
We appreciate the machine learning community's feedback, and we're publishing additional details on our methodology.
(Note: On June 14, we've incorporated updates from YOLOv4 author Alexey Bochkovskiy, YOLOv5 author Glenn Jocher, and others in the community.)
Don't care about the controversy?
Skip this post and jump straight to our YOLOv5 tutorial. You'll have a trained YOLOv5 model on your custom data in minutes.
On June 10th, the Roboflow Team published a blog post titled "YOLOv5 is Here," sharing benchmarks and comparisons on YOLOv5 versus YOLOv4. Our mission is to enable any developer to solve their problems with computer vision, so when Glenn Jocher (Ultralytics) released a YOLOv5 repository on June 9, we moved swiftly to share its creation more broadly.
The post generated significant discussion across Hacker News, Reddit, and even GitHub – but, frankly, not for the reasons we anticipated (like its small size and fast inference speeds).
Instead, the community identified two prominent issues:
- Should the model truly be named YOLOv5?
- Are the initial benchmarks Roboflow published accurate and reproducible?
This post shares our thoughts on these two questions and clarifies an unfair comparison in inference speed from our original post.
Naming YOLOv5
A number of commenters on our blog post took the position that Glenn Jocher should not have named the implementation "YOLOv5" because (1) he is not an original YOLO author, (2) he did not publish a paper, and/or (3) the implementation is not sufficiently novel.
Below, we provide context and a request to the machine learning community for better naming conventions.
A YOLO History
"YOLO" refers to "You Only Look Once," a family of models that Joseph Redmon introduced in his May 2016 paper, "You Only Look Once: Unified, Real-Time Object Detection."
Redmon subsequently introduced YOLOv2 in a December 2017 paper titled "YOLO9000: Better, Faster, Stronger." He and his advisor also published "YOLOv3: An Incremental Improvement" in April 2018.
In February 2020, Redmon announced he was stepping away from computer vision research.
From that point forward, it became unclear who, if anyone, should continue to use the name "YOLO" to refer to new model architectures. Some have considered YOLOv3 to be "the last YOLO."
Of chronological note, Glenn Jocher, unaffiliated with Joseph Redmon, created a popular YOLOv3 implementation in PyTorch.
Then, on April 23, 2020, Alexey Bochkovskiy published YOLOv4. Notably, Joseph Redmon engaged on Twitter to commend the amount of work Bochkovskiy has put into Darknet, and said it "doesn't matter what I think" about the implementation and its branding.
Doesn’t matter what I think! At this point @alexeyab84 has the canonical version of darknet and yolo, he’s put a ton of work into it and everyone uses it, not mine haha. https://t.co/FcnQPiySr7
— Joe Redmon (@pjreddie) April 25, 2020
The Origins of YOLOv5
On May 29, 2020, Glenn Jocher created a repository called YOLOv5 that didn't contain any model code, and on June 9, 2020, he added a commit message to his YOLOv3 implementation titled "YOLOv5 greetings."
Jocher's YOLOv5 implementation differs from prior releases in a few notable ways. First, Jocher did not (yet) publish a paper to accompany his release. Second, Jocher implemented YOLOv5 natively in PyTorch whereas all prior models in the YOLO family leverage Darknet.
Notably, Jocher is also credited with creating mosaic data augmentation and including it in his YOLOv3 repository, which is one of the many novel data augmentations leveraged in YOLOv4. He is given an acknowledgement in the YOLOv4 paper.

Jocher's YOLOv5 repository is far from his first involvement in the YOLO project: he's made 2,379 commits to his YOLOv3 implementation that Bochkovskiy cites.
Is YOLOv5 the Correct Name?
Candidly, the Roboflow team does not know. And nor should we be the arbiters of naming designations!
As I shared on Hacker News:
https://models.roboflow.com
any
However, we recognize that, as an organization amplifying recognition of model architectures, we should use the name that is consistent with what the machine learning community uses.
Thus, we will continue to listen and thoughtfully engage. We ask for the machine learning community to do the same. Let's appreciate the hard work that went into implementing YOLO in PyTorch natively, regardless of its name. And let's find the name that feels right – whether YOLOv5, FastYOLO, YOLOv4-accelerated, or something else altogether. It's safe to say: we look forward to the next YOLO. When (and if) the name changes, we will update our references to it.
Reproducing Roboflow's YOLOv4 Versus YOLOv5 Results
(Note: Glenn Jocher's YOLOv5 is under active development. The below comparisons are made as of June 14. Jocher has stated he plans to publish a YOLOv5 summary as a firmer checkpoint of performance later this year.)
Whenever a new model architecture is released, it is important to assess its performance to determine the model's quality. In the research community, models are benchmarked on the same images like the Common Object in Context (COCO) dataset. In production environments, teams will test models against their own domain problem, and they may consider different factors of primary importance. (For example, even if a model is more accurate, if it cannot perform realtime performance, it may be unsuitable for systems.)
