
YOLOv6 (MT-YOLOv6) is a single-stage object detection model developed by Meituan's technical team that achieves higher mAP on MS COCO than YOLOv5, with scores ranging from 35.9 (YOLOv6-N) to 52.5 (YOLOv6-L). This post covers the architectural changes behind those gains, from backbone and neck redesigns to training improvements, and gives a candid assessment of where the model fits relative to other YOLO variants for practitioners choosing a detector.
Meituan Technical Team recently released MT-YOLOv6 (shortened to YOLOv6), showcasing initial evaluation superior to incumbent open source object detection frameworks. In this article, we give a rundown of the changes made in YOLOv6 and our initial assessments of the new network and repository.
Let's get started!
If you are interested in learning how to train a YOLOv6 model, read our How to Train a YOLOv6 Model on a Custom Dataset guide.
What is YOLOv6?
YOLOv6 (also known as MT-YOLOv6) is a single-stage object detection model based on the YOLO architecture. The YOLOv6 model was developed by researchers at Meituan. YOLOv6 achieves stronger performance than YOLOv5 when benchmarked against the MS COCO dataset.
Who are the Meituan Technical Team?
We have all heard of OpenAI, Facebook AI Research, and Microsoft Research and we are accustomed to them publishing new AI research - but if the Meituan Technical Team are news to you, then we are in the same boat.
Meituan is a large e-commerce company in China, and their technical team is akin to what we might think of in the United States when we think about Amazon Research.
A Brief History of YOLO Models
YOLO (You Only Look Once) was first introduced by Joseph Redmon in 2015 to model object detection problems. The name was derived from the fact that the network was single-shot, that is, you inferred once through the network to get bounding box and class predictions.
Previous networks were trained to infer once for box predictions and once again passing the box patches through another piece of the network to predict the class of that box.
Redmon iterated on his approach, releasing YOLOv2 and YOLOv3. All of these networks were written in C in a deep learning framework that Redmon hand-rolled called Darknet.
Then Redmon dropped out of computer vision due to ethical concerns.
Computer Vision expert AlexeyAB picked up the torch and brought YOLO into the next iteration (still in Darknet) with the introduction of YOLOv4 and YOLOv4-tiny.
While Darknet had the advantages of allowing the maintainers to carefully tweak aspects of the network, it is hard to wield and development means rewriting everything from scratch (imagine hand-rolling your own back propagation for every new function you integrate... SiLU --> new backprop in C)
Enter YOLOv5. Glenn Jocher at Ultralytics lifted YOLO out of Darknet and into PyTorch, making everything a lot easier and the surrounding APIs much more tractable for machine learning python people (like me and many others).
Along with making things easier, Glenn leveled up the training pipeline of YOLO with new augmentation strategies and continually pushed in architecture tweaks as new methods were found to work in the computer vision community. YOLOv5 is one of the most popular AI repos today with over 28k stars.
Other YOLO networks have arisen, like YOLOX, PP-YOLO, and PP-YOLOv2, PP-YOLOE - but from our view, these networks haven't gained the same traction of the well-trodden YOLOv5 repository.
YOLOv6 Architectural Improvements
With every iteration of the YOLO model, the goal has been the same: learn how to predict bounding boxes around selected objects accurately, while keeping inference time at realtime speeds. The better the model, the less hardware that is required to train and deploy it.
YOLO models take an input image and pass it through a series of convolutional layers in the backbone. YOLO models then feed those backbone features through the neck. YOLO models then pass the neck features through to three heads, where the predict objectness, class, and box regression.
