
GPT-4 multimodality, tested through Bing Chat using datasets from Roboflow Universe, performs well at image captioning and classification but struggles with tasks that require precise structured outputs like bounding boxes or accurate object counts. For now, task-specific computer vision models still outperform GPT-4 on industrial-grade detection and localization work. A practical middle path is using large multimodal models to generate training data for smaller, more efficient models via tools like Autodistill.
GPT-4, the latest iteration in the GPT series of models maintained by OpenAI, is capable of responding to multimodal queries. Multimodal queries use text and images. But, up until recently, multimodal queries were not available for public use. Now, Microsoft has slowly started rolling out image input options in its Bing Chat where you can now upload images.
In our blog from when GPT-4 first released, we speculated that GPT-4 will perform well at unstructured qualitative understanding tasks (such as captioning, answering questions, and conceptual understanding), have a difficult time with extracting precise structured information (like bounding boxes) and unsure of how well localization, counting, and pose-estimation tasks would perform.
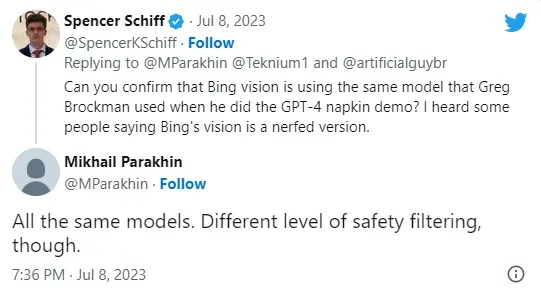
Bing's chat feature, released in May, uses GPT-4 for its text responses, and was recently confirmed (twice) by Mikhail Parakhin, CEO of Advertising and Web Services at Microsoft, that Bing's image input features are also powered by GPT-4.
In this blog post, we will discuss how well Bing, and by extension GPT-4's, combination of text and image input ability performs. We will review what Bing Chat is good at, what it’s bad at, and how it’ll affect computer vision as a whole.
Testing Bing’s Multimodality Capabilities
We asked Bing questions using images from three different publicly-available datasets from Roboflow Universe to assess, qualitatively, the performance of Bing:
- Counting People: Hard Hat Workers Universe dataset
- Counting Objects: Apples Universe dataset
- Captioning/Classification: ImageNet
Counting People
Our first test is to count people in an image using the hard hat workers dataset. Computer vision enthusiasts know counting objects is not a trivial task and is a difficult problem to solve even with custom-trained models. To test both the accuracy and variability of both the model itself and how it’s affected by various prompts, we wrote four prompts of increasing complexity:
- Count the number of people in this picture (Simple unstructured question/answer)
- How many people are in this picture? (Simple unstructured question/answer)
- Express the number of people in the picture in JSON,. Ex: `{"people":3}` (Simple question/answer in structured format)
- What are the normalized x/y center points and width, height of each person expressed in JSON format `{"x":0.000,"y":0.000,"width":0.000,"height":0.000}` (Advanced, precise structured data extraction)
We tested with ten randomly selected images to test each prompt with to get a representative sample. What we found was the following:
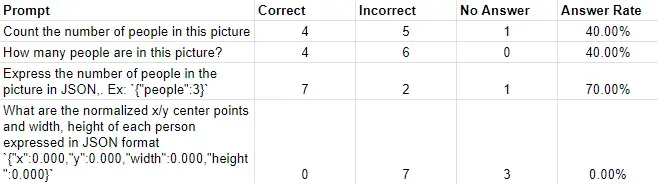
The model was subpar at counting the number of people that were present in an image. Surprisingly, asking the model for a simple structured format (in the form of a JSON) worked much better than most other prompts. With that said, Bing could not extract exact locations or bounding boxes, either producing fabricated bounding boxes or no answer at all.
Unlike in statistics used in computer vision, which calculates precision based on some amount of overlap with the ground truth, our test had two conditions: a correct bounding box or an incorrect bounding box. Although there were far-off inaccuracies when identifying objects, most inaccuracies were 1-2 objects off.

Although, Bing’s poor performance may be attributed to a feature that blurs faces, removing one of the recognizable attributes of people, leading to decreased effectiveness of counting people.