As noted, at Roboflow, our goal is to enable teams to leverage computer vision models quickly and easily on their own custom datasets specific to their domains.
Similarly, our aim in comparing models is to give an example demonstration of using the two models on a user's own custom dataset. How long should they expect each implementation to train? How accurate are they? How fast is inference? How challenging is it to set up a given model in a production environment? Ideally, this comparison should be easily adapted to a user's own dataset so that they can make their own judgement call, too.
This is not a substitute for a formal benchmarking exercise on COCO. Bochkovskiy made this abundantly clear in his breakdown of YOLOv4 versus YOLOv5 on GitHub, and identified an inconsistency in how we at Roboflow compared the frame rates and default model sizes, which we've addressed more thoroughly below.
We deeply respect the work researchers like Alexey Bochkovskiy are producing, and we're thankful they are continuing to push the field forward. In fact, we are building Roboflow for very similar reasons to why he published the YOLOv4 paper:
We hope that the designed object can be easily trained and used.
(added emphasis ours)
How Roboflow Compared YOLOv4 and YOLOv5
We implemented the default models that compile when using the Darknet repository and Ultralytics's YOLOv5 repository. As Bochkovskiy noted, this compiles the YOLOv4s ("big YOLOv4" and YOLOv5s "small YOLOv4").
After the post came out and we saw some of the (valid) criticisms, we solicited advice from those in the community on the best way to back up and clarify the results we published.
Thus, the rest of our post below includes the following:
- Comparing YOLOv4 and YOLOv5 Installations
- Comparing YOLOv4 and YOLOv5 Data Set Up
- Comparing YOLOv4 and YOLOv5 Training Configurations
- Comparing YOLOv4 and YOLOv5 Training Time
- Comparing YOLOv4 and YOLOv5 Evaluation
- Comparing YOLOv4 and YOLOv5 Inference Time
- Comparing YOLOv4 and YOLOv5 Model Storage Size
Before diving in, it's important to acknowledge that both of these frameworks accomplish the impressive feat of enabling computers to recognize objects, and many considerations raised here are on the margins.
The 30,000-Foot Benchmark Summary
Both models appear to max out their performance on our sample dataset, hence reported similarly accurate performance. YOLOv5 trains faster on the sample task, and the batch inference (which the implementation uses by default) produces realtime results. While YOLOv4 trains more slowly, its performance can be optimized to achieve higher FPS. Because the YOLOv5 implementation is in PyTorch and YOLOv4 is in Darknet, YOLOv5 may be easier to bring to production while YOLOv4 is where top-accuracy research may continue to progress.
So what does that mean in practical terms for you, as a user?
If you're a developer looking to incorporate near realtime object detection into your project quickly, YOLOv5 is a great choice. If you're a computer vision engineer in pursuit of state-of-the-art and not afraid of a little more custom configuration, YOLOv4 in Darknet continues to be most accurate.
Importantly, we've made it easy for you to try this experiment on your own dataset:
The remainder of this writeup is written to guide you through completing this comparison on your own dataset.
Comparison Backdrop
All comparisons are conducted in Google Colab which, on the Pro tier, comes with consistent hardware: a NVIDIA Tesla P100. This also enables you to easily reproduce our results. (It does come at the cost of not enabling lower level optimizations with, e.g. specific CUDA Toolkit versioning.)
If you'd like to use the exact same notebooks we used in our tests to teproduce these results, they're available here:
About the Data
In our evaluation, we used the blood cell count and detection dataset. The dataset consists of 364 images across three classes (red blood cells, white blood cells, and platelets).
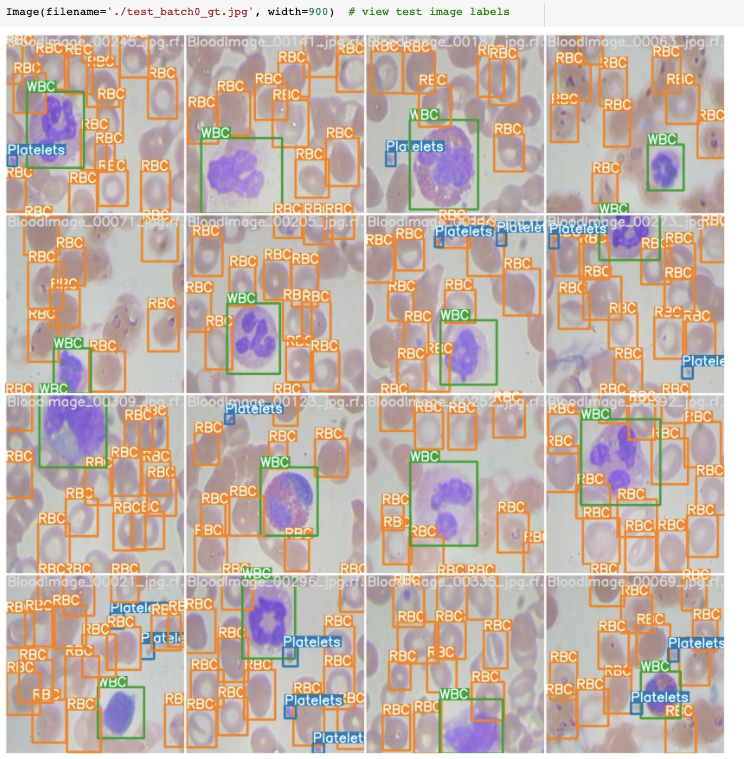
As noted, our dataset is meant to be representative of a sample custom task that may be encountered "in the wild," and not an official COCO benchmark. The notebooks linked above enable you to duplicate this experiment on your own task.
