
YOLOv5 is a PyTorch-native, single-stage object detection model in the YOLO family, released in June 2020, with a CSP backbone, PA-Net neck, auto-learned anchor boxes, and four size variants (s/m/l/x). Its main contribution was bringing YOLO's training and deployment into PyTorch for fast training and easy use, though for a new custom detector today RF-DETR fine-tunes faster and more accurately under a permissive Apache 2.0 license.
This guide covers what is new in YOLOv5, how it is put together, and the benchmark results that came with its release.
Here's what we'll cover:
- What is new in YOLOv5?
- How does YOLOv5 compare to YOLOv4?
- What is different between YOLOv4 and YOLOv5?
- Should I use YOLOv4 or YOLOv5 for object detection?
If your goal is a detector you will train and deploy today, note that RF-DETR is Roboflow's real-time detection transformer, and it is faster to fine-tune and more accurate than YOLOv5 on real-world data while shipping under a permissive Apache 2.0 license.
What Is YOLOv5?
YOLOv5 is a model in the You Only Look Once (YOLO) family of computer vision models. YOLOv5 is commonly used for detecting objects. YOLOv5 comes in four main versions: small (s), medium (m), large (l), and extra large (x), each offering progressively higher accuracy rates. Each variant also takes a different amount of time to train.
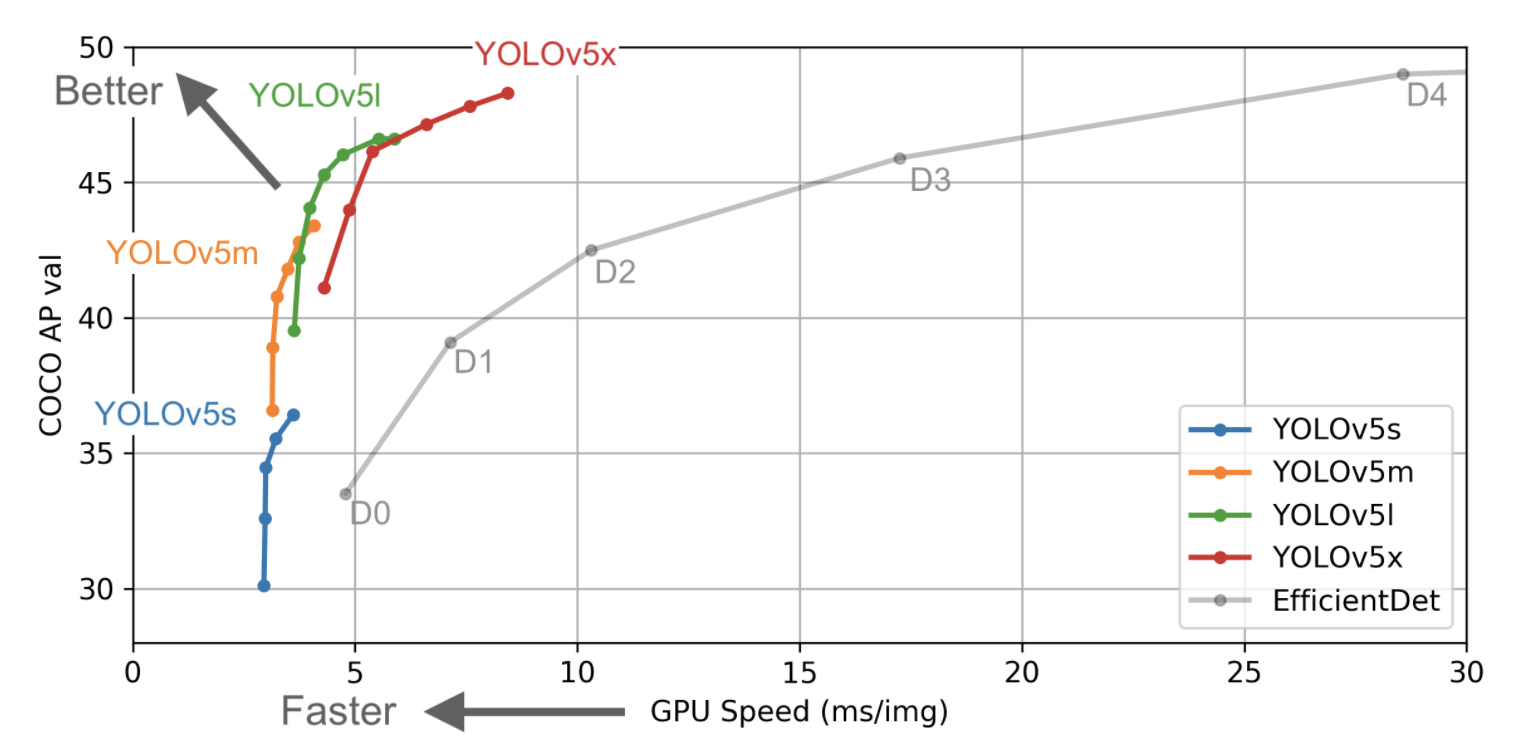
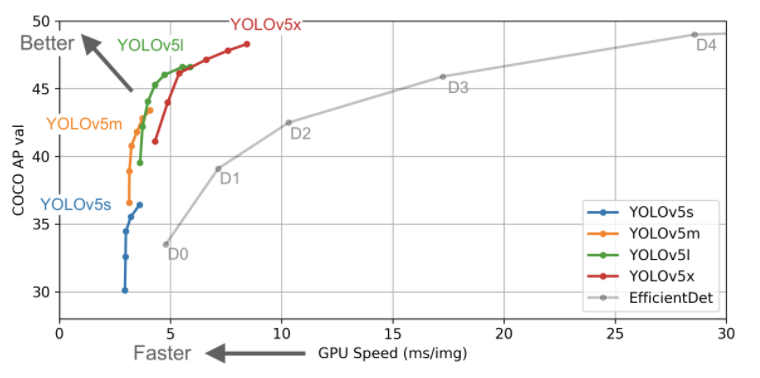
In the chart, the goal is to produce an object detector model that is very performant (Y-axis) relative to it's inference time (X-axis). Preliminary results show that YOLOv5 does exceedingly well to this end relative to other state of the art techniques.
In the chart above, you can see that all variants of YOLOv5 train faster than EfficientDet. The most accurate YOLOv5 model, YOLOv5x, can process images multiple times faster with a similar degree of accuracy than the EfficientDet D4 model. This data is discussed in more depth later in the post.