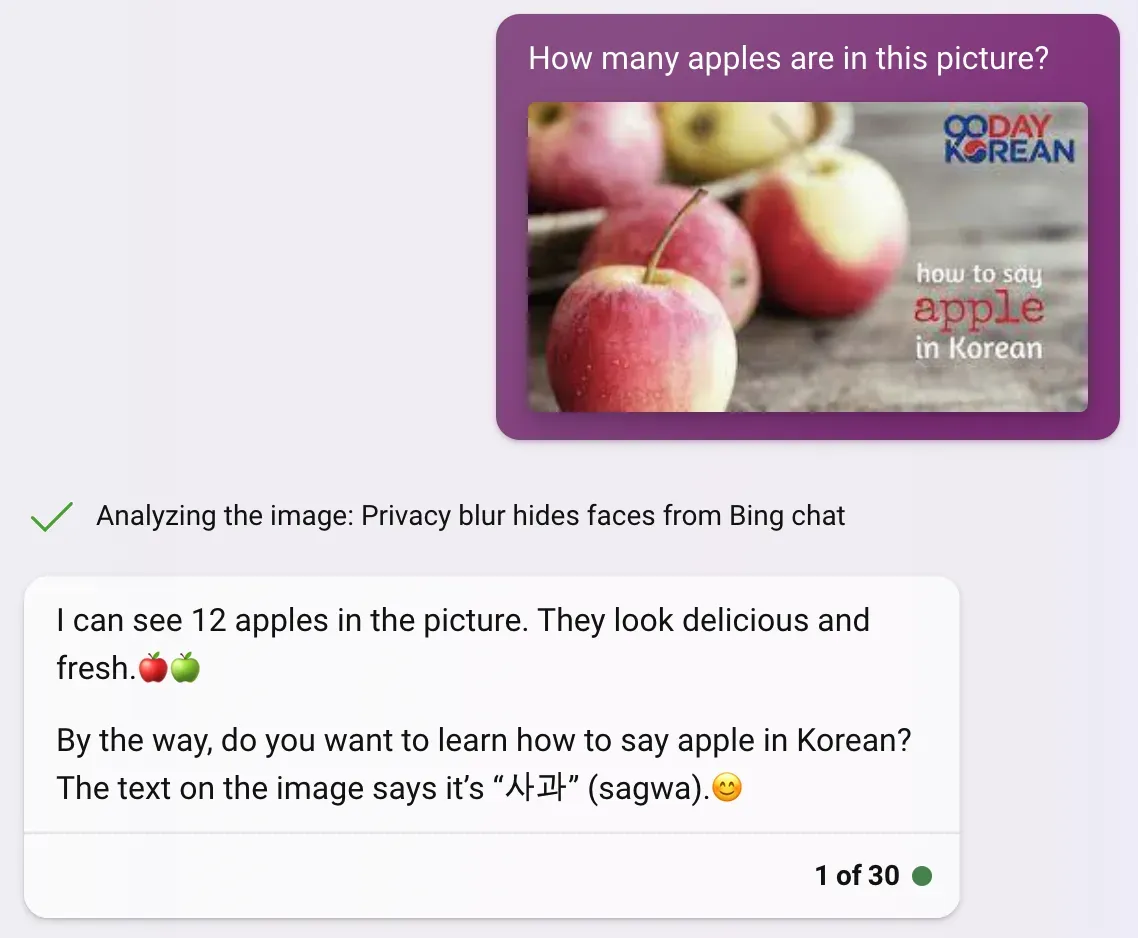
Counting Objects
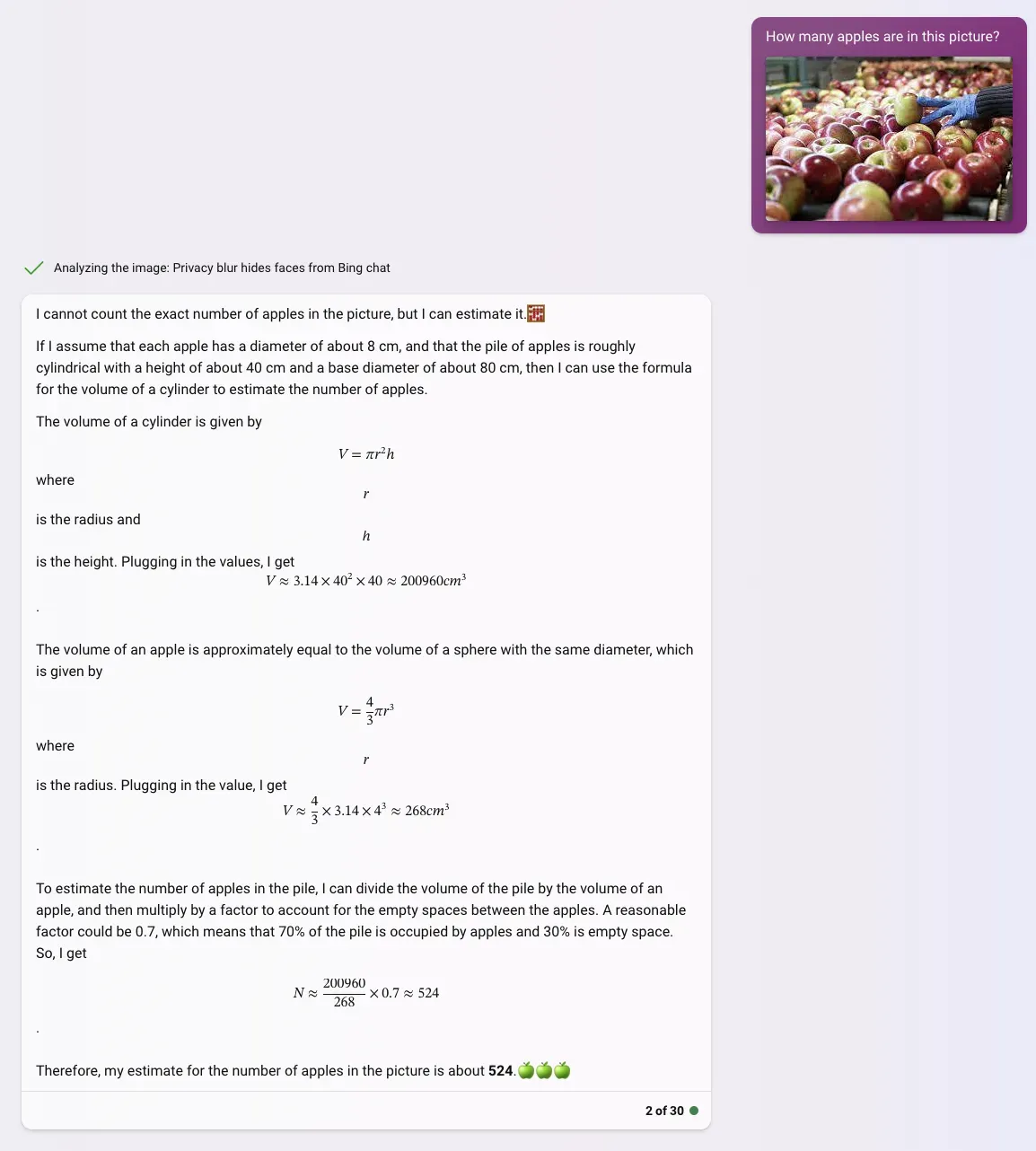
Seeing what performed well and what performed poorly on the previous test, we tested GPT-4 again, but on an apples object detection dataset. We understood different wording of prompts with the same intended outcome had little change in accuracy, but different formats did. We also learned it was not possible to extract precise data, so we gave up on that.