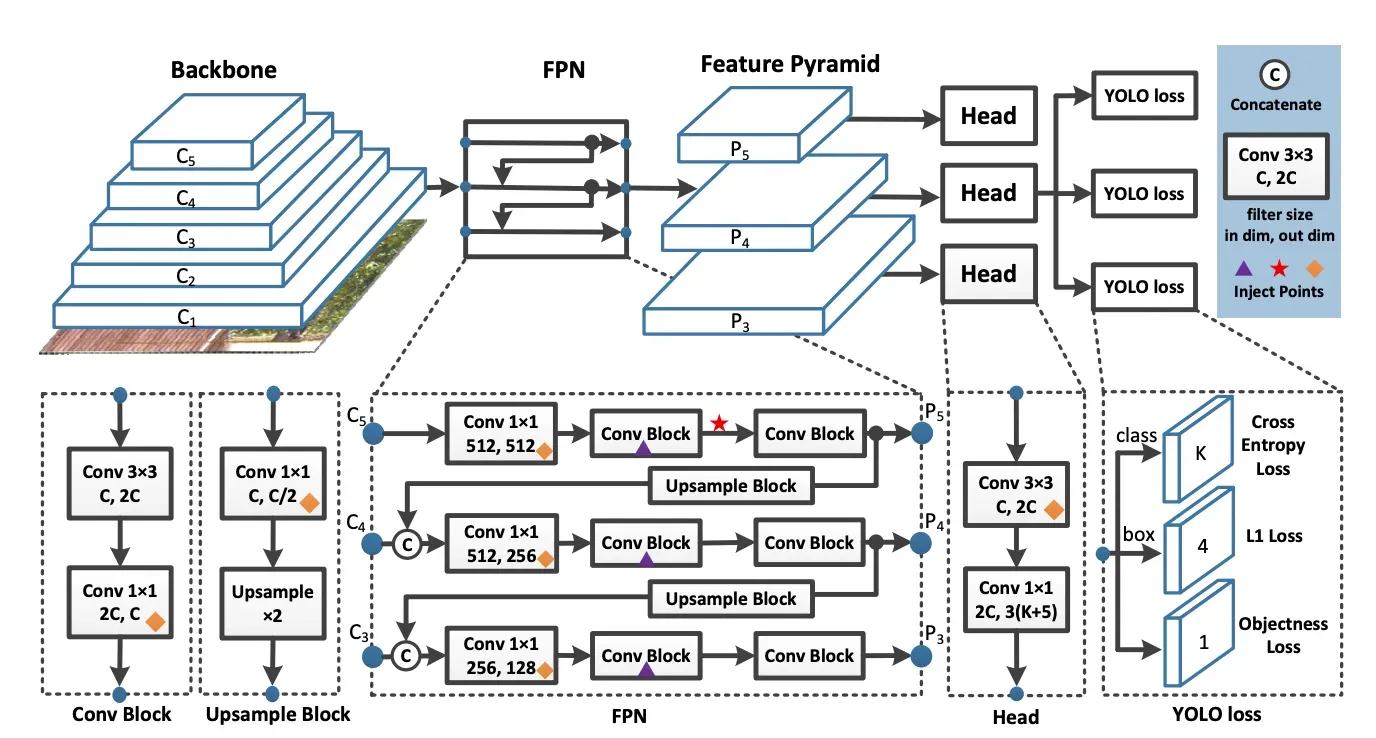
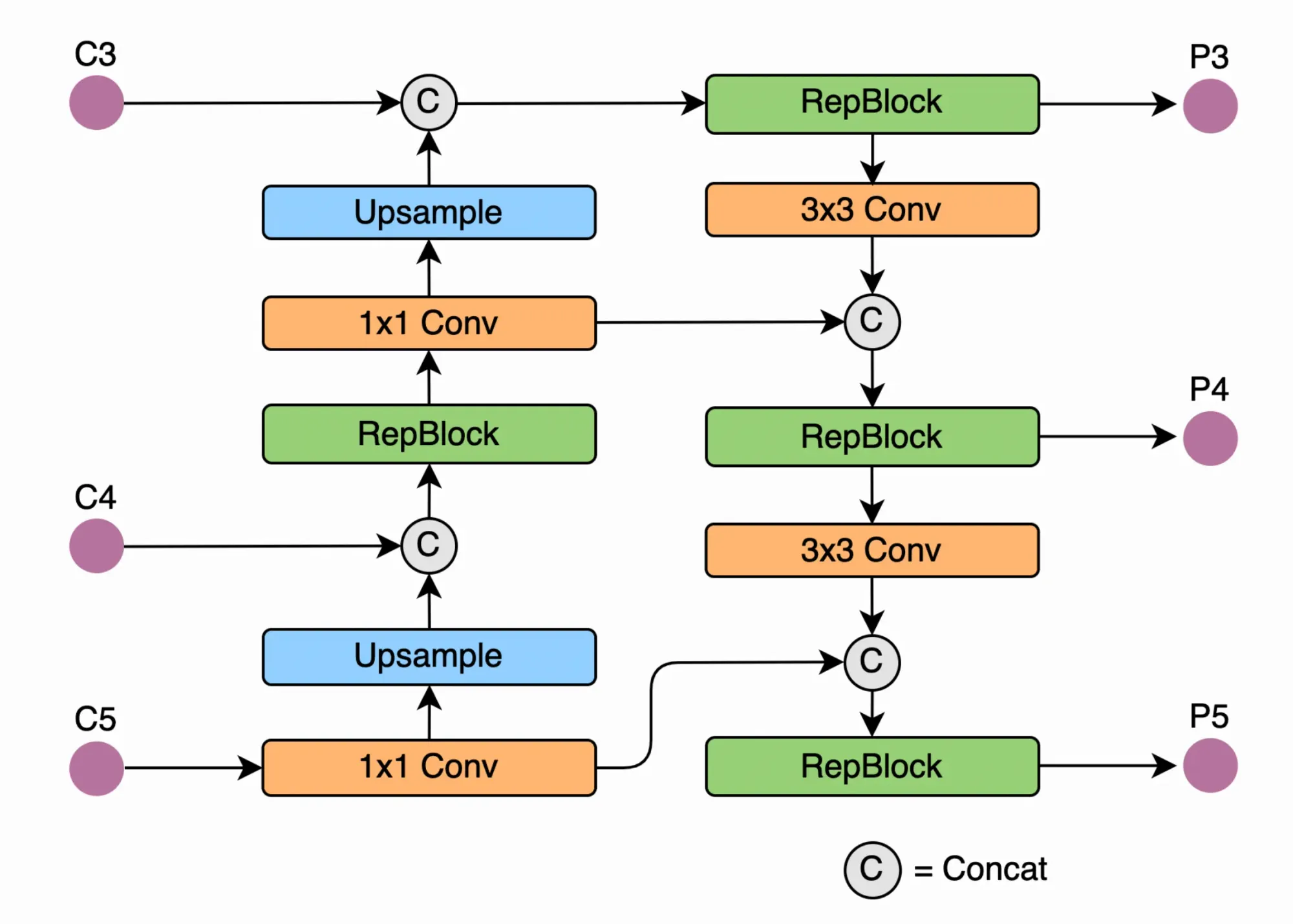
YOLOv6 iterates on the YOLO backbone and neck by redesigning them with the hardware in mind. The model introduces what the authors call EfficientRep Backbone and a Rep-PAN Neck.
In YOLO models up to and including YOLOv5, the classification and box regression heads share the same features. In YOLOx and YOLOv6, the head is decoupled. This means the network has additional layers that separates these features from the final head. This change has been shown empirically to increase model performance.