YOLOv5 derives most of its performance improvement from PyTorch training procedures, while the model architecture remains close to YOLOv4.
A short interview with the creator of YOLOv5. Subscribe to our YouTube channel for more.
Origin of YOLOv5: An Extension of YOLOv3 PyTorch
The YOLOv5 repository is a natural extension of the YOLOv3 PyTorch repository. That earlier repository was a popular destination for developers porting YOLOv3 Darknet weights to PyTorch to move toward production, and many teams liked the ease of use of the PyTorch branch for deployment.
After fully replicating the model architecture and training procedure of YOLOv3, research improvements were made alongside repository design changes with the goal of helping developers train and deploy their own custom object detectors. These advancements were briefly termed YOLOv4, then renamed YOLOv5 to avoid a version collision with the YOLOv4 release in the Darknet framework, which prompted debate around the YOLOv5 naming.
The following image shows some of the updates that were made:

Overview of the YOLOv5 Architecture
Object detection, a use case for which YOLOv5 is designed, involves creating features from input images. These features are then fed through a prediction system to draw boxes around objects and predict their classes.
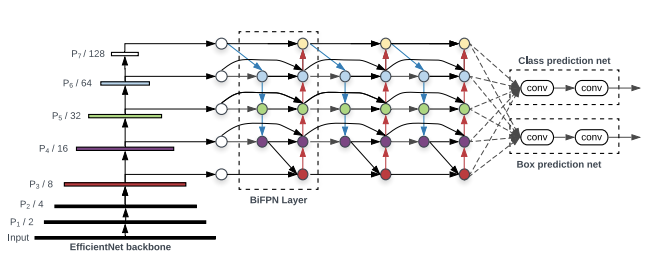
The YOLO model was the first object detector to connect the procedure of predicting bounding boxes with class labels in an end to end differentiable network.
The YOLO network consists of three main pieces.
- Backbone: A convolutional neural network that aggregates and forms image features at different granularities.
- Neck: A series of layers to mix and combine image features to pass them forward to prediction.
- Head: Consumes features from the neck and takes box and class prediction steps.