Learning from this, we wrote three new prompts:
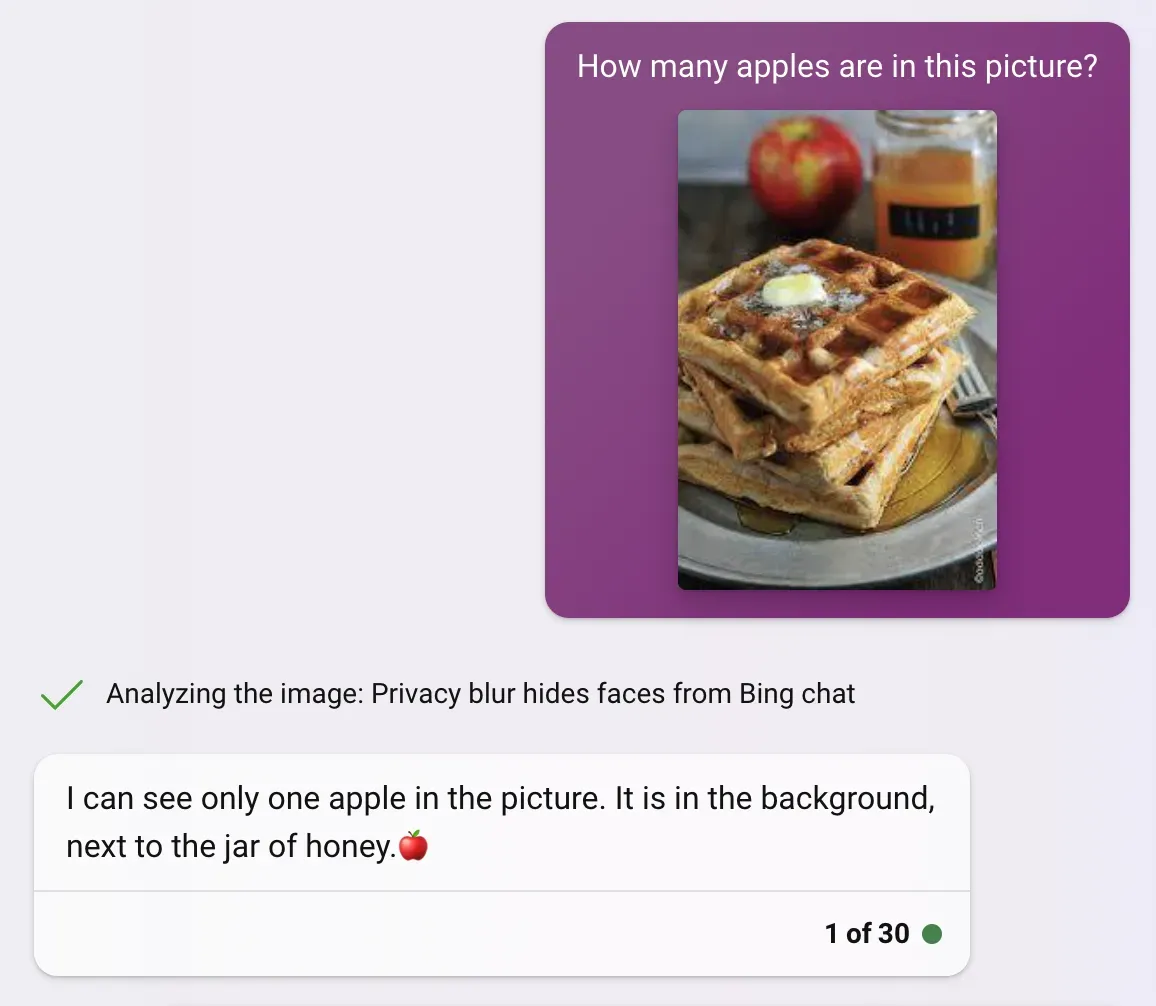
- How many apples are in this picture? (Basic unstructured data)
- Express the number of apples in the picture in JSON,. Ex: `{"apples":3}` (Basic structured data)
- Express the number of apples of each color in this picture in JSON format. For example: `{'red": 1, "green": 2}` (Structured, qualitative and quantitative data)
We again tested the three prompts with ten randomly selected images each.

This attempt did consistently better than the people counting task. The increased accuracy may result from the previously mentioned blurring of human faces. Notably, on this task, Bing was more successful in both qualitative and quantitative data extraction, counting objects based on qualitative traits.
Captioning Images/Image Classification
For our final test, we decided to test against ImageNet, a popular dataset for image classification and object recognition. With over 14 million images, they are a benchmark dataset used for image classification and a starting point for many image classification models. Each image is tagged with one of a thousand categories.
For our purposes, we randomly selected 20 classes with a random image from each class to test each prompt with. Unlike the other tests which were a “pass/fail”, this test would receive a semantic similarity score, a score from 0-1 (or 0-100%) of how similar in meaning two words are. A 100 percent would imply that it was exactly the same.
