
YOLOv4-tiny has been released! You can use YOLOv4-tiny for much faster training and much faster object detection. In this article, we will walk through how to train YOLOv4-tiny on your own data to detect your own custom objects.
YOLOv4-tiny is especially useful if you have limited compute resources in either research or deployment, and are willing to tradeoff some detection performance for speed.
Want to Skip All This?
Roboflow is the easiest way to train and deploy your computer vision models. Our tools will get you up and running in hours instead of weeks and help your models improve the more data they see.
- YOLOv4-tiny Colab Notebook - contains the code in this tutorial
- Previous How to Train YOLOv4 post
- Public BCCD Dataset
If you prefer this post as a video, subscribe to the Roboflow YouTube channel.
How Does YOLOv4-tiny Compare to vanilla YOLOv4?
Comparing Evaluation Metrics
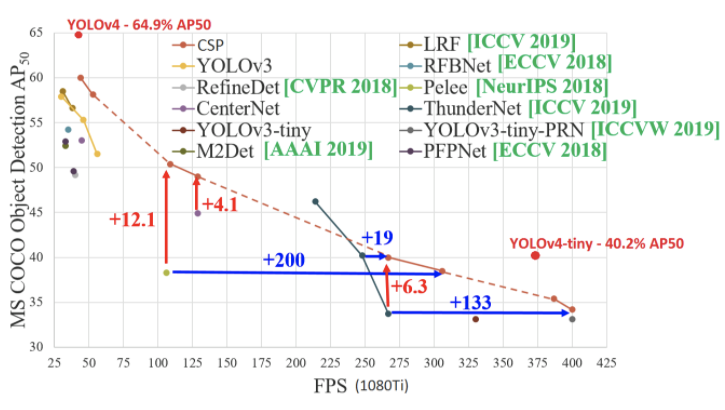
Performance metrics show that YOLOv4 tiny is roughly 8X as fast at inference time as YOLOv4 and roughly 2/3 as performant on MS COCO (a very hard dataset). On small custom detection tasks that are more tractable, you will see even less of a performance degradation. On the custom example in this tutorial, we see almost no degradation of performance as a result of decrease in model size.
Comparing Model Architectures
The primary difference between YOLOv4 tiny and YOLOv4 is that the network size is dramatically reduced. The number of convolutional layers in the CSP backbone are compressed. The number of YOLO layers are two instead of three and there are fewer anchor boxes for prediction. You can see the differences between the two networks for yourself in the config files:
If you are trying to detect small objects you should keep the third YOLO layer like yolov3-tiny_3l.cfg.
Scaled-YOLOv4 released
Checkout the modeling involved in creating YOLOv4-tiny in the paper on Scaled-YOLOv4. Scaled-YOLOv4 tops EfficientDet accross the curve.
Installing Darknet Dependencies and Framework for YOLOv4-tiny
We recommend working through this post side by side with the YOLO v4 tiny Colab Notebook.
And many of the details in this post cross apply with the general How to Train YOLO v4 tutorial, so that is a useful resource if you are searching for more in depth detail.
In order to set up our Darknet environment we need these dependencies:
- OpenCV
- Cuda Toolkit
- cuDNN
- GPU resources
- GPU Architecture
Thankfully, Google Colab takes care of the first four for us so we need only worry about GPU architecture.
For Google Colab users, we have added a cell that will automatically specify the architecture based on the detected GPU. If you are on a local machine (not Colab), have a look at the Makefile for your machine. You will need to change the following line to fit your GPU based on your GPU's compute capability:
ARCH= -gencode arch=compute_60,code=sm_60Then we clone the Darknet repository (we made some minor tweaks to configuration and print statements) and !make the Darknet program. If successful you will see a lot of strange printouts including:
g++ -std=c++11 -std=c++11 -Iinclude/ -I3rdparty/stb/include -DOPENCV `pkg-config --cflags opencv4 2> /dev/nullThen lastly, we will download the first 29 layers of the tiny YOLO to start our training from the COCO pretrained weights:
yolov4-tiny.conv.29 100%[===================>] 18.87M 16.0MB/s in 1.2s 16MB!
Download Custom Dataset for YOLOv4 tiny
For our custom dataset in this tutorial we are using the public blood cell detection dataset hosted on Roboflow Public Datasets. If you would like to follow along directly, fork that dataset. Otherwise you can upload your custom objects in any annotation format. To get upload your data to Roboflow, create a free Roboflow account.
Need to label your data with bounding boxes? Get started labeling with Roboflow Annotate, LabelMe, VoTT, or LabelImg tutorial.
