
YOLO (You Only Look Once) is a family of object detection models that began with Joseph Redmon's single-stage architecture in 2016, combining bounding box prediction and class labeling into one end-to-end network rather than the two-stage approach used by models like Faster RCNN. The family spans YOLOv2 through YOLOv27, with later versions written by different authors and varying goals. RF-DETR outperforms YOLO on both speed and accuracy, trains in Roboflow, and avoids YOLOv8's AGPL licensing requirements.
YOLO (You Only Look Once) is a family of computer vision models that has gained significant fanfare since Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi introduced the novel architecture in 2016 at CVPR, even winning OpenCV's People Choice Awards.
But what exactly is the YOLO computer vision family of models? Where did YOLO come from, why is it novel, and why do there seem to be so many versions?
The Origins of YOLO: You Only Look Once
The original YOLO (You Only Look Once) was written by Joseph Redmon in a custom framework called Darknet in 2016. Darknet is a very flexible research framework written in low level languages and has produced a series of some of the best realtime object detectors in computer vision: YOLO, YOLOv2, YOLOv3, YOLOv4, YOLOv5, YOLOV6, YOLOV7, YOLOv8, YOLO-NAS, YOLO-World, YOLOv9, YOLOv10, YOLOv11, YOLOv12, YOLO26, and YOLO27.

Notably, YOLOv2 and YOLOv3 are both by Joseph Redmon. YOLO models after YOLOv3 are written by new authors and, rather than being considered strictly sequential releases to YOLOv3, have varying goals based on the authors' whom released them.
The original YOLO model was the first object detection network to combine the problem of drawing bounding boxes and identifying class labels in one end-to-end differentiable network.
Some object detection models treat the detection pass as a two-part problem. First, identify the regions of interest (bounding boxes) for where an object is present. Second, classify that specific region of interest. This is considered a two-stage detector, and popular models like Faster RCNN leverage this approach.
Compare YOLO Models
We have made an interactive model playground in which you can compare several YOLO models. The playground is configured to use the base checkpoints trained on the Microsoft COCO dataset for YOLOv8, YOLOv9, YOLOv10, and YOLO11. The workflow can detect COCO classes like cats and dogs and cars.
Try it below:
Object detection model leaderboard
The Roboflow computer vision model leaderboard benchmarks popular object detection models against the Microsoft COCO dataset. The Microsoft COCO dataset is commonly used to evaluate and compare the performance of object detection models.
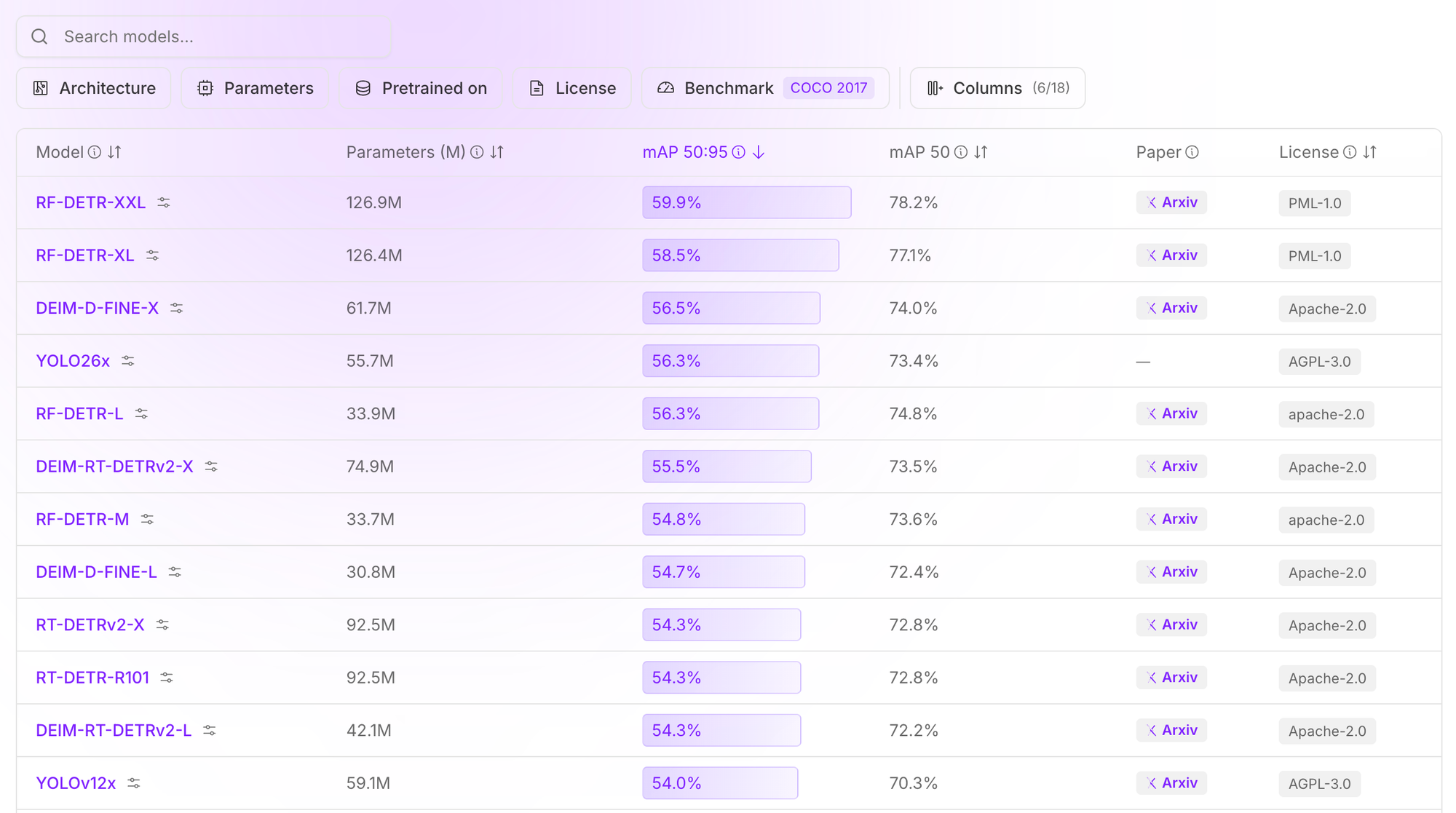