Comparing YOLOv4 and YOLOv5 installations
Before we get started training, we first install the YOLOv4 Darknet and YOLOv5 environments. Setting up environments (beyond supplying requirements.txt and occasional AMIs) is often omitted from even rigorous COCO comparisons, and we find it to be an important point comparison if a primary goal is accessibility.
YOLOv4 Darknet Environment
We first check our cuda toolkit in Google Colab to interface with the GPU.
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Sun_Jul_28_19:07:16_PDT_2019
Cuda compilation tools, release 10.1, V10.1.243Then we need to install cuDNN to support deep learning functions utilized by Darknet. To do so, we navigate to NVIDIA's website and pull the correct cuDNN file to configure with our cuda drivers. In this case, that is cuDNN 10.1. We read in and install. Unfortunately, NVIDIA does not allow publishing of the cuDNN link, so if you're following along, you'll need to to go to NVIDIA's website to download.
/usr/local
cuda/include/cudnn.h
cuda/NVIDIA_SLA_cuDNN_Support.txt
cuda/lib64/libcudnn.so
cuda/lib64/libcudnn.so.7
cuda/lib64/libcudnn.so.7.6.5
cuda/lib64/libcudnn_static.a
#define CUDNN_MAJOR 7
#define CUDNN_MINOR 6
#define CUDNN_PATCHLEVEL 5
--
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
#include "driver_types.h"Then we double check our GPU provision from Google Colab:
!nvidia-smi
NVIDIA-SMI 440.82 Driver Version: 418.67 CUDA Version: 10.1
0 Tesla P100-PCIE... OffConfiguring the Makefile. Before reaching google Colab, we configured the Makefile to have the following configurations:
GPU=1
CUDNN=1
CUDNN_HALF=0
OPENCV=1Then, after cloning the repo we !make and Darknet has been set up!
When we kick off training, we will see the following print outs:
CUDA-version: 10010 (10010), cuDNN: 7.6.5, GPU count: 1
OpenCV version: 3.2.0
YOLOv5 Ultralytics Environment
The YOLOv5 Ultralytics Environment is much more straightforward to set up in Google Colab.
We first clone the repository, !pip install -U -r yolov5/requirements.txt and then check our torch set up:
torch 1.5.0+cu101 _CudaDeviceProperties(name='Tesla P100-PCIE-16GB', major=6, minor=0, total_memory=16280MB, multi_processor_count=56)This is an ode to the ease of PyTorch.
Comparing YOLOv4 and YOLOv5 Data Set Up
YOLOv4 uses the traditional data annotations in YOLO Darknet framework. A train.txt and valid.txt specify a location of .jpg files with .txt annotations. Finally, a .data file is invoked in training to specify the location of all of these things along with class labels and a place to save training weights:
with open('data/obj.data', 'w') as out:
out.write('classes = 3\n')
out.write('train = data/train.txt\n')
out.write('valid = data/valid.txt\n')
out.write('names = data/obj.names\n')
out.write('backup = backup/')YOLOv5 uses a similar format with a few caveats. train and valid folders are to be placed next to the yolov5 repository. In each, should be an images directory of images with an accompanying labels directory. A data.yml file links these directories together:
train: ../train/images
val: ../valid/images
nc: 3
names: ['Platelets', 'RBC', 'WBC']
Both formats are supported by Roboflow for Download and you can drag and drop Upload your dataset in any format (COCO, Pascal VOC, TensorFlow CSV, etc.) and get them back formatted properly for YOLOv4 or YOLOv5.
Comparing YOLOv4 and YOLOv5 Training Configurations
YOLOv4 and YOLOv5 both specify training configuration files, .cfg and .yaml, respectively. Both of these training files require us to specify num_classes for your custom dataset, as the networks architectures are rewritten.
In the Darknet config, we specify more about the training job including batch_size, subdivisions, max_batches, and steps. In Darknet, you can play around with these parameters to speed up your training time by maxing out memory on your GPU.