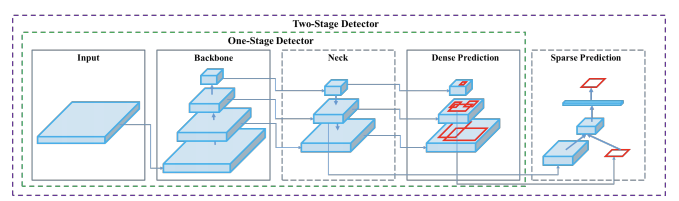
With that said, there are many approaches one can take to combining different architectures at each major component. The contributions of YOLOv4 and YOLOv5 are foremost to integrate breakthroughs in other areas of computer vision and prove that as a collection, they improve YOLO object detection.
An Overview of YOLO Training Procedures
The procedures taken to train a model are just as important as any factor to the end performance of an object detection system, although they are often less discussed. Let's talk about two main training procedures in YOLOv5:
- Data Augmentation: Data augmentation makes transformations to the base training data to expose the model to a wider range of semantic variation than the training set in isolation.
- Loss Calculations: YOLO calculates a total loss function from the GIoU, obj, and class losses functions. These functions can be carefully constructed to maximize the objective of mean average precision.
YOLOv5 for PyTorch

The largest contribution of YOLOv5 is to translate the Darknet research framework to the PyTorch framework. The Darknet framework is written primarily in C and offers fine grained control over the operations encoded into the network. In many ways the control of the lower level language is a boon to research, but it can make it slower to port in new research insights, as one writes custom gradient calculations with each new addition.
The process of translating (and exceeding) the training procedures in Darknet to PyTorch in YOLOv3 is no small feat.
Data Augmentation in YOLOv5
For each training batch, YOLOv5 passes data through a loader that augments it online with three kinds of transforms: scaling, color space adjustments, and mosaic augmentation.
The most novel is mosaic augmentation, which combines four images into four tiles of random ratio. Mosaic is especially useful on the COCO object detection benchmark, helping the model with the small object problem, where small objects are detected less accurately than larger ones.
It is worth experimenting with your own augmentations to maximize performance on your task.
Here is a picture of augmented training images in YOLOv5:
For a deep dive on how data augmentation has improved object detection models, I recommend reading this post on data augmentation in YOLOv4.
Auto Learning Bounding Box Anchors
In the YOLOv3 PyTorch repo, Glenn Jocher introduced the idea of learning anchor boxes based on the distribution of bounding boxes in the custom dataset with K-means and genetic learning algorithms. This is very important for custom tasks, because the distribution of bounding box sizes and locations may be dramatically different than the preset bounding box anchors in the COCO dataset.
In order to make box predictions, the YOLOv5 network predicts bounding boxes as deviations from a list of anchor box dimensions.
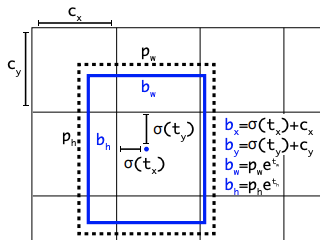
The most extreme difference in anchor boxes may occur if we are trying to detect something like giraffes that are very tall and skinny or manta rays that are very wide and flat. All YOLO anchor boxes are auto-learned in YOLOv5 when you input your custom data.
The following code illustrates an example of anchors that have been learned from training data in a YOLOv5 configuration file.
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [116,90, 156,198, 373,326] # P5/32
- [30,61, 62,45, 59,119] # P4/16
- [10,13, 16,30, 33,23] # P3/8
# YOLOv5 backboneThe anchors in the YOLOv5 config file are now auto learned based on training data.
16 Bit Floating Point Precision
The PyTorch framework allows the ability to half the floating point precision in training and inference from 32 bit to 16 bit precision. When used with YOLOv5, this significantly speeds up the inference time of models.
However, the speed improvements are only available on select GPUs at this point - namely, V100 and T4. That said, NVIDIA has written intent to improve their coverage of this efficiency boost.
New Model Configuration Files
YOLOv5 expresses model configuration in a .yaml file, rather than the .cfg files used in Darknet. The .yaml file is condensed to specify the layers in the network and then multiplies those by the number of layers in the block, which makes the architecture easier to read and adjust.
