
Zero-shot learning (ZSL) lets a computer vision model classify objects from classes it never saw during training, using auxiliary information like text descriptions to transfer knowledge from seen to unseen classes. This guide explains how ZSL works, covers the main method families including classifier-based, instance-based, projection, correspondence, relationship, and synthesizing approaches, and discusses evaluation metrics alongside the limitations, such as hubness and semantic gap problems, that can reduce accuracy on novel classes.
Consider the case of recognizing a category of an object in images without ever having seen a photo of that type of object. You might be able to determine what a cat is in an image the first time you see it if you have read a comprehensive description of it.
Modern computer vision algorithms applies this principle in a technique called "zero-shot learning". Zero-shot learning lets a model complete a task without having received any training examples by using auxiliary information – for example, text descriptions – to infer what might be in an image.
In this article, we are going to discuss:
- What is Zero-Shot Learning?
- How does Zero-Shot Learning work?
- Zero-Shot Learning methods
- Zero-Shot Learning limitations
Let's dive in!
What Is Zero-Shot Learning?
Zero-Shot Learning (ZSL) is a machine learning technique that allows a model to classify objects from previously unseen classes, without receiving any specific training for those classes. This technique is useful for autonomous systems that need to be able to identify and categorize new objects on their own.
In ZSL, a model is pre-trained on a set of classes (seen classes) and then asked to generalize to a different set of classes (unseen classes) without any additional training. The goal of ZSL is to transfer the knowledge already contained in the model to the task of classifying the unseen classes. ZSL is a subfield of transfer learning, which involves adapting a model to a new task or set of classes.
There are two types of transfer learning: homogenous transfer learning, in which the feature and label spaces are the same, and heterogeneous transfer learning, in which the feature and label spaces are different. ZSL falls into the latter category.
Zero-Shot Learning Example
One pioneering example of zero-shot learning in computer vision is CLIP, an image classifier built by OpenAI. We discuss this technology in more depth in the following video, if you are curious:
Tutorial on using CLIP, a zero-shot image classifier
Why Is Zero-Shot Learning Useful?
Zero-Shot Learning is useful because it can help to overcome the challenges and costs associated with data labeling, an time-consuming and often expensive process. It is especially difficult to obtain annotations from specialized experts in certain fields, such as biomedical data, which requires the expertise of trained medical professionals.
Additionally, there may not be enough training data available for a class (i.e. in the case of trying to label rare defects in products), or the data may be imbalanced. These two scenarios make it difficult for a model to accurately reflect real-world scenarios. Furthermore, unsupervised learning methods may also be insufficient in some tasks such as classifying different sub-categories of the same object (for example, breeds of a dog).
ZSL can help to alleviate these problems by allowing a model to perform classification on novel classes (unseen classes) using the knowledge it has already learned during training.
ZSL has a range of applications, including image classification, object detection, object tracking, semantic segmentation, style transfer and natural language processing. It is particularly useful in scenarios where labeled data for novel classes is scarce or expensive to obtain.
Example real-world application of zero-shot learning
 roboflow
roboflow
How Does Zero-Shot Learning Work?
In Zero-Shot Learning, data is divided into three categories:
- Seen Classes: Classes that have been used to train the model.
- Unseen Classes: Classes that the model needs to be able to classify without any specific training. The data from these classes were not used during training.
- Auxiliary Information: Descriptions, semantic information, or word embeddings about all of the unseen classes. This is necessary in order to solve the Zero-Shot Learning problem because there are no labeled examples of the unseen classes available.

Zero-Shot Learning is a two-step process that involves training and inference. During training, a model learns about a labeled set of data samples. During inference, the model uses this knowledge and auxiliary information to classify a new set of classes.
Humans are able to perform "Zero-Shot Learning" because of their existing language knowledge base. We can make connections between new or unseen classes and previously seen visual concepts. Like humans, Zero-Shot Learning relies on existing knowledge.
In the case of computer vision, "knowledge" is a labeled training set of seen and unseen classes. The data provided should be related in a high-dimensional vector space called a semantic space. The knowledge from the seen classes can be transferred to the unseen classes in this space.
Zero-Shot Learning: Training Methods
The two most common approaches used to solve the zero-shot recognition problems are:
- Classifier-based methods
- Instance-based methods
Let us discuss them in more detail.
Classifier-Based Methods
Classifier-based methods for training a multi-class zero-shot classifier typically involve using a one-versus-rest approach, where a separate binary classifier is trained for each unseen class. Depending on the specific approach used to construct the classifiers, these methods can be further divided into three subcategories:
Correspondence Methods
These methods aim to build a classifier for unseen classes by establishing a connection between the binary one-versus-rest classifier for each class and its corresponding class prototype in a semantic space.
Each class has a single prototype in the semantic space that can be considered as the "representation" of that class. In the feature space, each class has a corresponding binary one-versus-rest classifier. This can be seen as a "representation" of that class. The goal of correspondence methods is to learn a function that maps between these two types of "representations."
Relationship Methods
Relationship methods for constructing a classifier for unseen classes focus on the relationships between and within those classes. In the feature space, binary one-versus-rest classifiers for the seen classes can be trained using available data.
Relationship methods aim to build a classifier for the unseen classes based on these trained classifiers and the relationships among the seen and unseen classes. This information can be determined by calculating the relationships between corresponding prototypes. These methods aim to incorporate both the class relationships and the learned binary seen class classifiers in order to classify the unseen classes.
Combination Methods
The methods belonging to this category involve constructing a classifier for unseen classes by combining classifiers for the basic elements that make up those classes.