Here's a peek at YOLO layers in each of the configuration files:
[yolo]
mask = 6,7,8
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=3
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
scale_x_y = 1.05
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=5
# yolov5 head
head:
[[-1, 3, BottleneckCSP, [1024, False]], # 11
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 12 (P5/32-large)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 17 (P4/16-medium)
[-2, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, Conv, [256, 1, 1]],
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 22 (P3/8-small)
[[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]Both of these configuration files allow for flexible shifting of model experiments at the architecture level. YOLOv4 Darknet provides more flexibility and therefore is probably a better spot to go to for research purposes.
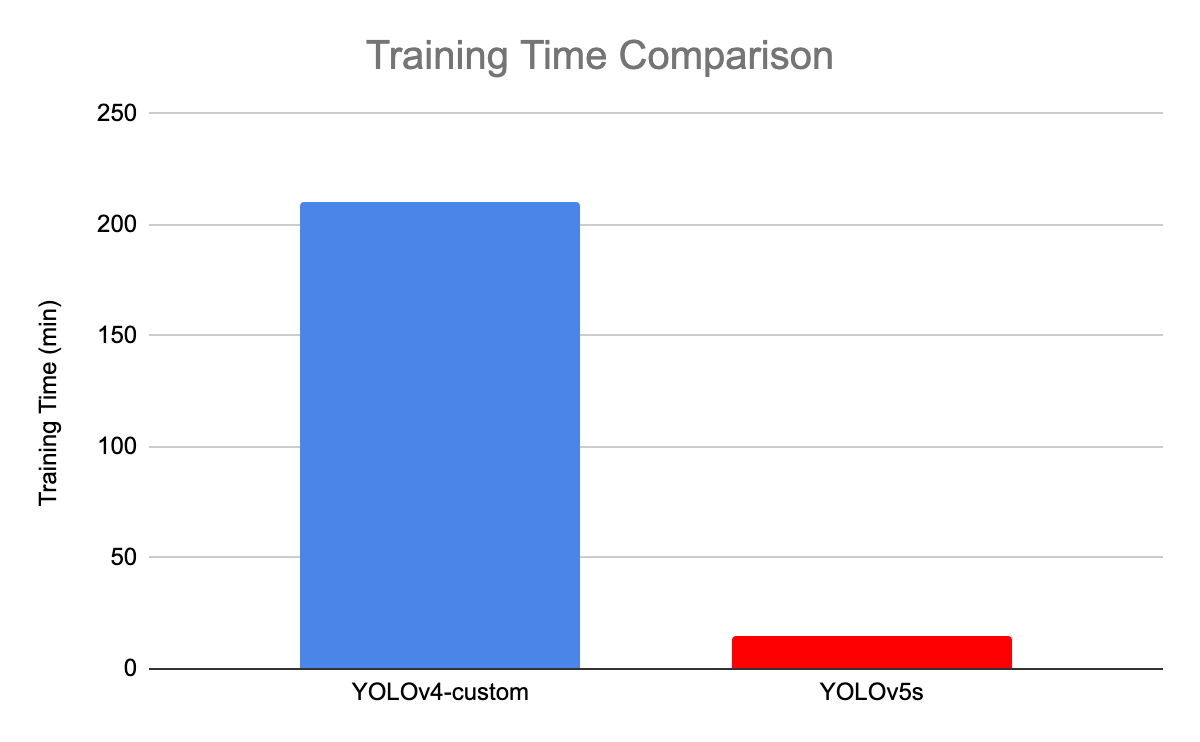
Comparing YOLOv4 and YOLOv5 Training Time
In YOLOv4 Darknet, you set training length based on number of iterations max_batches (not epochs). The recommendation in the repository for custom objects is 2000 x num_classes. With this setting YOLOv4 Darknet takes a whopping 14hrs on our example dataset. However, it reaches max validation eval well before that; we saw max validation evaluation at 1300 iterations, which took about 3.5 hrs to reach.
YOLOv5s, on the other hand, took 14.46 minutes to train on 200 epochs.
Comparing YOLOv4 vs YOLOv5 Evaluation
For both networks, we look at the max validation mAP @0.5. We find that they perform similarly in this metric (0.91 mAP) for our task.
This does not reflect the networks' performance on the COCO dataset. The reality is that both networks are probably approaching maximum performance for this particular custom task, based on this particular custom dataset.
