
COCO is an industry standard dataset for benchmarking the performance of object detection models. The dataset was created by "gathering images of complex everyday scenes containing common objects in their natural context" and contains image annotations in 91 categories, with over 1.5 million object instances.
People have devoted their careers to building models to beat the current state-of-the-art performance, generally using the single metric of mean average precision (mAP), on COCO.
But, do you know what is inside it? A few examples are below and you can also query COCO, no login or understanding of computer vision required.





COCO isn't the only benchmark dataset with odd images and questionable labeling practices. PASCAL VOC 2012 is full of fun training data, too.




How Did We Find Strange Images in COCO?
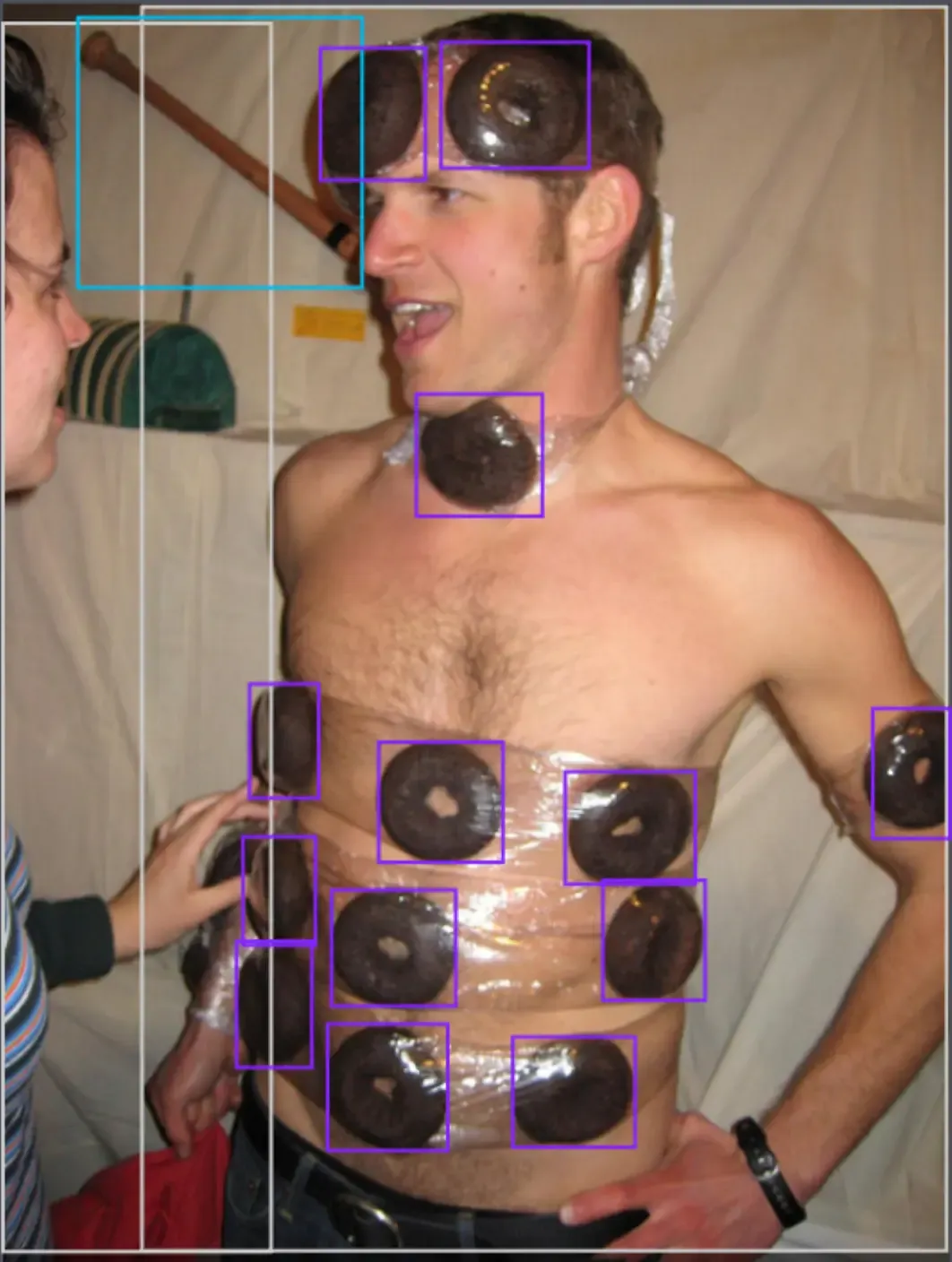
It all started out with an innocent search for Santa which immediately lands a unique result in the first image.