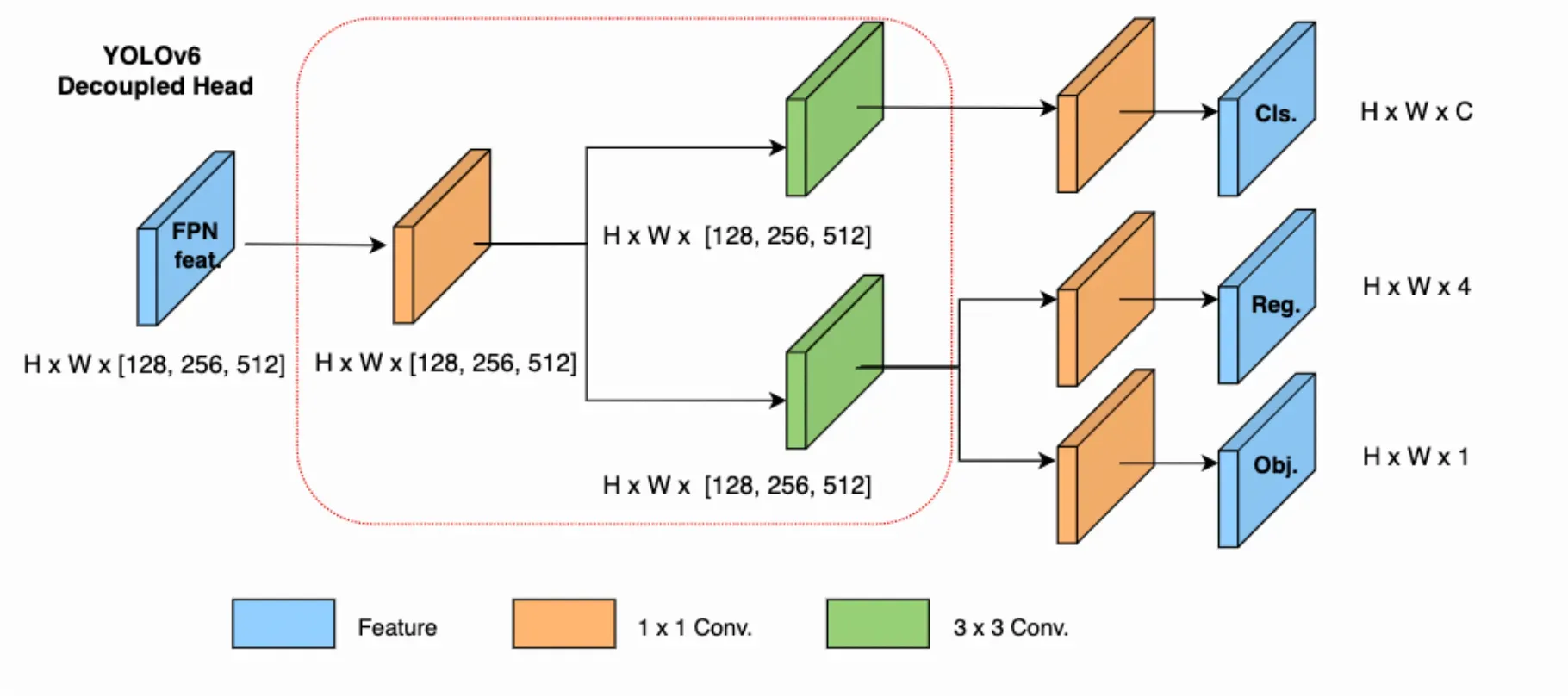
In addition to architectural changes, the YOLOv6 repository also implements some enhancements to the training pipeline including anchor free (not NMS free) training, SimOTA tag assignment, and SIoU box regression loss.
For more details on the YOLOv6 model, check out the YOLOv6 technical report.
Is YOLOv6 better than YOLOv5?