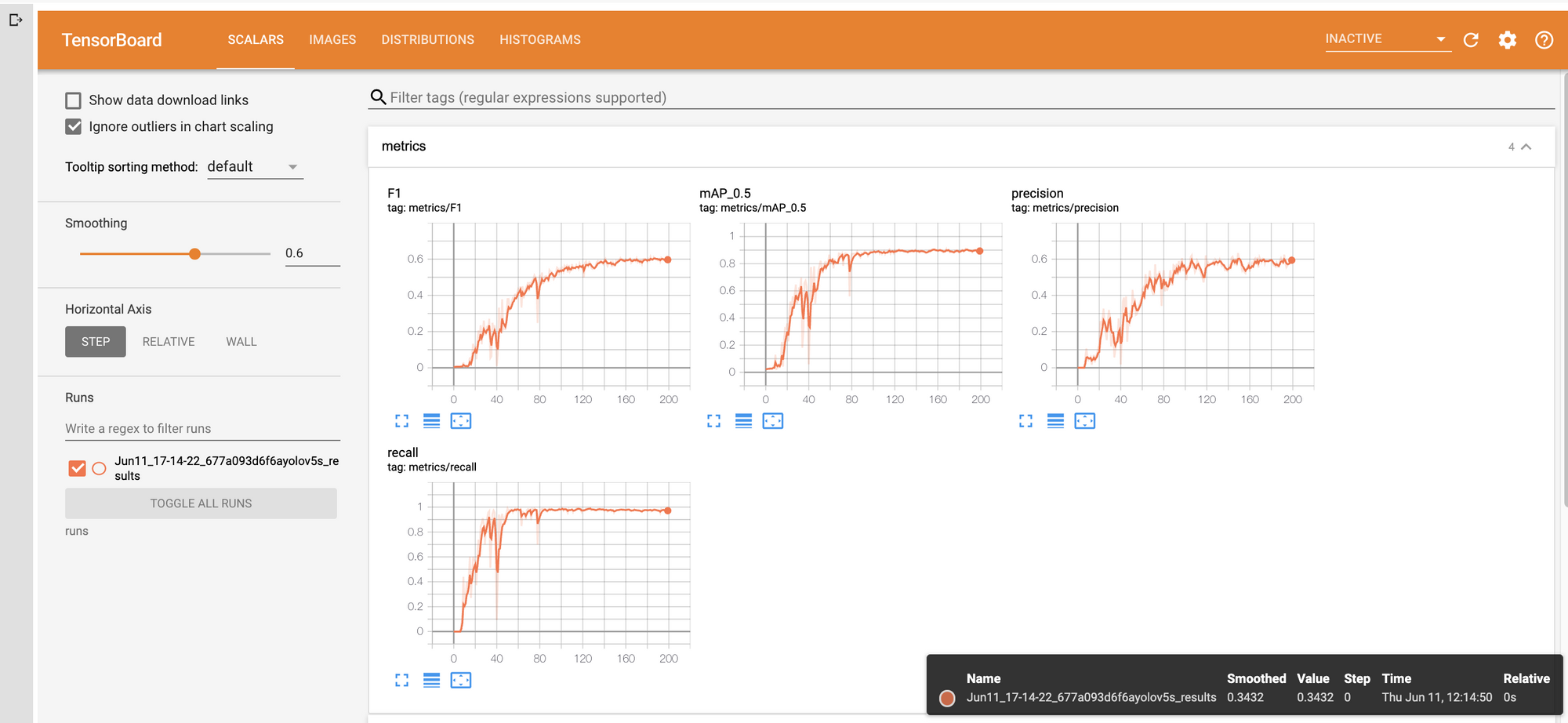
When running Darknet on local you can produce a nice training graph, but on Colab that is not as easy to achieve. You can output the logs and then parse them, but we did not go so far here.
calculation mAP (mean average precision)...
