
As of March 2023, there is a new SOTA zero-shot object detection model - Grounding DINO. In this post, we will talk about the advantages of Grounding DINO, analyze the model architecture, and provide real prompt examples. To jump right to the model, use the Jupyter notebook to start trying it yourself.
Let's dive in!
Check out our Autodistill guide for more information, and our Autodistill Grounding DINO documentation.
Introduction
Most object detection models are trained to identify a narrow predetermined collection of classes. The main problem with this is the lack of flexibility. Every time you want to expand or change the set of recognizable objects, you have to collect data, label it, and train the model again. This — of course — is time-consuming and expensive.
Zero-shot detectors want to break this status quo by making it possible to detect new objects without re-training a model. All you have to do is change the prompt and the model will detect the objects you describe.
Below we see two images visualizing predictions made with Grounding DINO — the new SOTA zero-shot object detection model.
In the case of the image on the left, we prompted the model to identify the class "chair" — a class belonging to the COCO dataset. The model managed to detect all objects of this class without any problems.
For the image on the right, we tried to find the boundary of the model's knowledge and asked about the dog's tail. This object — of course — is not in any of the commonly used datasets, and yet it has been found.

Grounding DINO Performance
Grounding DINO achieves a 52.5 AP on the COCO detection zero-shot transfer benchmark — without any training data from COCO. After finetuning with COCO data, Grounding DINO reaches 63.0 AP. It sets a new record on the ODinW zero-shot benchmark with a mean of 26.1 AP.
Advantages of Grounding DINO
- Zero-Shot Object Detection — Grounding DINO excels at detecting objects even when they are not part of the predefined set of classes in the training data. This unique capability enables the model to adapt to novel objects and scenarios, making it highly versatile and applicable to various real-world tasks.
- Referring Expression Comprehension (REC) — Identifying and localizing a specific object or region within an image is based on a given textual description. In other words, instead of detecting people and chairs in an image and then writing custom logic to determine whether a chair is occupied, prompt engineering can be used to ask the model to detect only those chairs where a person is sitting. This requires the model to possess a deep understanding of both the language and the visual content, as well as the ability to associate words or phrases with corresponding visual elements.
- Elimination of Hand-Designed Components like NMS — Grounding DINO simplifies the object detection pipeline by removing the need for hand-designed components, such as Non-Maximum Suppression (NMS). This streamlines the model architecture and training process while improving efficiency and performance.