In this approach, it is assumed that there is a list of basic elements that can be used to form the classes. It is also assumed that each data point in the seen and unseen classes is a combination of these elements. For example, an image of a dog might have elements such as a tail and fur.
In the semantic space, each dimension is associated with a basic element. Each class prototype represents the combination of these elements for the corresponding class. The class prototypes can take on a value of 1 or 0 for each dimension, indicating whether the class has the corresponding element. These methods are particularly well-suited for use in semantic spaces.
Instance-Based Methods
Instance-based methods for zero-shot learning involve first obtaining labeled examples of the unseen classes and then using these examples to train a classifier. Depending on the source of these instances, instance-based methods can be divided into three subcategories:
Projection Methods
These methods aim to obtain labeled examples of the unseen classes by projecting both the feature space instances and the semantic space prototypes into a shared space. This involves having labeled training instances in the feature space for the seen classes, as well as prototypes for both the seen and unseen classes in the semantic space.
Both the feature and semantic spaces are represented as real number spaces, with instances and prototypes represented as vectors. In this view, the prototypes can be considered labeled instances as well. Projection methods involve projecting instances from these two spaces into a common space, which allows for obtaining labeled examples of the unseen classes.
Instance-borrowing Methods
Instance-borrowing methods involve obtaining labeled examples of the unseen classes by borrowing from the training instances. These methods rely on similarities between classes. For example, if we want to build a classifier for the "truck" class but don't have any labeled examples of trucks, we might use labeled examples of the "car" and "bus" classes as positive instances when training the classifier for "truck." This is similar to how humans recognize objects and learn about the world by recognizing similar objects. We might not have seen instances of certain classes, but we can still recognize them based on our knowledge of similar classes.
Synthesizing Methods
The methods belonging to this category involve obtaining labeled examples of the unseen classes by synthesizing pseudo-instances using different techniques. Some methods assume that instances of each class follow some kind of distribution, and use this information to estimate the distribution parameters for the unseen classes and generate synthetic instances.
Zero-Shot Learning Evaluation Metrics
To evaluate the performance of a classifier in zero-shot recognition, we calculate the average per category top-k accuracy. This metric measures the proportion of test samples whose actual class (label) is among the k classes with the highest predicted probabilities by the classifier.
For instance, suppose we have a 5-class classification problem. If the classifier outputs the probability distribution [0.40, 0.15, 0.15, 0.20, 0.1] for classes 0, 1, 2, 3, and 4, the top-2 classes are class-0 and class-3. If the true label of the sample is either class-0 or class-3, the classifier is considered to have made a correct prediction.
The average per category top-k accuracy is calculated by taking the average of the top-k accuracy for each class, where C denotes the number of unseen classes.
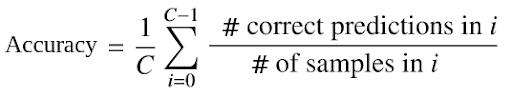
Zero-Shot Learning Limitations
Like every concept, Zero-Shot Learning has its limitations. Here are some of the most common challenges you will face when applying Zero-Shot Learning in practice.
Bias
When a model is trained on data from only the seen classes, it is more likely to predict samples from unseen classes as belonging to one of the seen classes during the testing phase. This bias can be particularly pronounced when the model is evaluated on a mix of seen and unseen class samples during testing.
Domain Shift
In Zero-Shot Learning, the main goal is to adapt a pre-trained model to classify samples from novel classes when data from these classes becomes available. For example, a model trained to recognize dogs and cats using supervised learning could be adapted to classify birds on the fly using Zero-Shot Learning.
One common challenge in this context is the "domain shift" problem, which occurs when the distribution of data in the training set (seen classes) and the testing set (which may include samples from both seen and unseen classes) is significantly different.
Zero-shot learning is thus unsuitable for trying to make predictions on images that are far from the domain on which the model was trained.
Hubness
Zero-Shot Learning often faces the challenge of the "hubness" problem, which occurs due to the curse of dimensionality in the nearest neighbor search of high-dimensional data. Points called "hubs" tend to frequently appear in the k-nearest neighbor set of other points.
In Zero-Shot Learning, the hubness problem arises for two reasons:
- Both input and semantic features exist in a high-dimensional space, and projecting this high-dimensional vector into a low-dimensional space can lead to clustering of points as hubs due to reduced variance.
- Ridge regression, which is commonly used in Zero-Shot Learning, can also induce hubness. This leads to bias in predictions and a tendency for only a few classes to be predicted frequently. The points in these hubs tend to be close to the semantic attribute vectors of many classes, which can lead to a decline in performance during the testing phase when using the nearest neighbor search in semantic space.
Semantic Loss
Semantic loss refers to the loss of latent information present in the seen classes that may not have been important in distinguishing between the seen classes, but could be important in classifying the unseen classes during the testing phase. This can occur because the model is trained to focus on certain attributes in the seen classes and may not consider other potentially relevant information. An example of this is a cat/dog classifier that focuses on attributes such as facial appearance and body structure, but does not consider the fact that both are four-legged animals, which could be important in classifying humans as an unseen class during the test phase.
Key Takeaways: Zero-Shot Learning
Zero-Shot Learning is a machine learning technique that enables a pre-trained model to classify samples from classes that were not present in the training data.
This technique relies on auxiliary information, such as class descriptions or semantic information, to classify novel classes. This auxiliary information is used to transfer knowledge from the training classes to the novel classes. There are several methods for performing Zero-Shot Learning, including classifier-based methods, instance-based methods, and projection methods.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Jan 5, 2023). What Is Zero Shot Learning in Computer Vision?. Roboflow Blog: https://blog.roboflow.com/zero-shot-learning-computer-vision/