76
detections_count = 4265, unique_truth_count = 967
class_id = 0, name = Platelets, ap = 88.87% (TP = 73, FP = 30)
class_id = 1, name = RBC, ap = 85.28% (TP = 763, FP = 635)
class_id = 2, name = WBC, ap = 98.03% (TP = 72, FP = 2)
for conf_thresh = 0.25, precision = 0.58, recall = 0.94, F1-score = 0.71
for conf_thresh = 0.25, TP = 908, FP = 667, FN = 59, average IoU = 47.79 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.907268, or 90.73 %
Total Detection Time: 3 Seconds
Set -points flag:
`-points 101` for MS COCO
`-points 11` for PascalVOC 2007 (uncomment `difficult` in voc.data)
`-points 0` (AUC) for ImageNet, PascalVOC 2010-2012, your custom dataset
mean_average_precision (mAP@0.5) = 0.907268 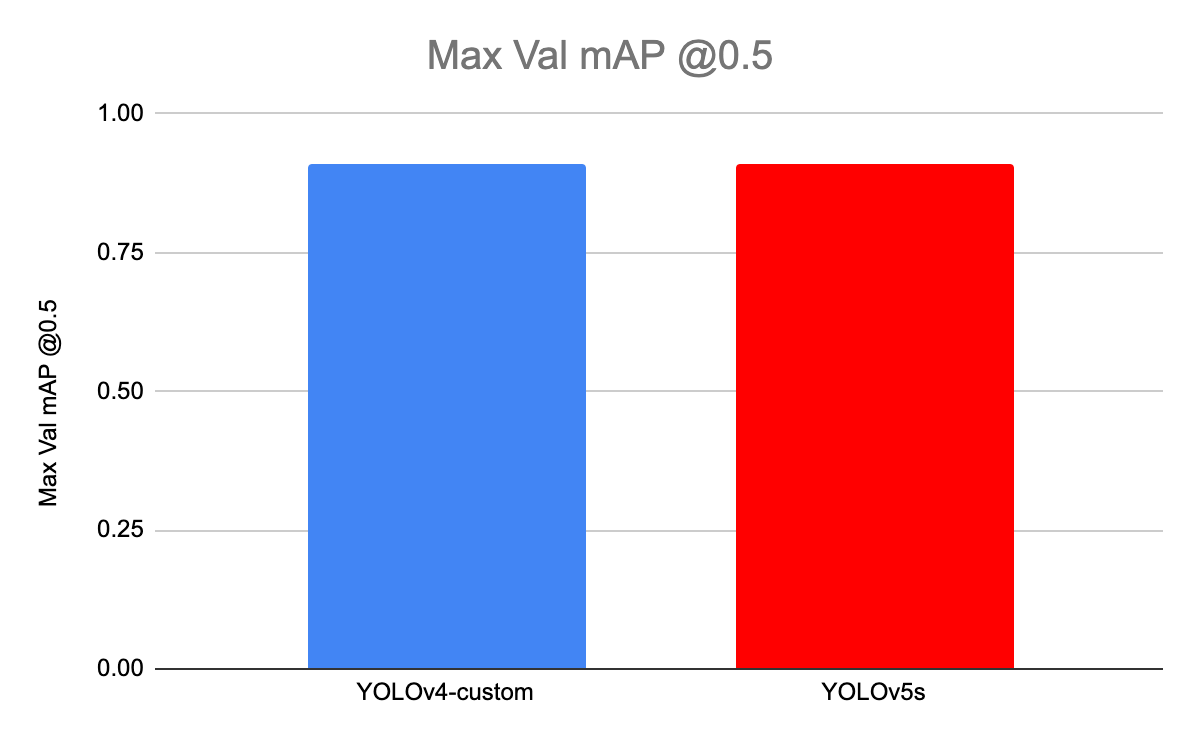
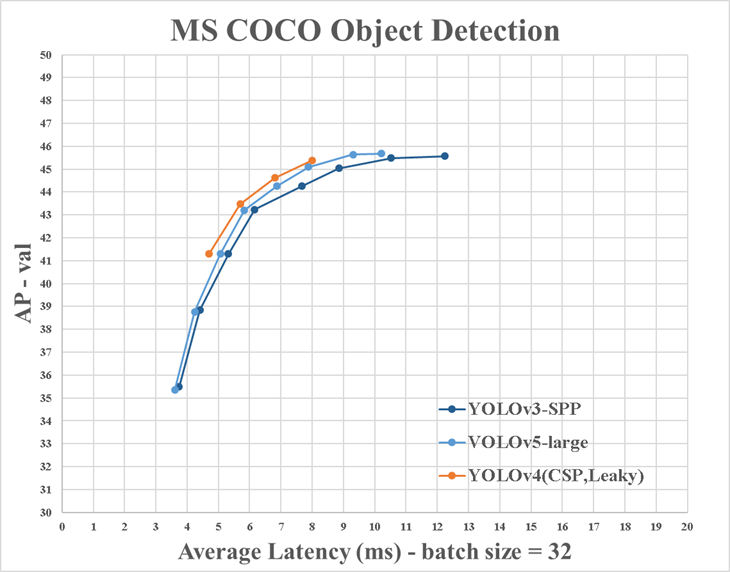
Bochkovskiy alluded to how we might expect these two models to perform on Microsoft COCO as well:
They compared size of models of small ultralytics-YOLOv5-version YOLOv5s (27 MB) with very low accuracy 26-36% AP on Microsoft COCO with big YOLOv4 (245 MB) with very high accuracy 41-43% AP on Microsoft COCO.
(Update: Alexey provided a full evaluation of YOLOv3, YOLOv4, and YOLOv5 demonstrating YOLOv4's superiority on the COCO benchmark relative to latency.)
Comparing YOLOv4 and YOLOv5s Model Storage Size
When we look at the weight files file sizes here is what we observed. .weights is the custom YOLOv4 detector from the Darknet repository and .pt is the custom YOLOv5s detector from the Ultralytics repository. YOLOv4 has a 250 mb weight file and YOLOv5s has a 27 mb weight file.