The new .yaml format looks like the following:
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [116,90, 156,198, 373,326] # P5/32
- [30,61, 62,45, 59,119] # P4/16
- [10,13, 16,30, 33,23] # P3/8
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
]
# YOLOv5 head
head:
[[-1, 3, BottleneckCSP, [1024, False]], # 9
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 18 (P3/8-small)
[-2, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 22 (P4/16-medium)
[-2, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 26 (P5/32-large)
[[], 1, Detect, [nc, anchors]], # Detect(P5, P4, P3)
]CSP Backbone
Both YOLOv4 and YOLOv5 implement the CSP Bottleneck to to formulate image features. Research credit for this architecture is directed to WongKinYiu and their recent paper on Cross Stage Partial Networks for convolutional neural network backbone.
The CSP addresses duplicate gradient problems in other larger ConvNet backbones resulting in less parameters and less FLOPS for comparable importance. This is extremely important to the YOLO family, where inference speed and small model size are of utmost importance.
The CSP models are based on DenseNet. DenseNet was designed to connect layers in convolutional neural networks with the following motivations:
- to alleviate the vanishing gradient problem (it is hard to backprop loss signals through a very deep network);
- to bolster feature propagation;
- to encourage the network to reuse features and;
- to reduce the number of network parameters.
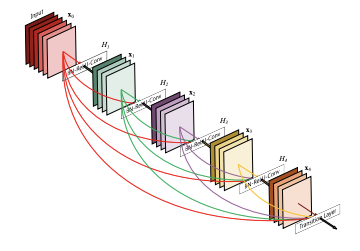
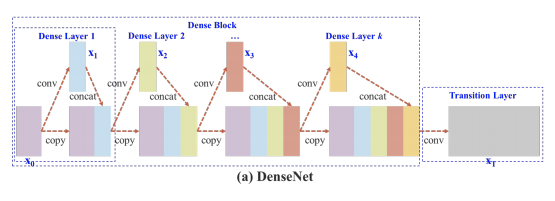
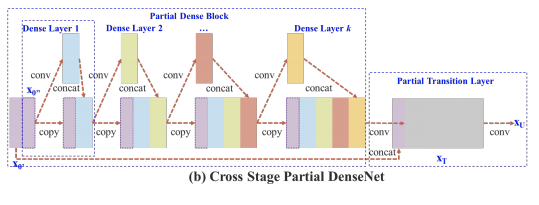
In CSPResNext50 and CSPDarknet53, the DenseNet has been edited to separate the feature map of the base layer by copying it and sending one copy through the dense block and sending another straight on to the next stage. The idea with the CSPResNext50 and CSPDarknet53 is to remove computational bottlenecks in the DenseNet and improve learning by passing on an unedited version of the feature map.
PA-Net Neck
Both YOLOv4 and YOLOv5 implement the PA-NET neck for feature aggregation.
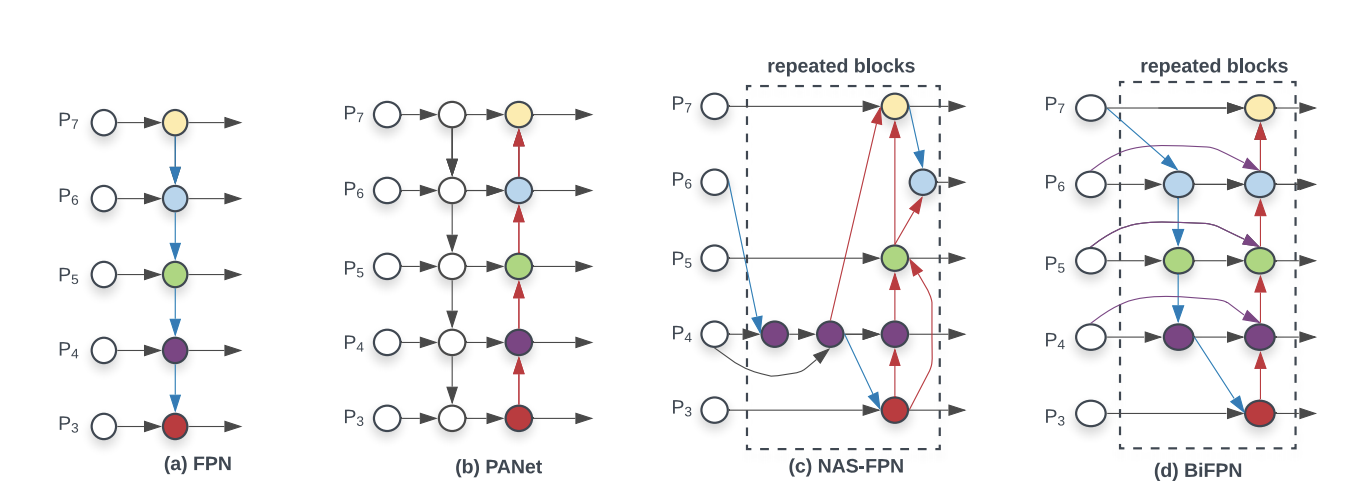
Each one of the P_i above represents a feature layer in the CSP backbone.