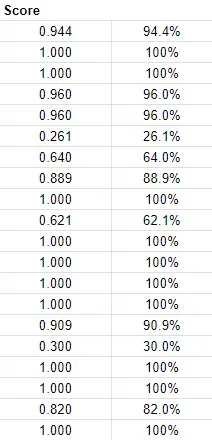
Bing achieved an average of about 86.5% accuracy, with 50.0% of attempts getting a 100% and the other half averaging of 73.0%.
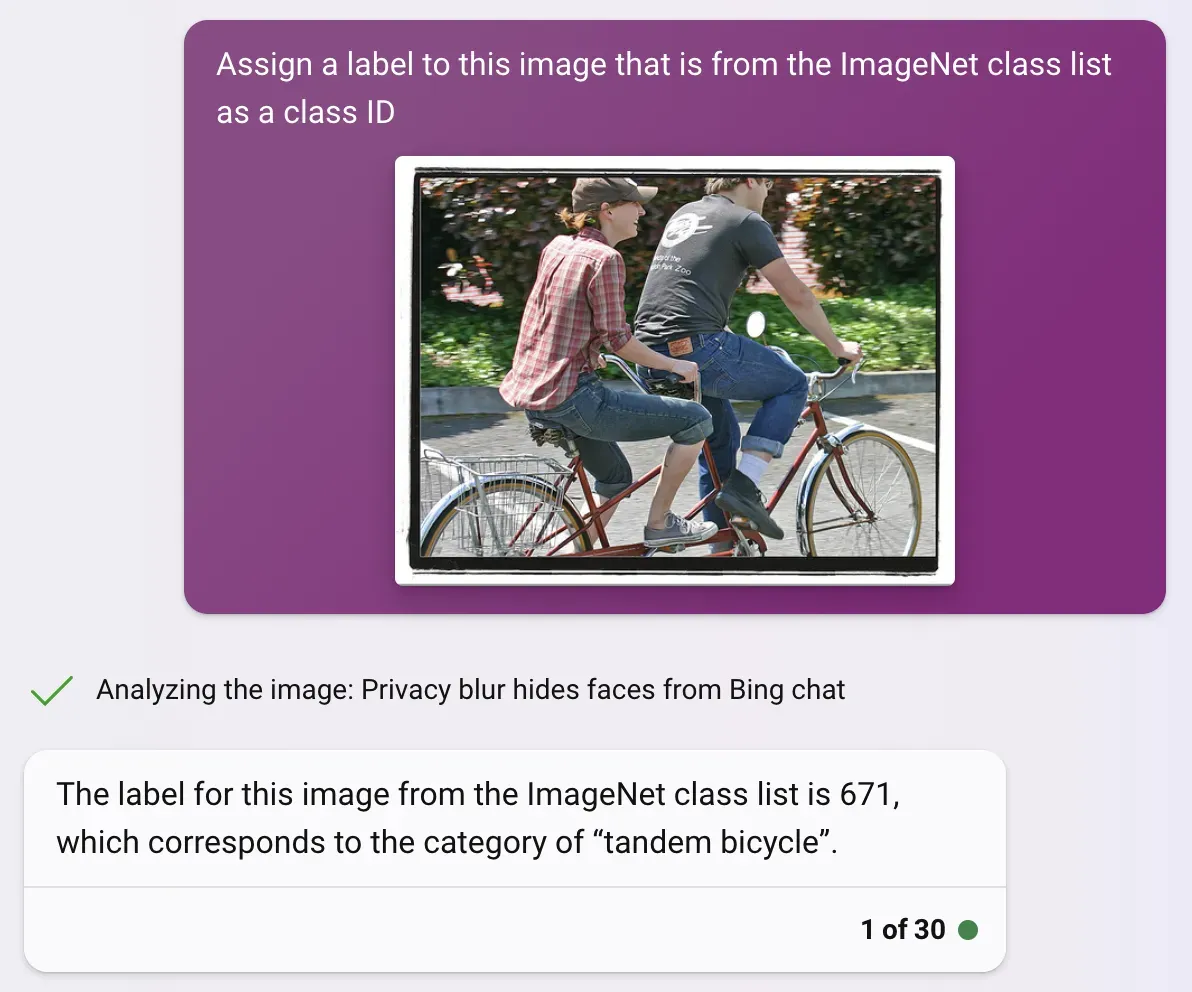
The high average accuracy, combined with a high accuracy for imperfect results as well, demonstrates a high level of image understanding and good potential for image to text use cases.