0:00/1×There are two people in the image, only one is labeled, but that's the least weird thing happening in this photo
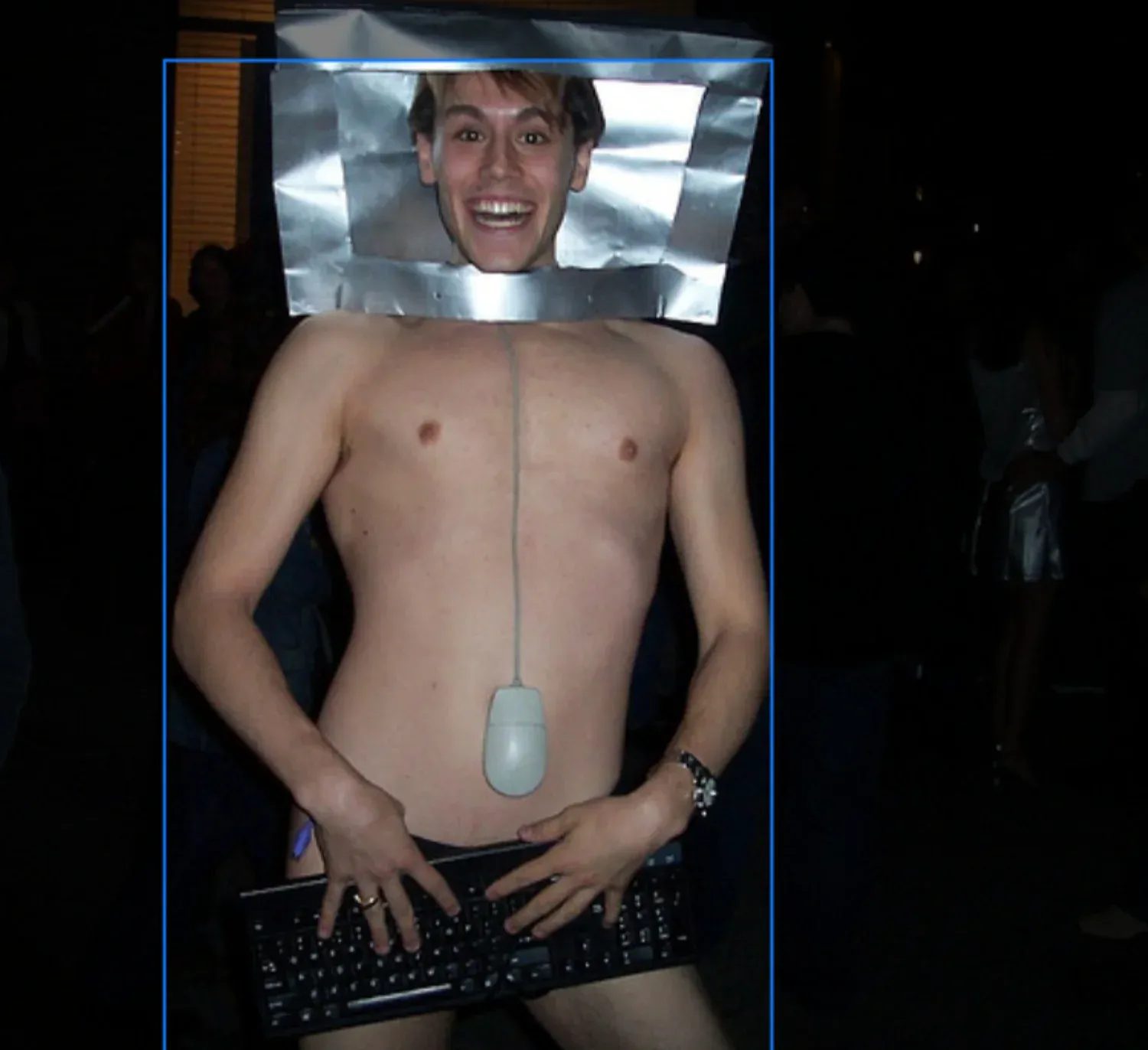
The person on the right looked to be wearing a furry costume, which led us to search for furry.
By internet standards, these images are relatively tame, but it's surprising to think they are part of the dataset academics, researchers, and computer/data scientist are spending hundreds of hours building model architectures to master understanding this data.
