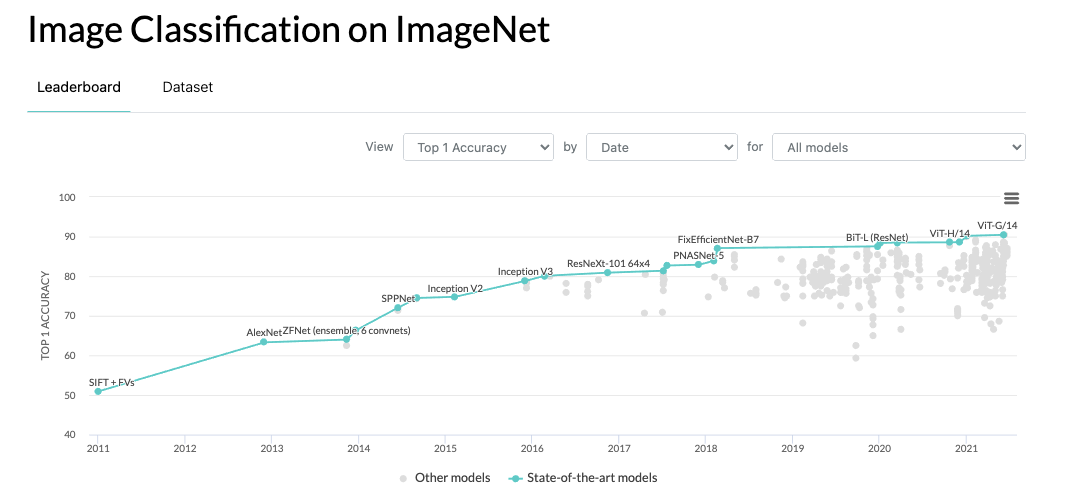
ImageNet has provided solid foundation for benchmarking advancements in computer vision research, and particularly for image classification.
Download ImageNet
The ImageNet dataset is hosted on the ImageNet's team website here. The ILSVRC subset is available on Kaggle here.
Conclusion
Thanks for reading our rundown on the ImageNet dataset. ImageNet is a large, semantically diverse dataset that powers research and development in computer vision. ImageNet is popularly known as an image classification benchmark and pretraining corpus.
As always, happy training!
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Jun 28, 2021). An Introduction to ImageNet. Roboflow Blog: https://blog.roboflow.com/introduction-to-imagenet/