250060 backup/custom-yolov4-detector_best.weights
27076 weights/last_yolov5s_results.pt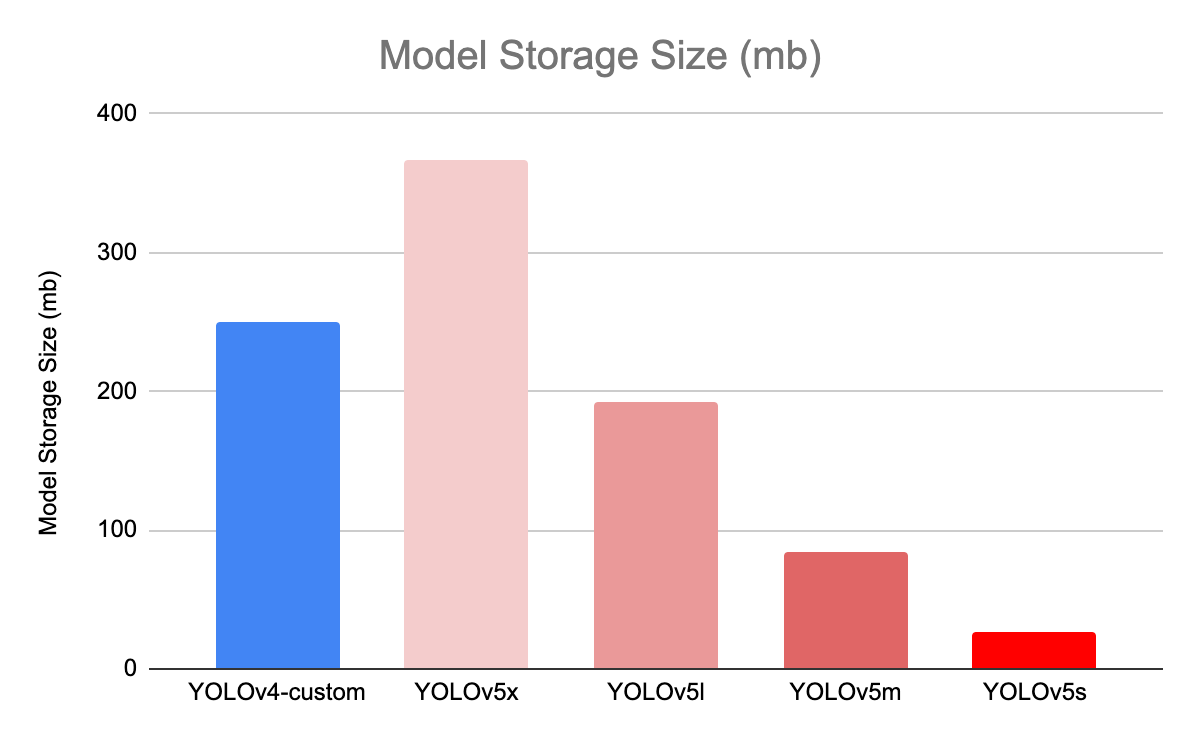
Of note: Bochkovskiy highlighted that the default YOLOv4 architecture from his Darknet repository builds big YOLOv4 (245 MB) while the YOLOv5 implementation builds a small YOLOv5 (YOLOv5s). The largest YOLOv5 is YOLOv5x, and its weights are 367 MB.
Comparing YOLOV4 and YOLOv5s Inference Time
Lastly, we compare inference time run under both networks with the environment configurations specified (Tesla P100). This is where AlexeyAB rightly pointed out that our original post made an unfair comparison and did not compare apples to apples. We apologize for this; our intention was not to mislead and we did not realize the default inference settings were different until AlexeyAB pointed it out.
On single images (batch size of 1), YOLOv4 inferences in 22 ms and YOLOv5s inferences in 20ms. (Update June 14 12:46 PM CDT - In response to rcg12387's GitHub comment, we have corrected an error where we previously calculated YOLOv5 inference to be 10 FPS. We regret this error.)
YOLOv5s inferences in 7 ms (140 FPS) when you infer in batch. The output divides total inference time by the number of images being processed. The Ultralytics YOLOv5 implementation defaults to this setting, so if you implement from the repository, you will have batch inference at 140 FPS by default.
We were not able to figure out how to get YOLOv4 to do batch inference in our notebook. If you figure out how to do it, please let us know and we will update this post.