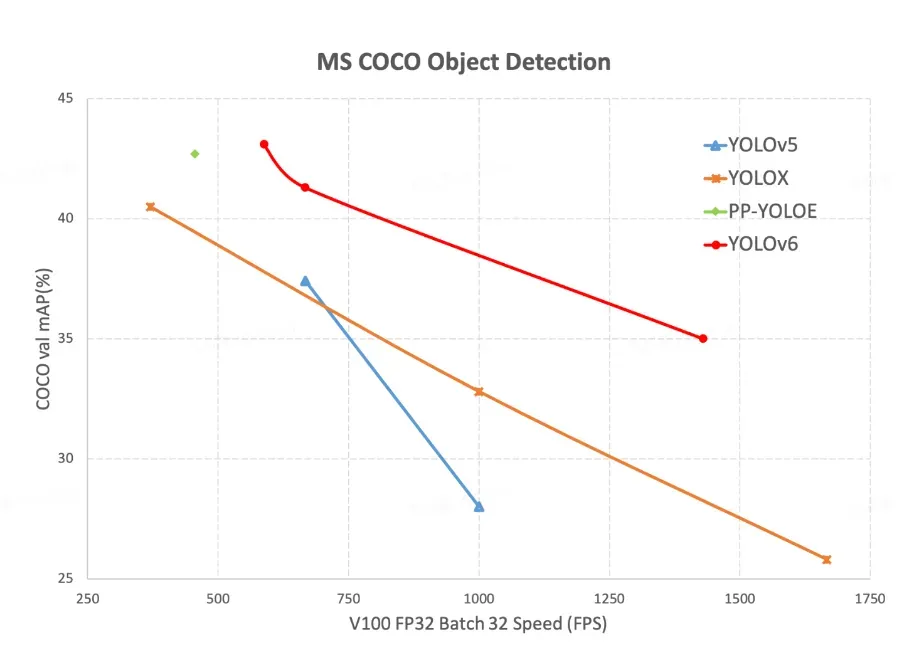
YOLOv6 achieves a higher mAP on COCO at various FPS rates compared to YOLOv5, YOLOX, and PPE-YOLOE. But, it is important to note that the COCO dataset is a proxy but not a perfect model for how these models will perform on your dataset.
The YOLOv6 model is benchmarked on the Tesla V100 GPU, where it is shown to model the COCO dataset more accurately than YOLOv5 at comparable inference speeds.
In the chart below, we can see the frames per second against mean average precision for different model sizes of YOLOv6 and YOLOv5.
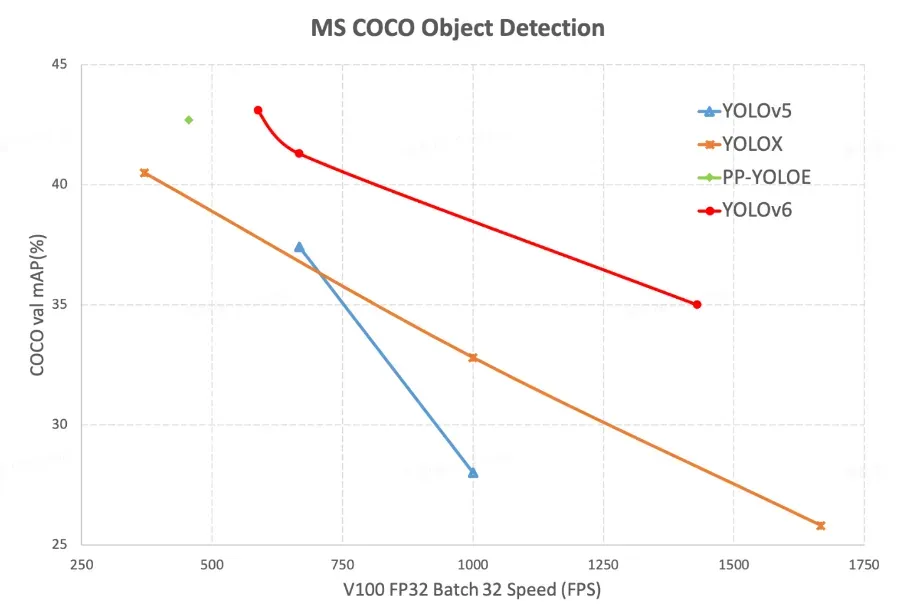
The above chart shows that YOLOv6 is a clear winner compared to the other YOLO models. YOLOv6 achieves a higher mAP compared to YOLOv5, YOLOX, and PP-YOLOE at all V100 FP32 Batch 32 speeds tested.