This project is open source, with code available that is used for benchmarking. This means you can verify the results of the data in the leaderboard table to understand relative YOLO model performance.
The YOLO Algorithm and Architecture
YOLO is a single stage detector, handling both the object identification and classification in a single pass of the network. YOLO is not the only single stage detection models (e.g. MobileNetSSDv2 is another popular single shot detector), but it is generally more performant in terms of speed and accuracy.
In treating the detection task as a single shot regression approach for identifying bounding boxes, YOLO models are often very fast and very small – often making them faster to train and easier to deploy, especially to compute-limited edge devices.
What Are YOLO Models Used For?
The YOLO algorithm is used for real-time object detection. Before YOLO, R-CNNs were among the most common method of detecting objects, but the were slow and not as useful for real-time applications. YOLO provides the speed necessary for use cases that require fast inference, such as detecting cars, identifying animals, and monitoring for safety violations.
Here are a few more situations where YOLO might be useful:
- Identifying intruders in a factory.
- Monitoring vehicle movement on a building site.
- Understanding traffic patterns on a road (i.e. finding the times during which a road is most and least used).
- Identifying smoke from fires in the wild.
- Monitoring to ensure workers wear the right PPE in certain environments (i.e. while using tools or working with chemicals that emit hazardous fumes).
The use cases for YOLO are vast. If you need to set up a camera to detect objects in real-time, YOLO is always worth considering.
What Is YOLOv2?
YOLOv2 was released in 2017, earning an honorable paper mention at CVPR 2017. The architecture made a number of iterative improvements on top of YOLO including BatchNorm, higher resolution, and anchor boxes.
YOLOv3: The next version
YOLOv3 was released in 2018. (The YOLOv3 paper is perhaps one of the most readable papers in computer vision research given its colloquial tone.)
YOLOv3 built upon previous models by adding an objectness score to bounding box prediction, added connections to the backbone network layers, and made predictions at three separate levels of granularity to improve performance on smaller objects.
The Newest YOLO Models
After the release of YOLOv3, Joseph Redmon stepped away from computer vision research. Researchers like Alexey Bochkovskiy and innovators like Glenn Jocher began to open source their advancements in computer vision research. Groups like Baidu also released their own implementations of YOLO (like PP-YOLO), demonstrating an improvement in mAP and decrease in latency.
Let's talk through each of the newest YOLo models one-by-one.
