
YOLOv4's gains over YOLOv3 (10% higher mAP and 12% faster FPS on COCO) came primarily from a set of training-time data augmentation techniques the authors called the Bag of Freebies. This post breaks down each technique, including geometric distortions, image occlusion methods like Cutout and CutMix, and Mosaic Augmentation, which combines four images into a single training sample to expose the model to varied scales and contexts. Because these methods only affect the training pipeline and not inference, they can improve accuracy without any latency cost.
The "secret" to YOLOv4 isn't architecture: it's in data preparation.
The object detection space continues to move quickly. No more than two months ago, the Google Brain team released EfficientDet for object detection, challenging YOLOv3 as the premier model for (near) realtime object detection, and pushing the boundaries of what is possible in object detection models.
We wrote a series of posts comparing YOLOv3 and EfficientDet, training YOLOv3 on custom data, and training EfficientDet on custom data, and we've found impressive results.
We recommend using the Roboflow model library to easily adapt these models from the COCO dataset to your narrow domain.
See here for our other YOLOv4 tutorials on how to train YOLOv4 on your custom dataset, YOLOv4 PyTorch, and our YOLOv4 Architecture deep dive.
And now YOLOv4 has been released showing an increase in COCO mean average precision (mAP) and Frames Per Second (FPS) by 10 percent and 12 percent, respectively.
In this post, we will see how the authors made this breakthrough by diving into the specifics of the data augmentation techniques used in YOLOv4.
YOLOv5 has been released
The founder of Mosaic Augmentation, Glenn Jocher has released a new YOLO training framework titled YOLOv5. You may also want to see our post on YOLOv5 vs YOLOv4. This post will explain some of the pros of the new YOLOv5 framework.

The importance of data augmentation for computer vision is not new. See our post from January explaining how important image preprocessing and augmentation is for computer vision.
What is the Bag of Freebies in YOLOv4?
The authors of YOLOv4 include a series of contributions in their paper titled a "bag of freebies." These are a series of steps that can be taken to improve the model's performance without increasing latency at inference time.
Because they cannot affect the model's inference time, most of these make improvements in the data management and data augmentation of the training pipeline. These techniques improve and scale up the training set to expose the model to scenarios that would have otherwise been unseen.
Data augmentation in computer vision is key to getting the most out of your dataset, and state of the art research continues to validate this assumption.
Data Augmentation in Computer Vision
Image augmentation creates new training examples out of existing training data. It’s impossible to truly capture an image for every real-world scenario our model may be tasked to see in inference. Thus, adjusting existing training data to generalize to other situations allows the model to learn from a wider array of situations.
The authors of YOLOv4 cite a number of techniques that ultimately inspired the inclusion of their bag of freebies. We provide an overview below.
Distortion as a Computer Vision Augmentation Method
Photometric Distortion - This includes changing the brightness, contrast, saturation, and noise in an image. (For example, written on blur data augmentation in computer vision.)
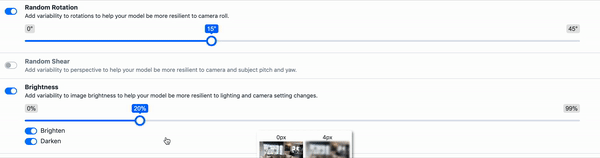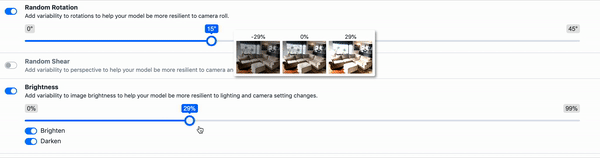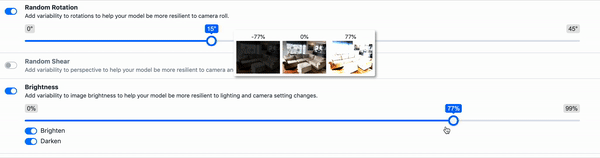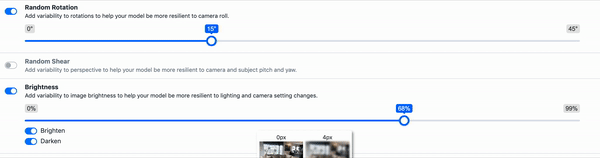
Geometric Distortion - This includes random scaling, cropping, flipping, and rotating. These types of augmentation can be particularly tricky as the bounding boxes are also affected and must be updated. (As an example, we've written on how to use random cropping data augmentation in computer vision.)
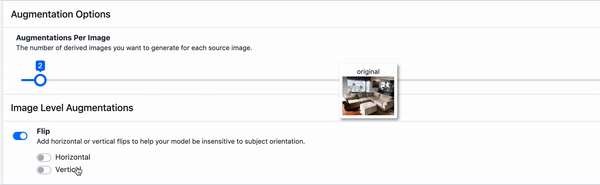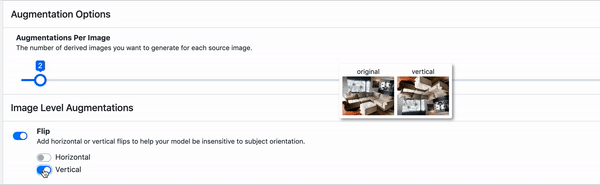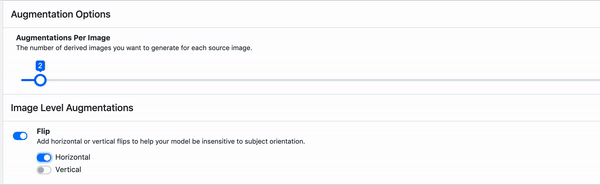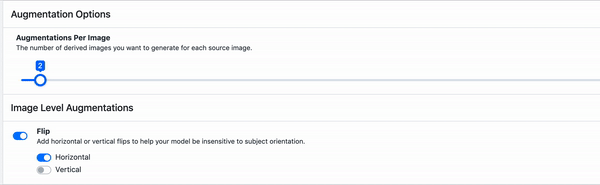
Those two methods were both pixel adjustments, meaning that the original image could easily be recovered with a series of transformations.
Image Occlusion as a Computer Vision Augmentation Method
Random Erase - This is a data augmentation technique that replaces regions of the image with random values, or the mean pixel value of training set.
Typically, it is implemented with varying proportion of image erased and aspect ratio of erased area. Functionally, this becomes a regularization technique, which prevents our model from memorizing the training data and overfitting.