To add to our earlier point about evaluating models, the hardware speeds may not reconcile on your particular deployment. This is important to test. Since YOLOv5 has been around longer, you will be more likely to reach your deployment destination through model conversions with a YOLOv5 model.
YOLOv6 GitHub Repository Overview
If you want to use YOLOv6 yourself, you will want to pick up the YOLOv6 GitHub repository.
Like other new YOLO models, YOLOv6 is written in the familiar PyTorch framework.
Similar to YOLOv5, YOLOv6 offers boiled down APIs so you can interact with it from a high level without needing to dive into many details (unlike Darknet).
To invoke YOLOv6 training, you can use the command:
python tools/train.py --batch 32 --conf configs/yolov6s.py --data data/coco.yaml --device 0To invoke YOLOv6 inference, you use the command:
python tools/infer.py --weights yolov6s.pt --source img.jpg / imgdir
You can tweak your models configuration by toying with the configurations in config - though the one released should be considered optimal by default.
# YOLOv6n model
model = dict(
type='YOLOv6n',
pretrained=None,
depth_multiple=0.33,
width_multiple=0.25,
backbone=dict(
type='EfficientRep',
num_repeats=[1, 6, 12, 18, 6],
out_channels=[64, 128, 256, 512, 1024],
),
neck=dict(
type='RepPAN',
num_repeats=[12, 12, 12, 12],
out_channels=[256, 128, 128, 256, 256, 512],
),
head=dict(
type='EffiDeHead',
in_channels=[128, 256, 512],
num_layers=3,
begin_indices=24,
anchors=1,
out_indices=[17, 20, 23],
strides=[8, 16, 32],
iou_type='ciou'
)
)
solver = dict(
optim='SGD',
lr_scheduler='Cosine',
lr0=0.01,
lrf=0.01,
momentum=0.937,
weight_decay=0.0005,
warmup_epochs=3.0,
warmup_momentum=0.8,
warmup_bias_lr=0.1
)
data_aug = dict(
hsv_h=0.015,
hsv_s=0.7,
hsv_v=0.4,
degrees=0.0,
translate=0.1,
scale=0.5,
shear=0.0,
flipud=0.0,
fliplr=0.5,
mosaic=1.0,
mixup=0.0,
)The YOLOv6 repository already has 3000 stars. This is an insanely hot start for any GitHub repository.
Time will tell if the YOLOv6 authors maintain and evolve the repository with the same resolve as the YOLOv5 authors and community.
Should I Use YOLOv6?
To summarize our initial impressions, YOLOv6 shows initial promise in evaluation and trains well on custom data.
As a new repository, YOLOv6 is slightly harder to wield in practice than YOLOv5 and does not have as many established pathways and articles around using the network in practice for training, deployment and debugging. This is something that may change with time, and should not be prohibitive to your exploration. If YOLOv6 looks interesting, feel free to experiment!
As with any network, you should always train the model on your custom data to find out what works best. Curious on how to start training a YOLOv6 model? Check out the following tutorials:
As a sneak peek into YOLOv6 training, we have added our video on the topic here:
Happy training and happy inference!
Frequently Asked Questions
Who made YOLOv6?
The MT-YOLOv6 model was made by researchers at Meituan, a Chinese eCommerce platform.
What is the mAP of YOLOv6?
The mAP of YOLOv6 when benchmarked against COCO is 35.9 in the smallest model (YOLOv6-N) and 52.5 in the largest model (YOLOv6-L).
Further reading:
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz, Joseph Nelson. (Jan 4, 2024). What is YOLOv6? The Ultimate Guide.. Roboflow Blog: https://blog.roboflow.com/yolov6/