Grounding DINO Architecture
Grounding DINO aims to merge concepts found in the DINO and GLIP papers. DINO, a transformer-based detection method, offers state-of-the-art object detection performance and end-to-end optimization, eliminating the need for handcrafted modules like NMS (Non-Maximum Suppression).
On the other hand, GLIP focuses on phrase grounding. This task involves associating phrases or words from a given text with corresponding visual elements in an image or video, effectively linking textual descriptions to their respective visual representations.
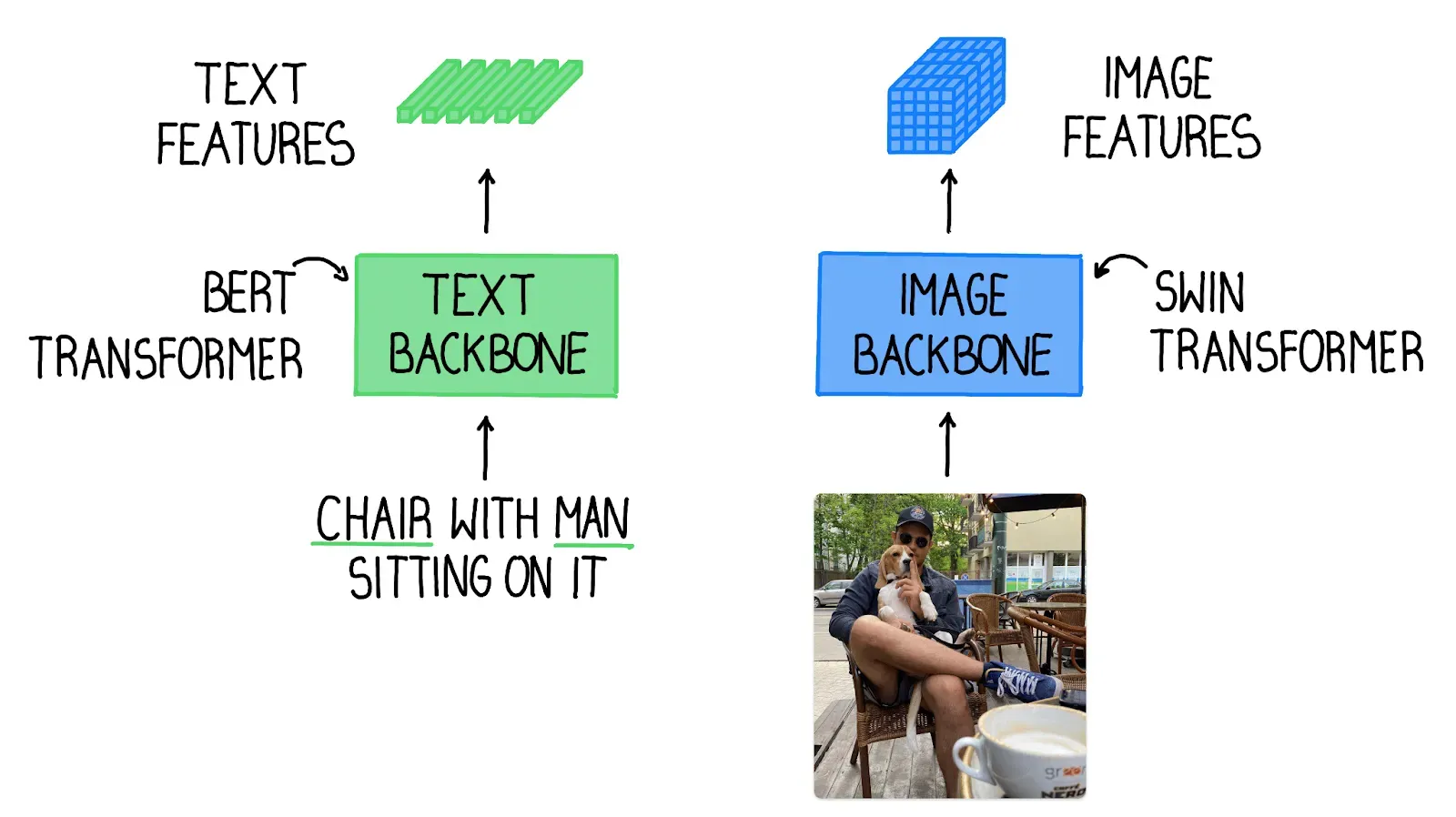
Text backbone and Image backbone — Multiscale image features are extracted using an image backbone like Swin Transformer, and text features are extracted with a text backbone like BERT.
Feature enhancer — After vanilla image and text features are extracted, they are fed into a feature enhancer for cross-modality feature fusion. The feature enhancer includes multiple feature enhancer layers. Deformable self-attention is leveraged to enhance image features, and vanilla self-attention is utilized for text feature enhancers.