YOLOv4
YOLOv4, released April 2020 by Alexey Bochkovskiy, became the first paper in the "YOLO family" to not be authored by Joseph Redmon. YOLOv4 introduced improvements like improved feature aggregation, a "bag of freebies" (with augmentations), mish activation, and more. (See a detailed breakdown of YOLOv4.)
YOLOv5
YOLOv5 only requires the installation of torch and some lightweight python libraries. The YOLOv5 models train extremely quickly which helps cut down on experimentation costs as you build your model. You can infer with YOLOv5 on individual images, batch images, video feeds, or webcam ports and easily translate YOLOv5 from PyTorch weights to ONXX weights to CoreML to iOS.
PP-YOLO
PP-YOLO, released in August 2020 by Baidu, surpasses YOLOv4's performance metrics on the COCO dataset. The "PP" stands for "PaddlePaddle," Baidu's neural network framework (akin to Google's TensorFlow). PP-YOLO notes improved performance through taking advantage of a replaced improvements like a model backbone, DropBlock regularization, Matrix NMS, and more. (See a detailed breakdown of PP-YOLO.)
Scaled YOLOv4
Scaled YOLOv4 came out in November 2020 by Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao. The model takes advantage of Cross Stage Partial networks to scale up the size of the network while maintaining both accuracy and speed of YOLOv4. Notably, Scaled YOLOv4 takes advantage of the training framework released in YOLOv5.
PP-YOLOv2
PP-YOLOv2, again authored by the Baidu team, was released in April 2021. PP-YOLOv2 made minor tweaks to PP-YOLO to achieve improved performance, including adding the mish activation function and Path Aggregation Network (sensing a trend in improvements flowing from one network to the next?).
For more information, check out our detailed breakdown of PP-YOLOv2.
YOLOv6
YOLOv6 iterates on the YOLO backbone and neck by redesigning them with the hardware in mind - introducing what they call EfficientRep Backbone and Rep-PAN Neck.
In YOLOv6, the head is decoupled, meaning the network has additional layers separating these features from the final head, which has empirically been shown to increase performance. In addition to architectural changes, the YOLOv6 repository also implements some enhancements to the training pipeline including anchor free (not NMS free) training, SimOTA tag assignment, and SIoU box regression loss.
YOLOv7
In YOLOv7, the authors build on research that has happened on this topic keeping in mind the amount of memory it takes to keep layers in memory along with the distance that it takes a gradient to back-propagate through the layers - the shorter the gradient, the more powerfully their network will be able to learn. The final layer aggregation they choose is E-ELAN an extend version of the ELAN computational block.
See our detailed breakdown of YOLOv7 to learn more.
YOLOv8
YOLOv8 includes numerous architectural and developer experience changes and improvements over YOLOv5. YOLOv8 comes with a lot of developer-convenience features, from an easy-to-use CLI to a well-structured Python package. YOLOv8 is an anchor-free model. This means it predicts directly the center of an object instead of the offset from a known anchor box.
YOLO-NAS
YOLO-NAS, created by Deci AI, beat its predecessors — particularly YOLOv6 and YOLOv8 — by achieving a higher mAP value on the COCO dataset while keeping lower latency. YOLO-NAS is also the best on the Roboflow 100 dataset benchmark, indicating the ease of its fine-tuning on a custom dataset. Deci's proprietary Neural Architecture Search technology generated the YOLO-NAS model. The engine lets you input any task, data characteristics (access to data is not required), inference environment and performance targets, and then guides you to find the optimal architecture that delivers the best balance between accuracy and inference speed for your specific application.
See our detailed breakdown of YOLO-NAS to learn more.
YOLO-World
YOLO-World is a real-time, zero-shot object detection model developed by Tencent’s AI Lab. Because YOLO-World is a zero-shot model, you can provide text prompts to the model to identify objects of interest in an image without training or fine-tuning a model.
YOLO-World introduced a new paradigm of object detection: “prompt then detect”. This eliminates the need for just-in-time text encoding, a property of other zero-shot models that reduces the potential speed of the model. According to the YOLO World paper, the small version of the model achieves up to 74.1 FPS on a V100 GPU.
See our detailed breakdown of YOLO-WORLD to learn more.
YOLOv9
On February 21st, 2024, Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao released the “YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information'' paper, which introduces a new computer vision model architecture: YOLOv9. The source code was made available, allowing anyone to train their own YOLOv9 models.