Cutout - square regions are masked during training. Cutout regions are only hidden from the first layer of the CNN. This is very similar to random erase, but with a constant value in the overlaid occlusion. The purpose is similar: we reduce overfitting.

Hide and Seek - Divide the image into a grid of SxS patches. Hide each patch with some probability (p_hide). This allows the model to learn what an object looks like without learning only what a single portion of the object looks like.
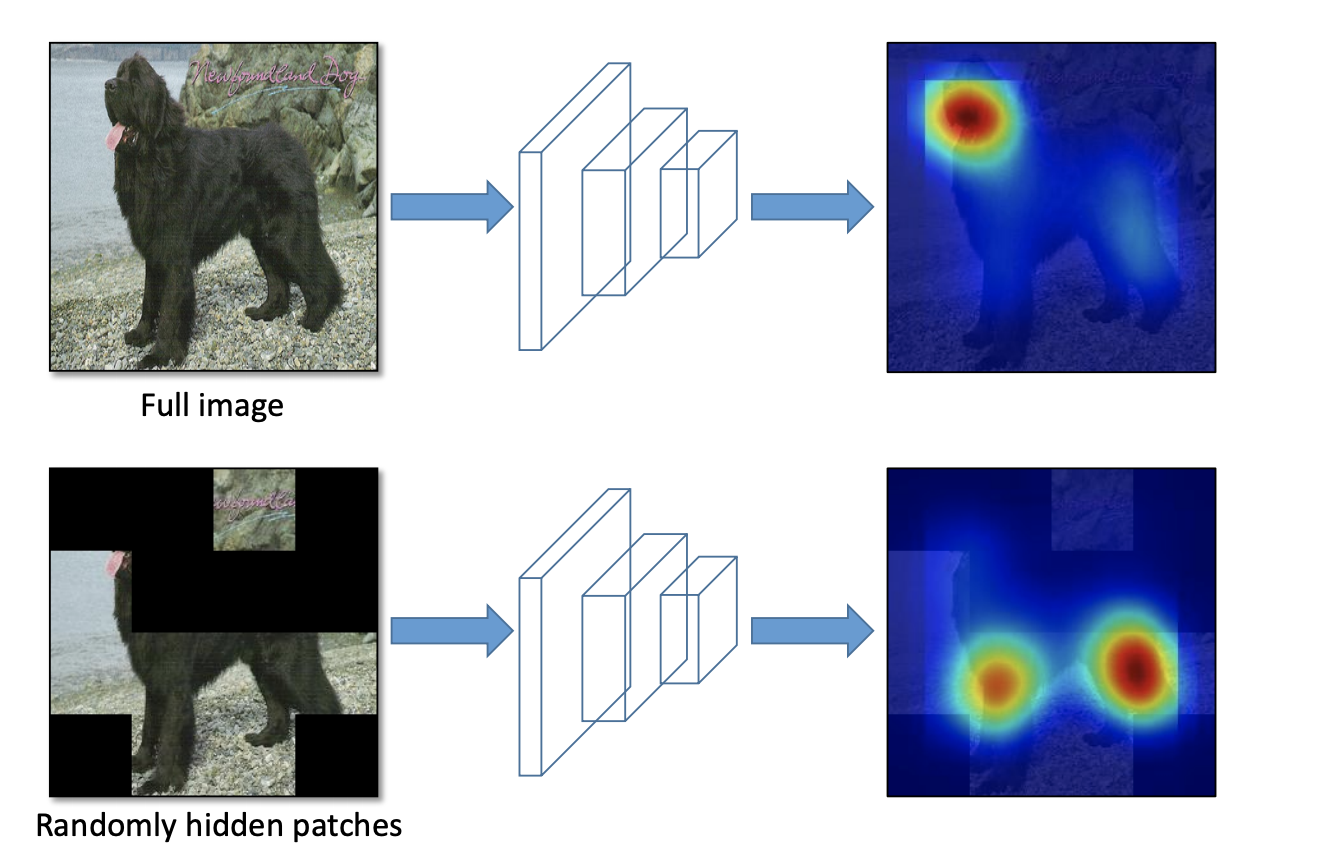
Grid Mask - Regions of the image are hidden in a grid like fashion. Similar to hide and seek, this forces our model to learn component parts of what makes up an individual object.

MixUp - convex overlaying of image pairs and their labels. (Paper here)

Data Augmentation Strategies Deployed in YOLOv4
Now we will visit the data augmentation strategies that YOLOv4 deployed during training. The research process is characterized by a series of experiments, so we can imagine that the authors experimented with many more strategies that did not make it into the final paper.
This is further evidence that it is important to explore various data augmentation strategies on your own train/test sets in custom vision tasks.
CutMix - Combine images by cutting parts from one image and pasting them onto the augmented image. Cutouts of the image force the model to learn to make predictions based on a robust amount of features.
See "Hide and Seek" above where, without cutouts, the model relies specifically on a dog's head to make a prediction. That is problematic if we want to accurately recognize a dog whose head is hidden (perhaps behind a bush).