It's at this point in the process of thinking up weird searches that we remembered most of the data was pulled from the internet which means a lot of the searches result in weird photos pretty easily.
Even something as simple as hot dog gives us a very unintuitive result.
0:00/1×Yes, a dog in an oven is technically not wrong
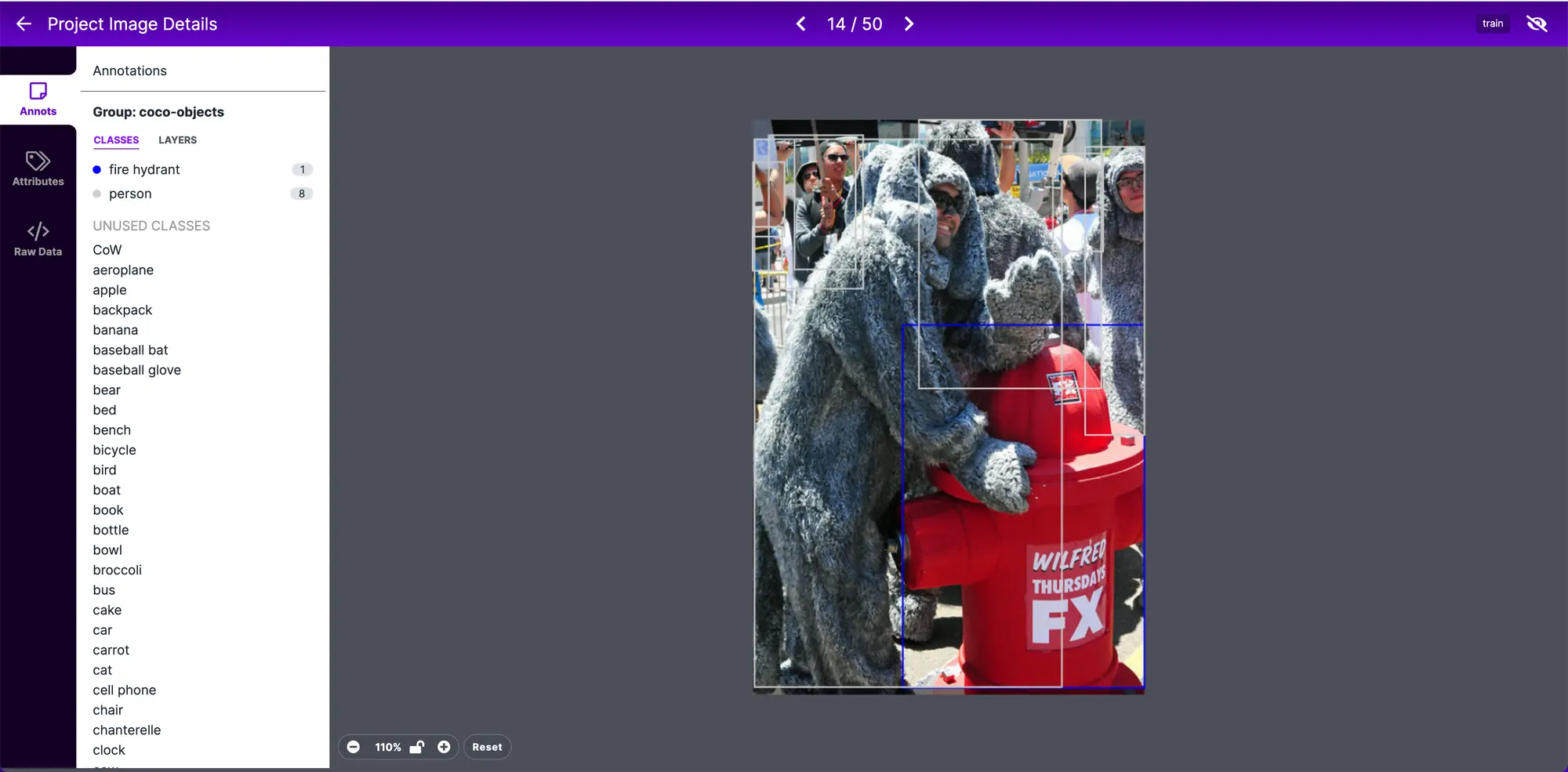
We then started playing around with fun adjective and noun combos like creepy statue.
Moving beyond weird things in the natural world, we started to test out a straight forward funny internet culture topics like memes.