The above picture comes from research done by Google Brain on the EfficientDet object detection architecture. The EfficientDet authors found BiFPN to be the best choice for the detection neck, and it is may be an area of further steady for YOLOv4 and YOLOv5 to explore with other implementations here.
It is certainly worth noting here that YOLOv5 borrows research inquiry from YOLOv4 to decide on the best neck for their architecture. YOLOv4 investigated various possibilities for the best YOLO neck including:
- FPN
- PAN
- NAS-FPN
- BiFPN
- ASFF
- SFAM
Why Developers Reached for YOLOv5
Compared to other detection frameworks of its era, YOLOv5 was straightforward for a developer to pick up:
- Simple install: it requires torch and a few lightweight Python libraries.
- Fast training: the models train quickly, which cuts experimentation cost.
- Flexible inference: you can run on individual images, batches, video feeds, or a webcam.
- Clear file structure: the folder layout is easy to navigate while developing.
- Mobile export: you can convert PyTorch weights to ONNX, then to CoreML for iOS.
Preliminary YOLOv5 Evaluation Metrics
The evaluation metrics presented in this section are preliminary and we can expect a formal research paper to be published on YOLOv5 when the research work is complete and more novel contributions have been made to the family of YOLO models.
That said, it is useful to provide these metrics for a developer who is considering which framework to use today, before the research YOLOv5 papers have been published.
The evaluation metrics below are based on performance on the COCO dataset which contains a wide range of images containing 80 object classes. For more detail on the performance metric, see this post on what is mAP.
The official YOLOv4 paper publishes the following evaluation metrics running their trained network on the COCO dataset on a V100 GPU:
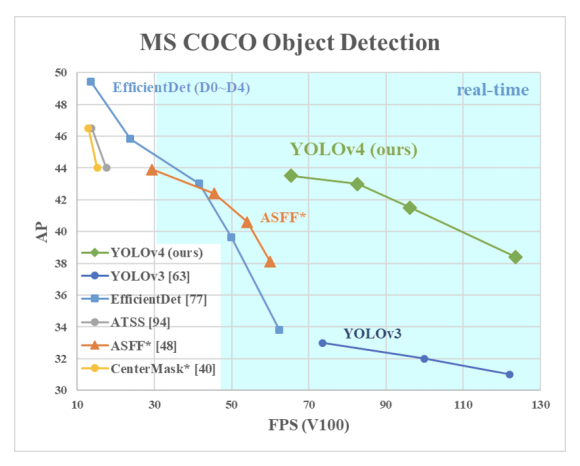
With the initial release of the first YOLOv5 V1 model, the YOLOv5 repository published the following:
These graphs invert the FPS x-axis vs ms/img, but we can quickly invert the YOLOv5 axis to estimate frame per numbers around 200-300FPS on the same V100 GPU, while achieving higher mAP.
It is also important to note here the new release of YOLOv4-tiny a very small and very performant model in the Darknet Repository.