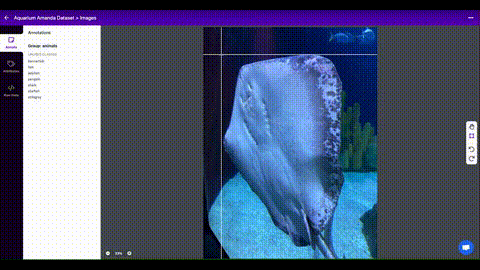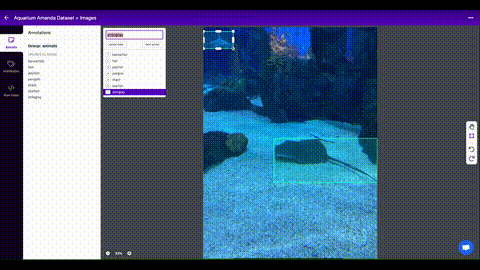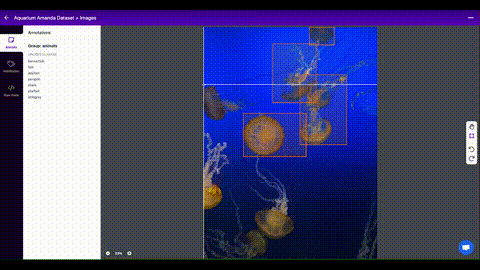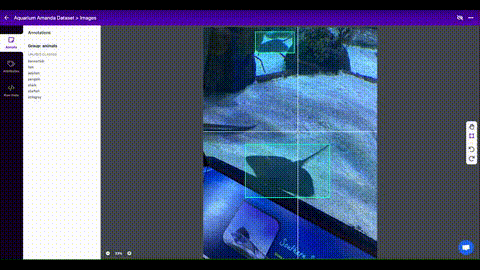
Once uploaded, we can choose preprocessing and augmentation steps. In this example we use auto-orient and resize to 416x416.
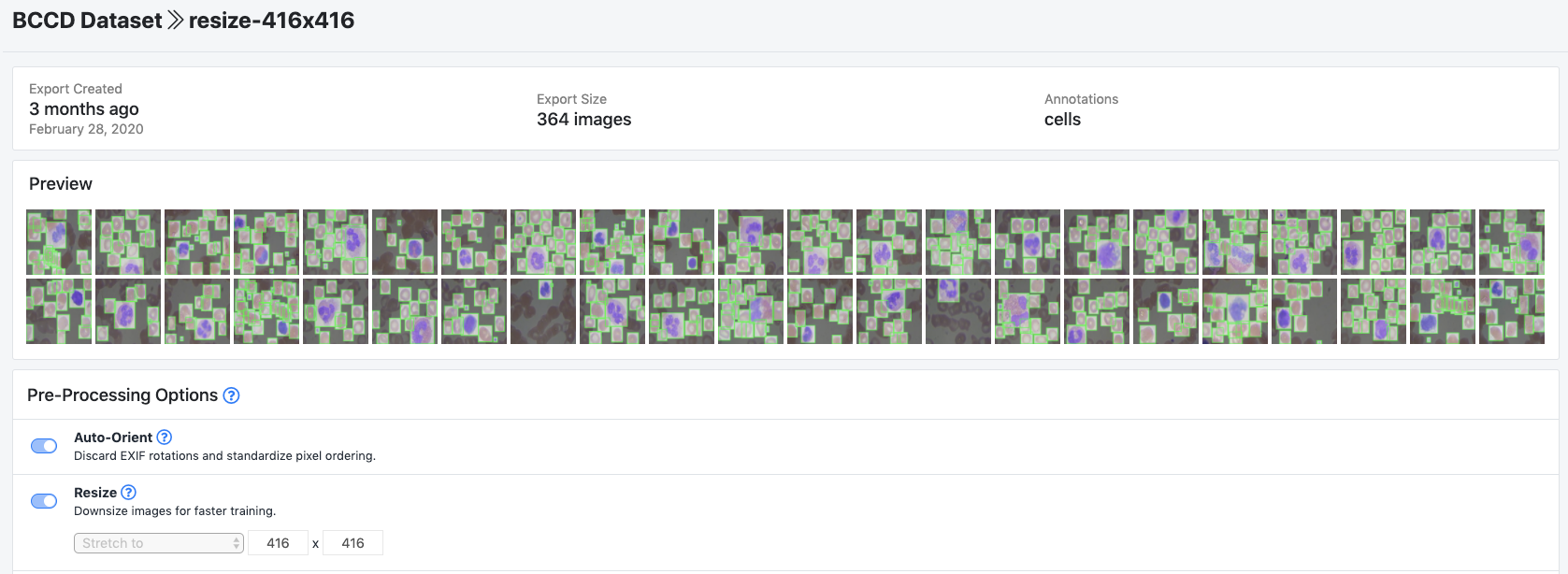
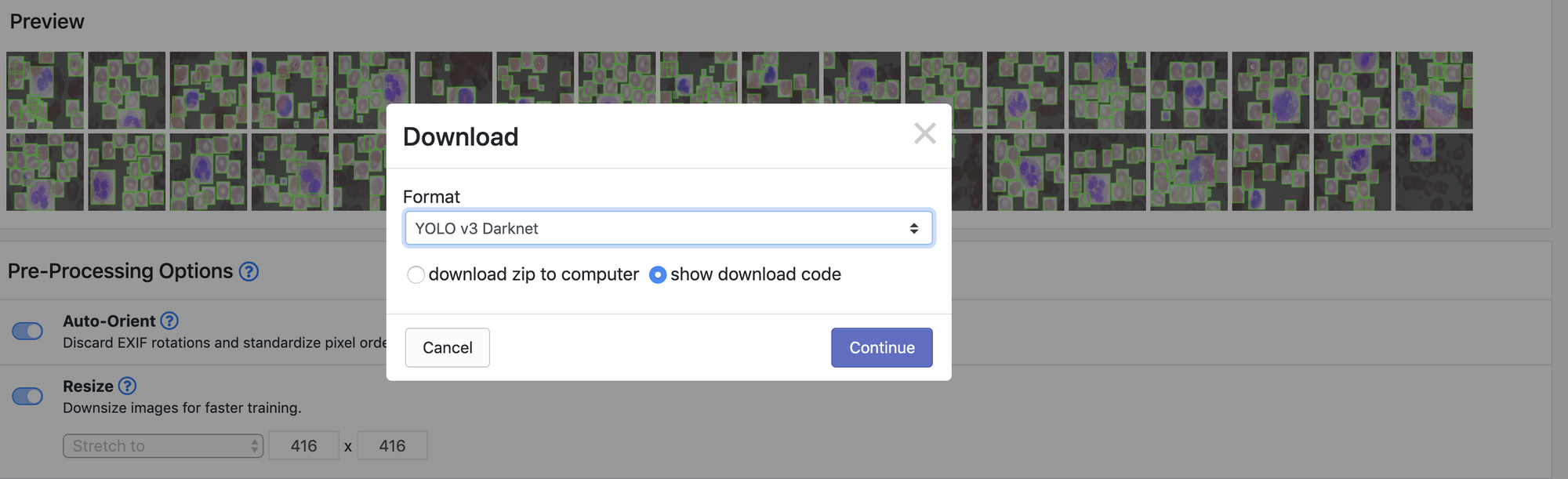
In order to generate a dataset version we click Generate and then Download, choosing YOLO Darknet format. This gives us a curl link that we can port into the Colab notebook for download.
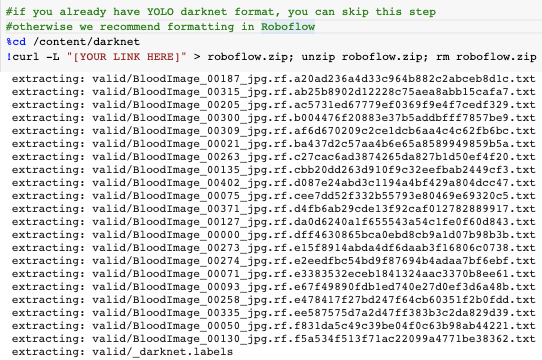
Once we have zipped our download, we paste the curl link into the notebook and run it!
Then we write a little bit of code to write our obj.data file to point Darknet towards our data for training.
✅ All set!
Write Custom YOLOv4-tiny Training Configuration
Next we write a custom YOLOv4-tiny training configuration.
The important takeaway here is that the YOLO models slightly adjust network architecture based on the number of classes in your custom dataset. And the length of training should also be adjusted based on the number of classes.
Thus, we create the following custom variables based on our dataset:
- num_classes
- max_batches (how long to train for)
- iteration steps
- layer filters
And write them into the configuration file as directed by the YOLOv4 repo.