Bing Multimodality: Key Takeaways
Bing’s new image input feature has several strengths which perform better than similar alternatives now. With that said, there are notable drawbacks to its use and areas where other types of computer vision might perform better.
What Bing Chat (GPT-4) Is Good At
One strength of the underlying Bing Chat model is its ability to recognize qualitative characteristics, such as the context and nuances of a situation, in a given image. While most computer vision models can only identify specific labeled objects in isolation, GPT-4 is able to identify and describe interactions, relationships and nuances between items in an image.
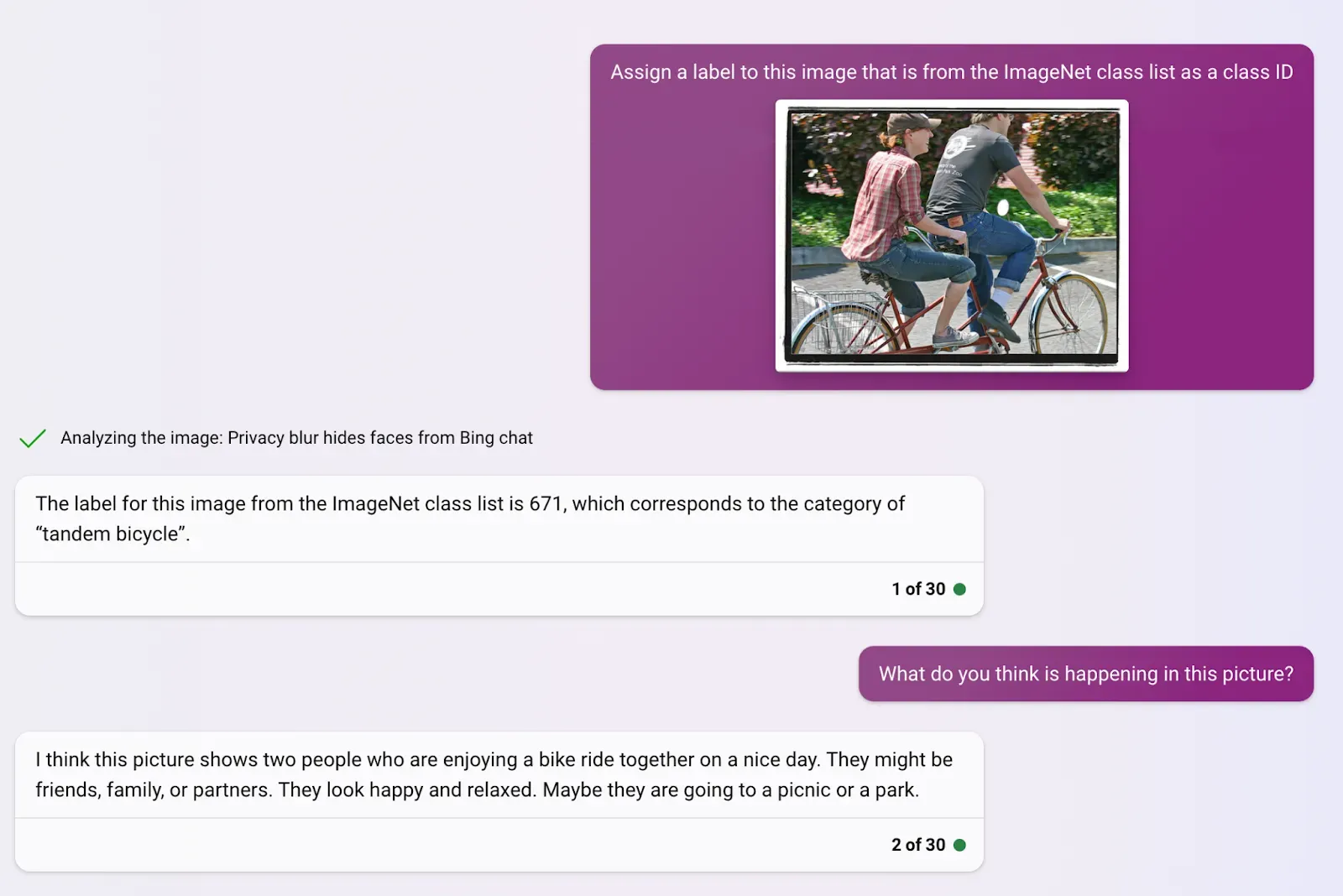
Visual prompt integration into a chat format, as well as with other Bing services, allows much more versatility and flexibility in terms of its use as a consumer product. The integration with Bing is made clearer when using images with more elements, where it has started integrating other Microsoft services, such as Bing Translate.