../test/images/BloodImage_00337_jpg.rf.7959cb18929c970939cda4a9544547c8.jpg: 416x416 21 RBCs, 1 WBCs, Done. (0.019s)
test/BloodImage_00062_jpg.rf.e965ee152eea462d82706a2709abfe00.jpg: Predicted in 21.587000 milli-seconds.
image 1/36 ../test/images/BloodImage_00038_jpg.rf.63da20f3f5538d0d2be8c4633c7034a1.jpg: 416x416 1 Plateletss, 22 RBCs, 1 WBCs, Done. (0.007s)
image 2/36 ../test/images/BloodImage_00044_jpg.rf.b0e2369642c5a7fa434ed8defa79e2ba.jpg: 416x416 2 Plateletss, 13 RBCs, 2 WBCs, Done. (0.007s)
image 3/36 ../test/images/BloodImage_00062_jpg.rf.e965ee152eea462d82706a2709abfe00.jpg: 416x416 1 Plateletss, 14 RBCs, 1 WBCs, Done. (0.007s)
image 4/36 ../test/images/BloodImage_00090_jpg.rf.4fd1da847d2857b6092003c41255ea4c.jpg: 416x416 3 Plateletss, 12 RBCs, 1 WBCs, Done. (0.007s)
image 5/36 ../test/images/BloodImage_00099_jpg.rf.5b178d758af2a97d3df8e5f87b1f344a.jpg: 416x416 1 Plateletss, 16 RBCs, 1 WBCs, Done. (0.007s)
image 6/36 ../test/images/BloodImage_00112_jpg.rf.f8d86689750221da637a054843c72822.jpg: 416x416 1 Plateletss, 15 RBCs, 1 WBCs, Done. (0.007s)
image 7/36 ../test/images/BloodImage_00113_jpg.rf.a6d6a75c0ebfc703ecff95e2938be34d.jpg: 416x416 1 Plateletss, 15 RBCs, 1 WBCs, Done. (0.007s)
image 8/36 ../test/images/BloodImage_00120_jpg.rf.6742a4da047e1226a181d2de2978ce6d.jpg: 416x416 9 RBCs, 1 WBCs, Done. (0.007s)
image 9/36 ../test/images/BloodImage_00133_jpg.rf.06c3705fcfe2fcaee19e1a076e511508.jpg: 416x416 8 RBCs, 1 WBCs, Done. (0.007s)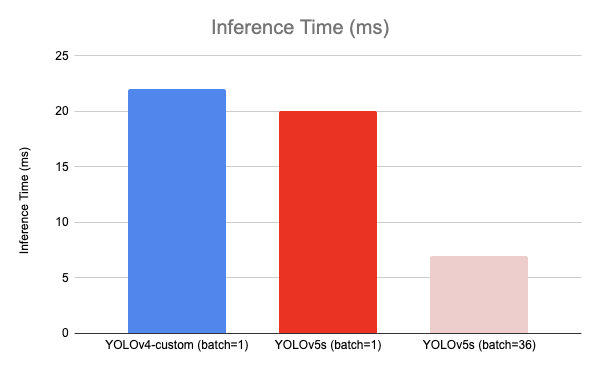
(Update: Glenn Jocher published additional results and clarifications to expected inference times from YOLOv5. We've included his commentary below.)
The times ... are not for batched inference, they are for batch-size = 1 inference. This is the reason they are printed to the screen one at a time, because they are run in a for loop, with each image passed to the model by itself (tensor size 1x3x416x416). I know this because like many other things, we simply have not had time to modify detect.py properly for batched inference of images from a folder.
One disclaimer is that the above times are for inference only, not NMS. NMS will typically add 1-2ms per image to the times. So I would say 8-9ms is the proper batch-size 1 end-to-end latency in your experiment, while 7 ms is the proper batch-size 1 inference-only latency.
In response to this I've pushed a commit to improve detect.py time reporting. Times are now reported as full end-to-end latencies: FP32 pytorch inference + posprocessing + NMS. I tested out the new times on a 416x416 test image, and I see 8 ms now at batch-size 1 for full end-to-end latency of YOLOv5s.
As Glenn Jocher is continuing to improve YOLOv5 and stated plans to publish a paper this year, the current best place to continue to assess model mAP versus latency on the COCO benchmark is this ongoing GitHub Issue.
Summary
Roboflow is committed to enabling every developer to use computer vision to solve their problems, regardless of their domain. We've seen thousands build tools like COVID-19 chest scan interpreters, sushi detectors, airplane part maintenance identifiers, and so much more.
We will continue to monitor what model name appears most appropriate for Glenn Jocher's YOLOv5 implementation, and we hope our detailed YOLOv4 vs YOLOv5 methodology enables validation of how we achieved our results. We also hope it highlights "ease of use" as a consideration when creating comparisons.
Sincerely, we're deeply appreciative of the feedback along the way. As a machine learning researcher wrote us:
It sounds like you care, and that's the point.
Lastly, we invite you to try YOLOv4 and YOLOv5 (or whatever our community decides to call it!) on your own datasets and draw your own conclusions:
Special thanks to Shawn Presser.
Cite this Post
Use the following entry to cite this post in your research:
Joseph Nelson, Jacob Solawetz. (Jun 12, 2020). Responding to the Controversy about YOLOv5. Roboflow Blog: https://blog.roboflow.com/yolov4-versus-yolov5/