The evaluation metrics for YOLOv4-tiny read:
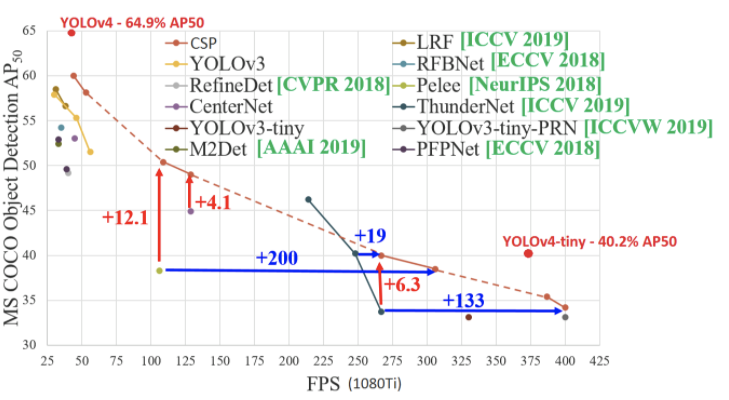
Which means it is very fast and very performant. But the important thing to notice here is that the evaluation metric is AP_50 - which means the average precision at 50% iOU. With this more lenient metric in mind, we must compare against the full table for YOLOv5:
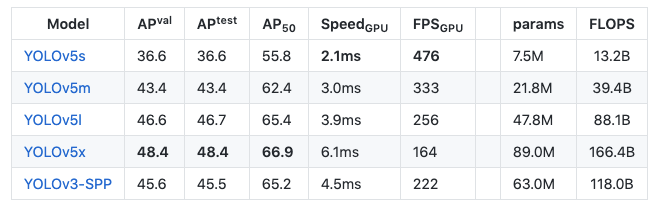
Where we can see that the YOLOv5s (a similar model in speed and model size) achieves 55.8 AP_50.
The comparison is a little more complicated here due to the fact that the YOLOv4-tiny model is evaluated on a 1080Ti which is maximum 2X slower than the V100 used in the YOLOv5 table.
Needless to say, there will be more narrowly matched benchmarks to come and some are underway in this GitHub issue. WongKinYiu, author of the CSP repo above and second author of YOLOv4, provides comparable benchmarks.
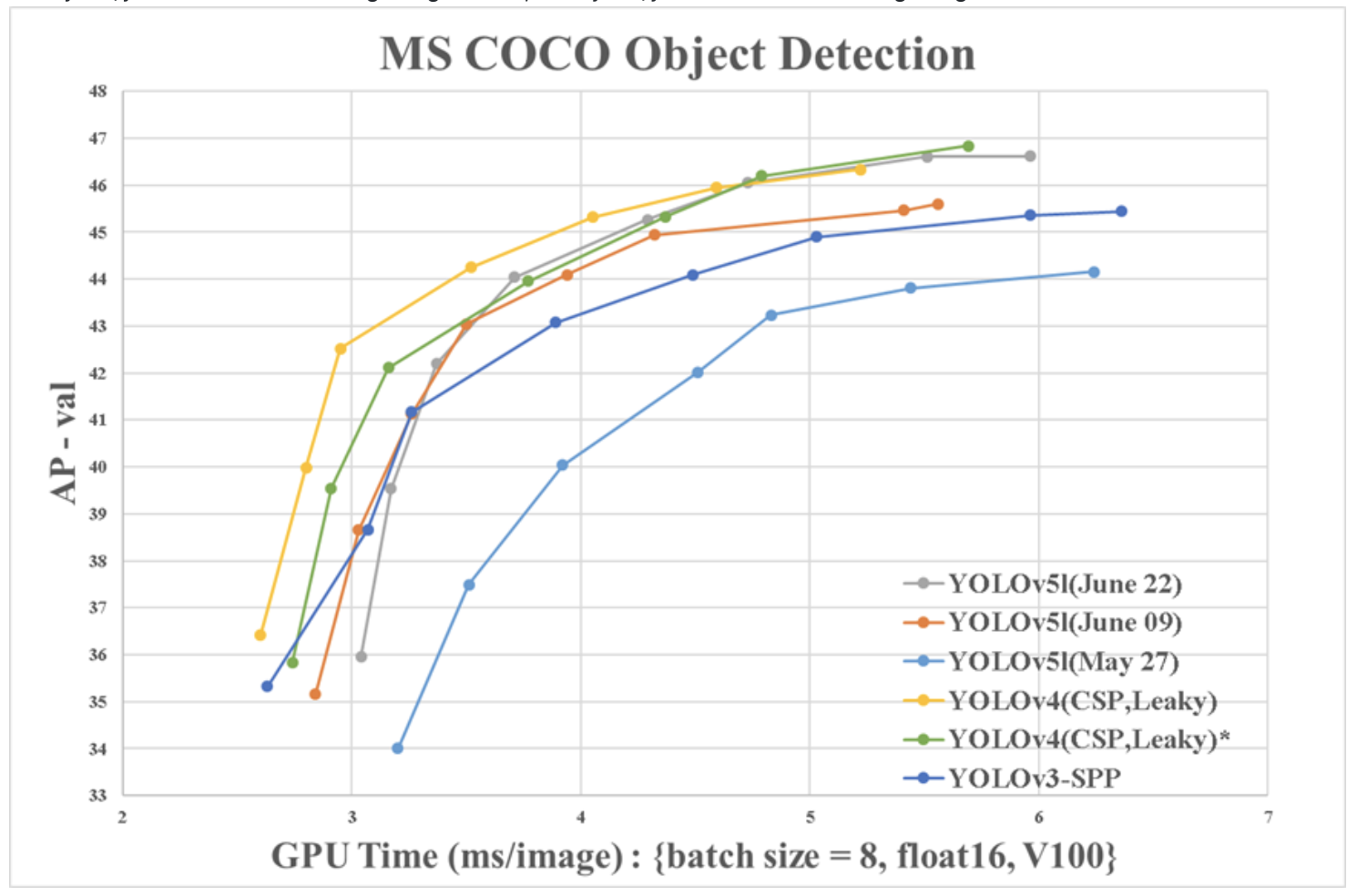
From this point of view, YOLOv4 emerges as the superior architecture.
