
You'll hear the words "supervised learning" and "unsupervised learning" a lot in discussions about data science, machine learning, and other related fields. Being able to distinguish between supervised and unsupervised learning is fundamental knowledge that will come up time and time again in a career in data science.
In this blog post, we are going to introduce what supervised and unsupervised learning are and discuss their differences. We'll also discuss the advantages of both supervised and unsupervised learning.
Let's start with the first questions that will be on your mind: What is supervised and unsupervised learning? Are they a specific way of training an algorithm? Are those terms related to the fact that during the training, is there someone that "supervises" the training?
If you were thinking about one of these answers, I have bad news for you. No, they are not referring to those things even though their name could make you think that way. Let's start with a video that explains the differences. We'll then outline both types of learning in more depth later in the article.
Video explanation of supervised and unsupervised learning
What is Supervised Learning?
Supervised learning is a technique in machine learning and computer vision where a model is fed training data that is mapped to labels. The labels associated with data are used to help a model learn to classify data such as images. Predicting house prices, identifying whether an image contains explicit material, and determining whether a screw is or is not in a photo are all examples of problems that can be solved using supervised learning.
The idea of supervised learning is the following: Imagine showing a child a car for the first time. You want them to learn that what you are showing them is a car. So, you say "Hey, this is a car".
Suppose you wait one hour and ask the child to name the object you taught them earlier. The child, most likely, will not remember it. So, in order to teach the child, you keep telling them, for example, 1 million times, "This is a car".
Your hope is that through repetition, the child learns that what a car is. And if in the future the child sees another car (different from the exact one you showed them before), your hope is that they will still be able to recognize that object as a car.

The same thing happens with machine learning algorithms that are part of Supervised Learning. Since we have datasets that are labeled (i.e. we know the meaningful information about each data point), by proposing the data to the algorithm many times, the algorithm learns.
In jargon, the data is represented with X and the label as Y.
The two most common supervised learning algorithms are classification and regression.
- Classification: classification algorithms answer questions like “is it a cat or dog?“, namely "to which class does this datapoint belong?". In multi-label classification use cases, it can be both a cat and a dog.
What happens under the hood? Behind the scenes, classification algorithms try to learn a decision boundary that optimally separates the classes. Like the following image:
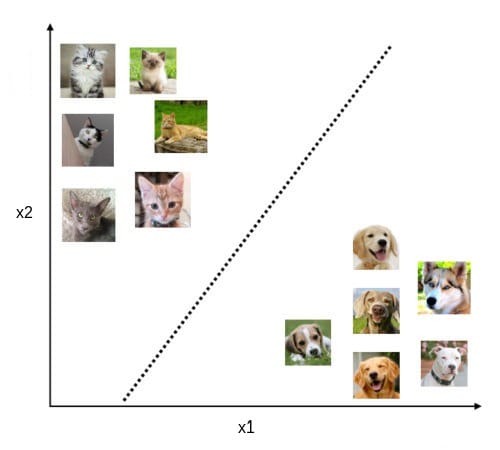
Projecting the features of both classes, it is likely we will end up having something like this chart. Of course, there are infinite possible decision boundaries that can be learned, but the more promising one looking at the chart is probably the dotted one.
Some common classification algorithms are Logistic Regression, Support Vector Machines, Decision Tree Classification and K-Nearest Neighbours.
- Regression: suppose we have a dataset that has two input features containing the size of a house and the locality of the house. We would like to predict the house price. In this case, we have a continuous label to predict, not a single one as in classification problems. So we cannot use classification to do that because we would have a huge amount of labels and a very small data-point size per label. Therefore, we use regression which helps us to understand the relationship between the dependent variable (the output to predict) and the independent variables (the input features).
Some common classification algorithms are Linear Regression, Polynomial Regression, Decision Tree Regression and Lasso Regression.
Challenges of Supervised Learning
In general, the more data we have, the better. Nowadays, machine learning algorithms are trained with millions of data. However, collecting and labeling such an amount of data is, more often than not, time-consuming. Open source datasets are helping make supervised learning more accessible.
Depending on the task we want to perform, some types of data are easier to label than others. If you want to perform a task like semantic segmentation, you cannot just assign a single word as a label, and you need to have each pixel of the image labeled properly. Since this type of labeling is a very slow task to perform, some datasets have a small size and this is not ideal because we would like to have as much data as possible.
A further drawback is that the labels people assign to the data could have errors. COCO is an often cited dataset with many known errors.
For example, what label would you assign to this image?

Cat? Dog? Both? Include the breed, color, age, emotion, and stance? It is not well-defined and it depends on what task we want to perform with the model.
Oftentimes the data we have could be less than ideal for the specific use case. If we take the ImageNet dataset, which contains millions of images, are we sure that all the images within ImageNet are "good" images?
Most often when building models, we just trust whoever created the dataset and keep in mind that some images or labels could contain errors. It's not perfect, but as long as you keep the variance in mind, you can make it work.
Supervised Learning Examples
Thanks to the high computational power we have at our disposal and the huge amount of data available, we can use supervised learning models to build and advance several business applications, including the following:
- Self-driving cars: thanks to the great strides made in the field of computer vision, especially in image classification, object detection, semantic segmentation and depth estimation, we are now able to build self-driving cars.
- Healthcare: one of the most important applications of supervised learning is related to medicine. These models can be useful to support doctors with services that help the doctor to diagnose or predict disease in patients before they manifest.