According to the project research team, the YOLOv9 achieves a higher mAP than existing popular YOLO models such as YOLOv8, YOLOv7, and YOLOv5, when benchmarked against the MS COCO dataset.
See our detailed breakdown of YOLOv9 to learn more.
YOLOv10
Released on May 23, 2024, YOLOv10 is a real-time object detection model developed by researchers from Tsinghua University. YOLOv10 represents the state of the art in object detection, achieving lower latency than previous YOLO models with fewer parameters.
In terms of performance, the YOLOv10 paper notes “our YOLOv10-S is 1.8× faster than RT-DETR-R18 under the similar AP on COCO, meanwhile enjoying 2.8× smaller number of parameters and FLOPs. Compared with YOLOv9-C, YOLOv10-B has 46\% less latency and 25\% fewer parameters for the same performance.”
See our overview of the YOLOv10 architecture and how to train YOLOv10 on your custom data.
YOLOv11
YOLOv11 is a computer vision model architecture developed by Ultralytics, the creators of the YOLOv5 and YOLOv8 models. YOLOv11 supports object detection, segmentation, classification, keypoint detection, and oriented bounding box (OBB) detection. The YOLOv11x model, the largest in the series, reportedly achieves a 54.7% mAP score when evaluated against the Microsoft COCO benchmark. The smallest model, YOLOv11n reportedly achieves a 39.5% mAP score when evaluated against the same dataset.
See our overview of the YOLOv11 model and how to train YOLOv11 on your custom data.
YOLOv12
Released on February 18th, 2025, YOLOv12 is a state-of-the-art computer vision model architecture. YOLOv12 was made by researchers Yunjie Tian, Qixiang Ye, David Doermann and introduced in the paper “YOLOv12: Attention-Centric Real-Time Object Detectors”. YOLOv12 has an accompanying open source implementation that you can use to fine-tune models.
The model achieves both a lower latency and higher mAP when benchmarked on the Microsoft COCO dataset.
YOLO26
YOLO26 is an end-to-end, edge-optimized model that supports five core computer vision tasks: object detection, instance segmentation, pose estimation, oriented object detection (OBB), and image classification. The framework offers comprehensive functionality across all these tasks, allowing users to seamlessly perform training, validation, inference, and export for every model variant.
YOLO26 achieves the highest accuracy in the YOLO lineage of models but accuracy does not beat RF-DETR for accuracy.
YOLO27
YOLO27 is the next generation of the YOLO model family, expected to be released in September 2026. It expands the family from 2D tasks into 3D perception. Included are two new models: YOLO-Depth for monocular depth estimation from a single camera, and YOLO-StereoDepth, which computes absolute distances from a two-camera baseline and is positioned as a camera-native alternative to lidar for robotics.
Why Should I Use a YOLO Model?
YOLO models are popular for a few durable reasons. First, they are fast. YOLO models process video feeds at high frames-per-second rates, which matters when you are running live inference on a camera to track something that changes quickly (the position of a ball on a football pitch, or a package on a conveyor belt). The newest release continues this focus with NMS-free inference and strong CPU performance for edge devices.
Second, the YOLO family has more than a decade of ecosystem behind it. The models are open source, the community is large, and there is no shortage of tutorials, integrations, and forum answers for nearly any problem you hit. Learn more about training YOLO models here.
Overall though, we recommend RF-DETR for new detection projects. On accuracy, transformer-based detectors now lead: RF-DETR-2XL is the first real-time model to break 60 AP on the COCO benchmark, and RF-DETR tops RF100-VL, the benchmark that measures how well models transfer to real-world custom datasets, which is the job most teams actually have. Its DINOv2 backbone also adapts well to small datasets, so you need fewer labeled images to reach production accuracy.
On licensing, recent YOLO releases ship under AGPL-3.0, which requires open-sourcing derivative works or purchasing a commercial license; RF-DETR's core models and code are Apache 2.0, so the model you train can ship in a commercial product without licensing friction.
To (YOLO) Infinity, and Beyond
Models (loosely) based on the original YOLO paper in 2016 continue to blossom in the computer vision space. We'll continue to keep you up to date on how to train YOLO models, architecture improvements, and more.
Cite this Post
Use the following entry to cite this post in your research:
Erik Kokalj. (May 14, 2026). What Is YOLO? The Guide to YOLO Models. Roboflow Blog: https://blog.roboflow.com/guide-to-yolo-models/