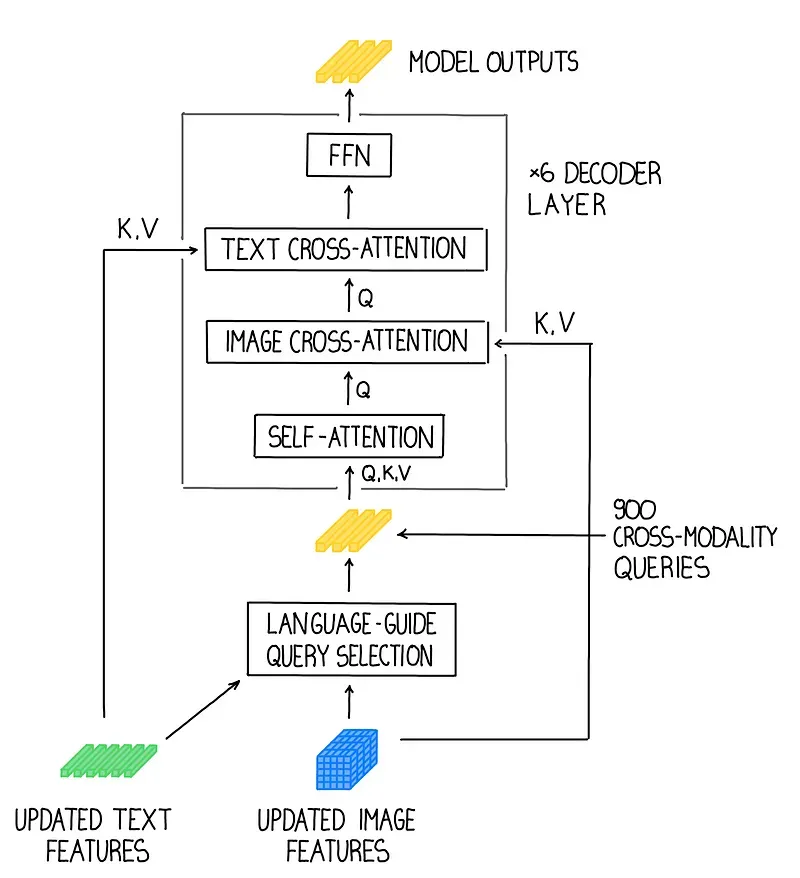
Language-guided query selection — To effectively leverage the input text for guiding object detection, a language-guided query selection module is designed to select features more relevant to the input text as decoder queries.
Cross-modality decoder — A cross-modality decoder is developed to combine image and text modality features. Each cross-modality query is fed into a self-attention layer, an image cross-attention layer to combine image features, a text cross-attention layer to combine text features, and an FFN layer in each cross-modality decoder layer. Each decoder layer has an extra text cross-attention layer compared with the DINO decoder layer, as text information needs to be injected into queries for better modality alignment.
Try Grounding DINO and Examples
To make it easier for you to experiment with the model, we have prepared a Jupyter notebook that you can test, among other places, on Google Colab.
As mentioned earlier, Grounding DINO allows precise detection with ROC. Instead of asking about all the chairs in the image, we can narrow the search to only those chairs occupied by a person using the following prompt — "chair with a man sitting on it".
We can see that the model returns not only a narrowed set of chairs but also a detected "man" — an additional noun found in the prompt.

As with GLIP, the quality of the predictions may be improved through appropriate prompt engineering. In the case of the photo below, querying the model with a simple query — "napkin" — we will not detect any objects.
In such a situation, it is helpful to provide more details describing the object we are looking for such as "blue napkin" and "napkin on the table" to achieve the desired output.

Suggestions for Using Grounding DINO
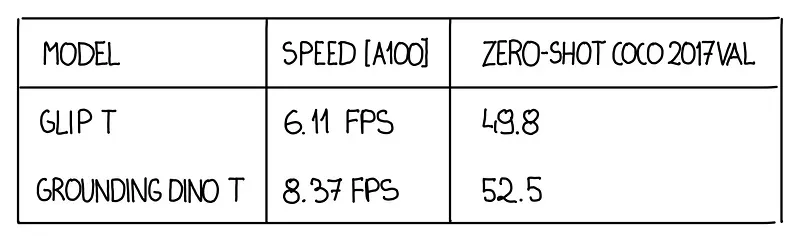
As you can see in the table at the beginning of the blog post, Grounding DINO is faster than GLIP but still too slow to consider in real-time scenarios. RF-DETR is safe for now.
However, the model can shine in tasks where flexibility and versatility are important. Grounding DINO can be successfully used for automatic data annotation or replacing heavy models with many classes.
With REC, Grounding DINO can also greatly simplify the image and video processing pipelines by enabling detection relationships to be analyzed using language constraints rather than complex and error-prone hand-made components.
Conclusion
Grounding DINO sets a new standard in the world of object detection by offering a highly adaptable and flexible zero-shot detection model. The model's ability to identify objects outside its training set and understand both language and visual content allows it to excel in various real-world tasks.
Grounding DINO is undoubtedly a breakthrough that will pave the way for more innovative applications in object detection and beyond.
Resources
[1] DINO Paper — DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
[2] GLIP Paper — Grounded Language-Image Pre-training
[3] Grounding DINO Paper — Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Cite this Post
Use the following entry to cite this post in your research:
Piotr Skalski. (Mar 30, 2023). Grounding DINO : SOTA Zero-Shot Object Detection. Roboflow Blog: https://blog.roboflow.com/grounding-dino-zero-shot-object-detection/