
Annotating images for object detection or instance segmentation can be a tedious and expensive process. However, recent advancements in AI have paved the way for quicker and more accurate annotation methods. Grounding DINO and Segment Anything Model (SAM) are two state-of-the-art models that can considerably speed up this process. In this comprehensive blog post, we will demonstrate how these models can be utilized for image annotation and the conversion of object detection datasets into instance segmentation datasets.
We have prepared a Jupyter Notebook that you can open locally or in Google Colab and follow along while reading the blog post.
Let's dive into the details!
Check out our Autodistill guide for more information, and our Autodistill Grounding DINO documentation.
Annotating Images with Grounding DINO and SAM
Grounding DINO and SAM are powerful AI models that can assist in the dataset annotation process. Grounding DINO is capable of zero-shot detection of any object in the image, while SAM can convert these bounding boxes into instance segmentation masks.

We have previously published blog posts that cover the details of these models and provide step-by-step instructions on how to install and use them. To save time, we encourage you to refer to these blog posts for in-depth information and guidance: Grounding DINO: Zero-Shot Object Detection and How to Use Segment Anything Model (SAM).
Using Grounding DINO to Generate Bounding Boxes
First, prepare the image you want to annotate. Next, use the Grounding DINO model to generate bounding boxes around the objects present in the image. These initial bounding boxes will act as a starting point for the instance segmentation process.

Using SAM to Convert Bounding Boxes into Instance Segmentation Masks
With the bounding boxes in place, you can now use the SAM model to convert them into instance segmentation masks. The SAM model takes the bounding box data as input and outputs precise segmentation masks for each object in the image.

Dataset Processing and Saving
After obtaining the initial instance segmentation masks, it's essential to clean up the data. This may involve removing duplicate detections, merging overlapping polygons, or splitting polygons that cover multiple objects. Careful data cleaning ensures the final annotations are accurate and ready for various purposes.

We save the generated masks for two reasons:
- To refine the annotations in an annotation tool like Roboflow Annotate, which allows for easy editing and validation of the data.
- To use the annotations for training other models, such as real-time object detectors like RF-DETR, by providing them with a solid foundation of annotated data.
For this tutorial, we will save the detections in the Pascal VOC XML format, which is compatible with many annotation tools and machine learning frameworks.
When saving the annotations, you can adjust the following parameters to fine-tune the results:
min_image_area_percentage: This parameter defines the minimum area percentage of a mask in relation to the total image area. Masks with an area smaller than this percentage will be discarded. This helps to filter out small, potentially noisy detections.max_image_area_percentage: Similarly, this parameter defines the maximum area percentage of a mask in relation to the total image area. Masks with an area larger than this percentage will be discarded. This helps to filter out large, potentially erroneous detections.approximation_percentage: This parameter controls the simplification of the mask polygons. A higher percentage results in fewer points in the polygon and a more simplified shape, while a lower percentage preserves more details of the original mask. Adjusting this value can help balance the trade-off between the accuracy and complexity of the mask shapes.
Here's an example of how to save the annotations using the supervision package:
import supervision as sv
dataset = sv.Dataset(...)
dataset.as_pascal_voc(
annotations_directory_path='path/to/annotations/directory',
min_image_area_percentage=0.002,
max_image_area_percentage=0.80,
approximation_percentage=0.75
)By adjusting these parameters, you can control the quality of the automated annotations and fine-tune the results to meet your specific needs.
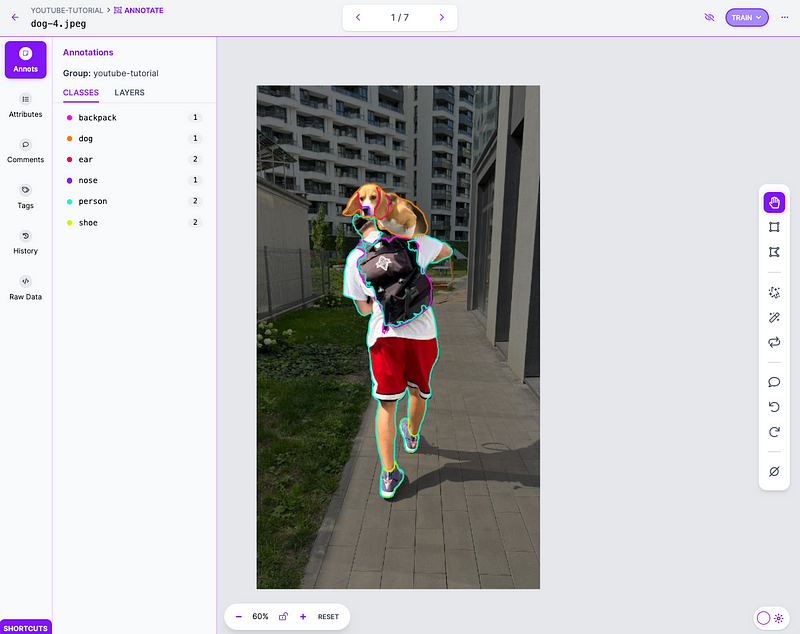
Editing Annotations in Roboflow Annotate
After the automated labeling process is complete, you'll want to clean up the data to ensure the annotations meet your needs. Roboflow Annotate provides a web-based platform for this task, with one-click polygon labeling powered by SAM.
Converting Object Detection Datasets into Instance Segmentation Datasets
If you already have a dataset annotated with bounding boxes and want to convert it into an instance segmentation dataset, you can use SAM standalone because the model can process existing bounding boxes.
First, download your object detection dataset into your Python environment. If you store your dataset in Roboflow, you can export it manually or use roboflow package to do that. Then, loop over the bounding boxes for each image, querying SAM for each one separately to generate an instance segmentation mask. Finally, save the resulting masks and annotations.

Conclusions
The quality of obtained labels using Grounding DINO and SAM largely depends on the classes you want to annotate. You can expect excellent results for common classes that appear in popular datasets. However, for obscure classes, the quality of annotations might be poor. To assess the effectiveness of these models for your specific use case, it is recommended to start with a small, representative set of images from your dataset.
It's important to note that, despite the latest breakthroughs in the computer vision space, we are still not ready to automate the annotation process fully. Human validation and curation are essential to ensure optimal outcomes. Nonetheless, leveraging models like Grounding DINO and SAM can result in significant time savings when annotating an entire dataset, allowing you to focus on refining the results and training more accurate machine learning models.
Exciting Announcement 🔥
We're thrilled to announce that we are developing a Python library to streamline the process of transferring knowledge from powerful zero-shot computer vision models like Grounding DINO, SAM, CLIP, and others to real-time detectors like RF-DETR. This innovation will revolutionize dataset annotation and accelerate CV projects.
Learn about Segment Anything 3 (SAM 3), a zero-shot image segmentation model that detects, segments, and tracks objects in images and videos based on concept prompts.
Cite this Post
Use the following entry to cite this post in your research:
Piotr Skalski. (Apr 21, 2023). Zero-Shot Image Annotation with Grounding DINO and SAM - A Notebook Tutorial. Roboflow Blog: https://blog.roboflow.com/enhance-image-annotation-with-grounding-dino-and-sam/