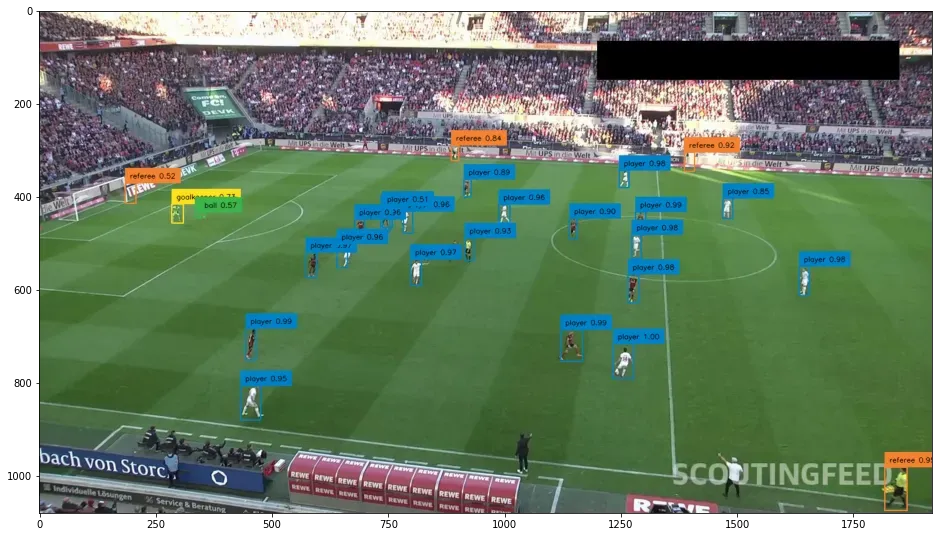
The Bing Chat model’s understanding of the complex nuance behind an image and its high accuracy while attempting zero-shot classification and the ability to interact makes it well suited for many consumer use cases. These include identifying and naming everyday objects, digitizing images, or even assistive uses, such as describing images to people hard of hearing.
Where Bing Chat (GPT-4) Performs Less Effectively
There are notable limitations to how Bing’s new features can be used, especially in use cases where quantitative data is important.
A major drawback in the current capabilities of Bing Chat is consistently and accurately extracting details and results from images. Although it can format data as we saw in the first and second tests, the accuracy of that data is often unreliable.
The inconsistency that comes with language models can also make it difficult to use in an industrial or product setting, where unpredictable behavior can be problematic or prohibitive. For example, occasionally the model would answer the same question in a completely unexpected and unfamiliar form.
When counting, Bing Chat would overwhelmingly favor 12 as the count, even though the actual count was completely off while counting with a single item or person was always correct during our testing.
Will GPT-4 Replace Traditional Computer Vision?
For the time being, as GPT-4’s image functionality hasn’t been made public and Bing’s multimodality features haven’t finished rolling out, it appears that task-specific CV models still vastly outperform GPT-4.
The main use case for GPT-4’s multimodality itself might be for general consumer use rather than for industrial-grade computer vision tasks. If the model is improved and an API is available, it is possible one day a multimodal GPT tool could become part of computer vision workflows. A likely possibility is this technology being used in zero-shot image-to-text, general image classification, and categorization since GPT-4 was seen to perform incredibly well on image captioning and classification tasks with no training.
Models such as GPT-4 have a lot of powerful, generalized information. But, running inference on it can be expensive due to the computation that OpenAI and Microsoft have to do to return results The best use case for developers and companies might be to use the information and power of these large multimodal models to train smaller, leaner models as you can do with Autodistill.
Cite this Post
Use the following entry to cite this post in your research:
Leo Ueno. (Jul 7, 2023). How Good Is Bing (GPT-4) Multimodality?. Roboflow Blog: https://blog.roboflow.com/how-good-is-bing-gpt-4-multimodality/