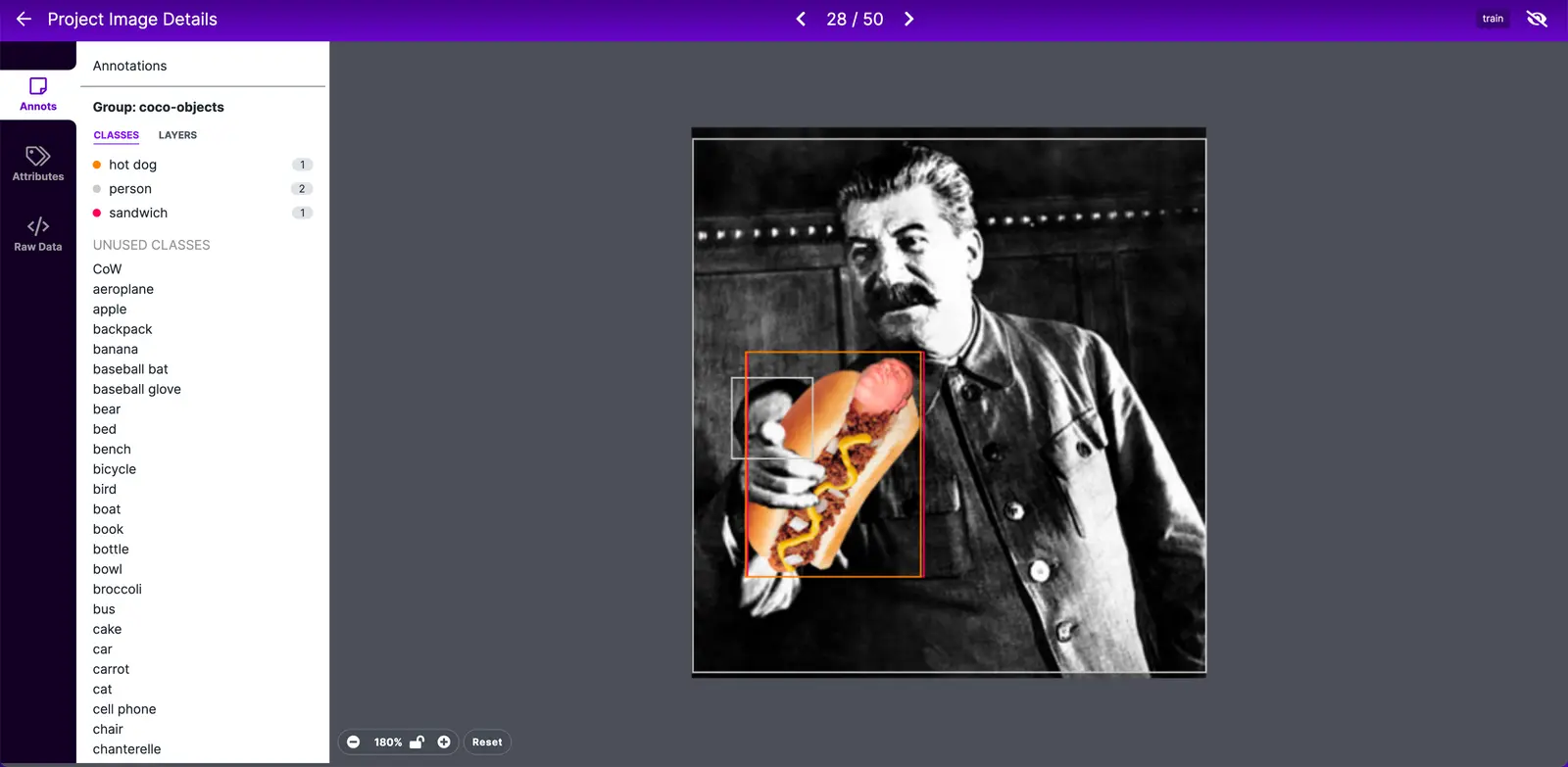
If you endeavored to spin up your own searches at this point, share them with us on Twitter or Hacker News, we'd love to know what you find!
That's the end of the dataset search rabbit hole, now let's get in to what this means for the computer vision community.
Unique data is good to help models catch edge cases. When it comes to the performance of a given architecture, it's important to remember that if the data doesn't represent the environment you'll be using it in, then higher performance on that specific dataset might not matter to you after all.
Why Do People Use COCO?
Let's start with why COCO and other benchmark datasets are useful.
COCO is used as a checkpoint from which to train custom models. Training a model from scratch is time intensive and costly. Using a checkpoint will save you time and allow you to change the last few layers of a model to better fit your custom data.