- Spam detection: Supervised learning models are commonly used to detect spam sent via email and social networks. In the case of email, the result of a supervised spam classifier (is this email spam or not spam?) will decide whether or not an email shows up in your spam inbox.
- Sentiment detection: Is a given message positive or negative? That is a question that the field of sentiment analysis aims to answer. The field makes use of unsupervised learning techniques to detect the sentiment in a corpus of text.
What is Unsupervised Learning?
Unsupervised learning refers to using statistical models that work with data and do not have a label attached. Unsupervised learning is commonly used to cluster information in datasets. With unsupervised learning, patterns can be inferred from a dataset without the need to specify a label for every piece of data in the dataset.
How is it possible to not have a label attached to our data? I mean, we can label them, right? Well, this is not always the case.
As we mentioned before, labeling data is time-consuming and expensive to spend months or years labeling. Moreover, in some cases, we do not know how to label the data upfront.
However, suppose you have a dataset containing 1 million unlabeled images but you need the labels because you want to apply some supervised learning technique. Is there a way to automatically label them?
Yes! We can achieve it by using, for example, a clustering technique that falls over the field of unsupervised learning.
Now, let's see what the main tasks where unsupervised learning is applied.
Clustering: a data mining technique that groups unlabeled data based on their similarities or differences. A well-known clustering algorithm is K-means. K-means clustering is a common example of an exclusive clustering method where data points are assigned into K groups, where K represents the number of clusters based on the distance from each group’s centroid. The data points closest to a given centroid will be clustered under the same category.
Dimensionality reduction: while more data generally yields more accurate results, it can also impact the performance of machine learning algorithms (e.g. overfitting) and it can also make it difficult to visualize datasets. Dimensionality reduction is a technique used when the number of features, or dimensions, in a given dataset is too high. It reduces the number of data inputs to a manageable size while also preserving the integrity of the dataset as much as possible.
A common dimensionality reduction method is the principal component analysis (PCA): PCA uses a linear transformation to create a new data representation, yielding a set of "principal components." The first principal component is the direction which maximizes the variance of the dataset. While the second principal component also finds the maximum variance in the data, it is completely uncorrelated to the first principal component, yielding a direction that is perpendicular, or orthogonal, to the first component.
Association rules: an association rule is a rule-based method for finding relationships between variables in a given dataset. These methods are frequently used for market basket analysis, allowing companies to better understand relationships between different products. Understanding the consumption habits of customers enables businesses to develop better cross-selling strategies and recommendation engines.
The most widely used algorithm used to generate association rules is the Apriori algorithm. Apriori algorithms are used within transactional datasets to identify frequent item sets, or collections of items, to identify the likelihood of consuming a product given the consumption of another product.
Challenges of Unsupervised Learning
While unsupervised learning has many benefits, some challenges can occur when it allows machine learning models to execute without any human intervention. Some of these challenges include:
- Unsupervised learning is intrinsically more difficult than supervised learning as it does not have corresponding output.
- The result of the unsupervised learning algorithm might be less accurate as input data is not labeled, and algorithms do not know the exact output in advance.
- It can be expensive as it might require human intervention to understand the patterns and correlate them with domain knowledge while, in general, we would like to have less human intervention as possible.
Unsupervised Learning Examples
Machine learning techniques are now frequently used to enhance the user experience of products and to test systems for quality assurance. Unsupervised learning provides an exploratory path to view data, allowing businesses to identify patterns in large volumes of data more quickly when compared to manual observation.
Some of the most common real-world applications of unsupervised learning are:
- Data labeling: as we briefly mentioned before, we can exploit clustering to cluster our data and subsequently label them. Suppose we have an image dataset and we want to label them to perform image classification on that subsequently. We can apply clustering and hope that the algorithm finds distinct clusters such that we can assign the same label to each image belonging to the same cluster. Of course, we will never have completely different clusters. Some images could fall in between some clusters. In that case, what one could do is look at the image and manually attach a label.
- Image compression: using dimensionality reduction, unsupervised learning algorithms are used to reduce the number of dimensions in a dataset while preserving most of the information in the data.
- Generate synthetic images: if we need more data, we can use generative models (like Variational Autoencoders or Generative Adversarial Networks) to generate new synthetic realistic data. The main advantage of generating synthetic images is that labels are known in advance.
- Anomaly detection: unsupervised learning models can perform anomaly detection to spot atypical data points within a dataset. These anomalies can raise awareness around faulty equipment, human error, breaches in security or fraud detection. By predicting anomalies, we can warn ourselves to prevent something from happening and this often results in not losing money or otherwise limiting it as much as possible. A use case of that could be performing anomaly detection on a video stream from a surveillance camera.
Supervised vs. Unsupervised Learning
There is one rule of thumb to keep in mind when comparing supervised and unsupervised learning: you use supervised learning algorithms when your labels are known and use unsupervised algorithms when they are not.
Supervised learning methods have the advantage that by having labels, you can build models where in principle you can teach a model what you want and build metrics that, thanks to the labels, can measure the model's performance. On the other hand, they have the disadvantage that there is a cost to labeling.
Although you do not have the labels, unsupervised methods are still often very powerful as they allow you to automatically label your data letting you save an unmeasurable amount of time and also generate new synthetic realistic data which is crucial when you do not have enough.
Use Roboflow to manage datasets, label data, and convert to 26+ formats for using different models. Get started free.
Cite this Post
Use the following entry to cite this post in your research:
Petru P.. (Sep 28, 2022). Supervised Learning vs. Unsupervised Learning: Explained. Roboflow Blog: https://blog.roboflow.com/supervised-learning-vs-unsupervised-learning/