YOLOv5 Labeling Format: YOLOv5 PyTorch TXT
The YOLOv5 PyTorch TXT annotation format is similar to YOLO Darknet TXT, with the addition of a YAML file containing model configuration and class values. Depending on the tool you label with, you may need to convert annotations to work with YOLOv5. Roboflow reads many labeling formats and can export them to YOLOv5 PyTorch TXT, so labels from other tools convert without manual work.
Deploy a YOLOv5 Model with Roboflow
Training YOLOv5 in Roboflow is deprecated for new projects, but YOLOv5 inference is still supported. You can upload your own trained YOLOv5 weights to a Roboflow project and serve them through the Serverless Hosted API for object detection or instance segmentation. Install the SDK:
pip install inference-sdk supervisionThen run your model on an image, passing your API key through an environment variable:
import os
import cv2
import supervision as sv
from inference_sdk import InferenceHTTPClient
client = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key=os.getenv("ROBOFLOW_API_KEY"),
)
# model_id is "project-name/version", e.g. "your-project/1"
result = client.infer("image.jpg", model_id="your-project/1")
image = cv2.imread("image.jpg")
detections = sv.Detections.from_inference(result)
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
annotated = box_annotator.annotate(scene=image.copy(), detections=detections)
annotated = label_annotator.annotate(scene=annotated, detections=detections)
cv2.imwrite("annotated.png", annotated)To run where your images are, Roboflow Inference is the open source engine that serves the same model on the cloud, on-prem, or at the edge on devices like the NVIDIA Jetson. Point the client at http://localhost:9001 for a local Inference server instead of the hosted URL. YOLOv5 is licensed under AGPL-3.0, so commercial use requires a license from its maintainers. For the current details, see the YOLOv5 deployment docs.
Where YOLOv5 Fits Today
YOLOv5's release moved object detection forward by translating the YOLO research lineage into a PyTorch training and deployment framework that was fast and easy to use. For a new project where you want to train a custom detector and take it to production, a transformer-based architecture is the stronger starting point today. RF-DETR fine-tunes quickly on a custom dataset, runs in real time, and ships under a permissive Apache 2.0 license, and you can follow the guide to training a custom RF-DETR model to build one on your own images.
What architecture does YOLOv5 use?
YOLOv5 uses a convolutional neural network backbone to form image features. Those features are combined in the neck and passed to the head, which predicts the class and bounding box for each object.
Is YOLOv5 a single-stage detector?
Yes. YOLOv5 predicts classes and bounding boxes directly in a single forward pass, without a separate region proposal stage.
Can I still train YOLOv5 in Roboflow?
Training YOLOv5 in Roboflow is deprecated for new projects. You can still upload your own trained YOLOv5 weights and run inference through the Serverless Hosted API, or self-host with Roboflow Inference. For a new custom detector, Roboflow trains RF-DETR, which reaches state-of-the-art accuracy and ships under a permissive license.
Related reading:
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz, Erik Kokalj. (Feb 1, 2026). What Is YOLOv5? Architecture, Sizes, and How It Works. Roboflow Blog: https://blog.roboflow.com/yolov5-improvements-and-evaluation/