This works extremely well if a custom dataset shares some similarity with COCO, for example a collection of people walking in a street. It is also helpful because it helps train a model on what objects are not in your dataset. For example, training from a COCO checkpoint might help ensure your model doesn't think a snake is a necktie because it has lots of necktie training data from COCO.
Having a standard dataset, regardless of it's flaws, allows us to understand the relative performance (accuracy, inference speed, cost to train, time to train, etc) of models. This is extremely helpful as a quick reference when deciding which model is best suited for your computer vision project.
Over the years, COCO has become the de facto standard dataset to train object detectors on. Beating the current best performing models on COCO gives you a certain publication in the most prestigious machine learning conferences. People have taken from granted that a model with an higher mAP on COCO is "better" than a lower one, but is that really true?
Why Model Performance Varies by Data Type
Each model is tuned and architected for different outcomes. Developing a computer vision model happens in the context of what problem is ultimately being solved by the model. Some models give trade speed for accuracy or trade accuracy for cost or trade accuracy for size. Creating a model to run on a mobile phone has different attributes than a model built to run on a hosted server.
Many of the most common models are developed to be generally usable for general use cases and that might work for your application. In the cases where you need a model to perform with specific size, speed, compute, and cost constraints, you'll want to select the right model for the task at hand.
This being so, so what?
The goal of highlighting what is inside benchmark datasets is not to discredit them or suggest you should not use them. Rather, the goal is to understand them for what they are and then use that information to help inform your decisions when it comes to model development and model selection.
Most importantly, realizing that the data is flawed means you should take any model's mAP with a grain of salt and not base decisions just because one model had a slightly higher mAP over the other. Keep this margin of error in the data in mind and choose models with meaningfully better performance.
Test Models on Multiple Datasets to Narrow Your Selection
When evaluating which model to use for your project, test performance across multiple benchmark datasets and novel datasets. Roboflow Universe is home to 90,000+ datasets you can use to see how various models perform on different types of data. You can search each dataset to understand what it is compromised of before training a model. We also offer a model zoo of notebooks to easily test multiple models across multiple datasets.
Ideally you would find a dataset similar to the data you plan to use in your project. Testing on similar data will help give a more accurate picture of how a given model might perform for your use case.
Test Models on Your Data to Make a Final Decision
Once you've narrowed down which models might perform well with data like yours, start testing the models on your actual data. You'll need to label and annotate the data with a tool like Roboflow Annotate. And in order to make sure your dataset is as accurate as possible, we have a guide on labeling best practices for you to follow.
How to Compare Computer Vision Models
If you're unsure how to test models in a scientific way, we have a few suggestions for how to compare different models.
Use at least three seed. Deep learning models are trained with stochastic gradient descent and its variances, meaning one model may just be lucky. Use at least three seed and average the results between them.
Run the model for enough time. Anytime you're comparing models, you need to run for the same amount of time that fits your use case, ideally the longer the better the models will be.
Use cross-validation (k-fold). Models perform differently depending on the data in your test/valid/train splits. You'll want to systematically change the data and see how the model performance changes.
Train in an unsupervised way. Researches have shown performance boosts when using self-supervised models. Meta recently offered an example of unsupervised training (research paper also available). There is even a model trained on 1B images from Instagram. Labeling images in order to train a model has flaws and unsupervised training helps reduce the errors caused by human labeling and making the model more general.
A Data-centric Approach to Computer Vision Performance
Model architecture and model fine tuning is one path to improved performance. Another path, one that is more controllable and within reach of most people, is improving model performance by improving the dataset used to train a model.
If you are running into performance issues and fine tuning a model isn't something you're capable of doing, you can reach higher levels of model performance by expanding your dataset based on sampling data from your production environment.
Active learning is one strategy to improve your dataset and is the process of capturing more data, labeling the data, adding the data to a dataset, and then training your model on the expanded dataset. This can be done via API or with a simple pip package to programmatically find data that your model is not performing well on.
Always Understand your Dataset
To conclude, finding oddities and errors in a dataset does not mean the results of training on the dataset is not valid.
Finding errors in datasets does mean you should always understand your data, work to label it accurately, and test models for yourself when deciding which to use. Roboflow offers you the ability to search your own datasets or explore one of the 90,000 available datasets in Roboflow Universe, for free.
Cite this Post
Use the following entry to cite this post in your research:
Francesco, Trevor Lynn. (Aug 30, 2022). WTF COCO - The Weird Images that Underpin Modern Computer Vision Models. Roboflow Blog: https://blog.roboflow.com/coco-dataset-image-search/