Train Custom YOLOv4 tiny Detector
Once we have our environment, data, and training configuration secured we can move on to training the custom YOLOv4 tiny detector with the following command:
!./darknet detector train data/obj.data cfg/custom-yolov4-tiny-detector.cfg yolov4-tiny.conv.29 -dont_show -map
Kicking off training:
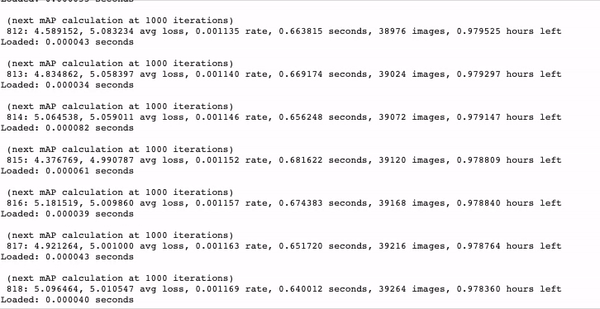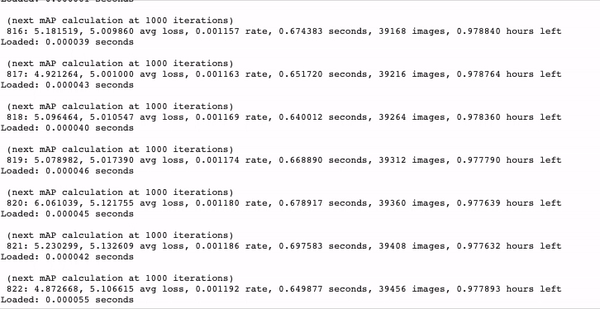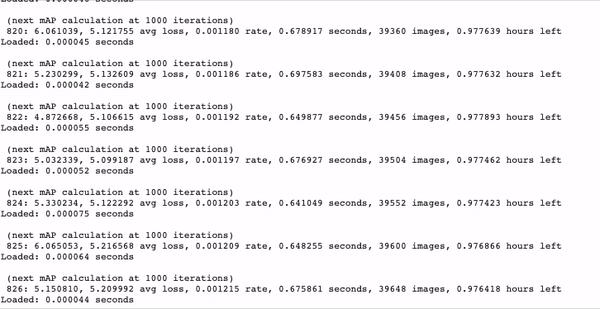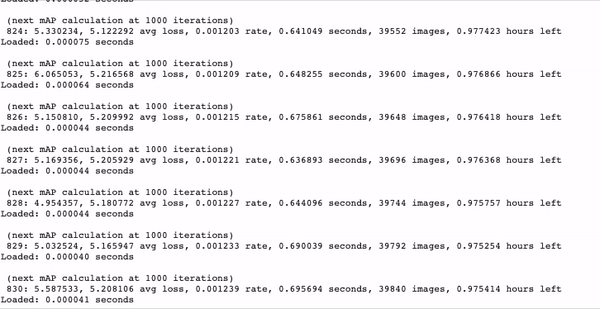
Approx. 1 hour training time for 350 images on a Tesla P-100.
We witnessed 10-20x faster training with YOLOv4 tiny as opposed to YOLOv4. This is truly phenomenal. YOLOv4 tiny is a very efficient model to begin trials with and to get a feel for your data.
As your model trains, watch for the mAP (mean average precision) calculation. If it is steadily rising this is a good sign, if it begins to deteriorate then your model has overfit to the training data.
Detect Custom Objects With YOLOv4-tiny from Saved Weights
When training has completed the darknet framework will drop backup/custom-yolov4-tiny-detector_best.weights where your model achieved the highest mAP on your validation set.
We can invoke these saved weights to infer detection on a test image:
!./darknet detect cfg/custom-yolov4-tiny-detector.cfg backup/custom-yolov4-tiny-detector_best.weights {img_path} -dont-show
Inferring:
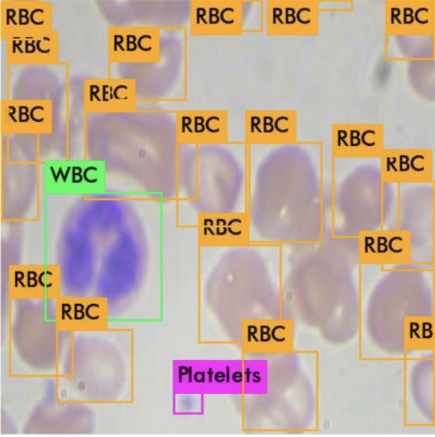
And the inference runs fast, blazingly fast:
test/BloodImage_00113_jpg.rf.a6d6a75c0ebfc703ecff95e2938be34d.jpg: Predicted in 3.131000 milli-seconds.
3ms, batch size 1, Tesla-P100!
From there, you can port the weights out of Colab for usage in your application, without having to retrain the next time.
Conclusion
Congratulations! Now you know how to train YOLOv4 tiny on a custom dataset. It trains very quickly and infers faster than pretty much any model out there.
Stay tuned for comparisons of YOLOv4 tiny to YOLOv5s.
You may enjoy also visiting training tutorials on how to:
And to learn more about the modeling:
Next Steps
To get even more out of the YOLOv4 repository, we have wrote this guide on advanced tactics in YOLOv4. I highly recommend checking that out after you've trained YOLOv4.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz, Samrat Sahoo. (Jul 1, 2020). Train a YOLOv4-tiny Model on a Custom Dataset. Roboflow Blog: https://blog.roboflow.com/train-yolov4-tiny-on-custom-data-lighting-fast-detection/