In CutMix, the cutout is replaced with a part of another image along with the second image's ground truth labeling. The ratio of each image is set in the image generation process (for example, 0.4/0.6).
In the picture below, you can see how the authors of CutMix demonstrate that this technique can work better than simple MixUp and Cutout.

Mosaic data augmentation - Mosaic data augmentation combines 4 training images into one in certain ratios (instead of only two in CutMix).
Mosaic [video] is the first new data augmentation technique introduced in YOLOv4. This allows for the model to learn how to identify objects at a smaller scale than normal. It also is useful in training to significantly reduce the need for a large mini-batch size.

Class label smoothing - Class label smoothing is not an image manipulation technique, but rather an intuitive change to class labeling. Generally, the correct classification for a bounding box is represented as a one hot vector of classes [0,0,0,1,0,0, ...] and the loss function is calculated based on this representation.
However, when a model becomes overly sure with a prediction close to 1.0, it is often wrong, overfit, and over looking the complexities of other predictions in some way. Following this intuition, it is more reasonable to encode the class label representation to value that uncertainty to some degree. Naturally, the authors choose 0.9, so [0,0,0,0.9, 0....] to represent the correct class.
Self-Adversarial Training (SAT) - This technique uses the state of the model to inform vulnerabilities by transforming the input image. First, the image is passed through a normal training step. Then, rather than back-propping through the weights, the loss signal is used to alter the image in a way that would be most detrimental to the model.
Later on in training, the model is forced to confront this particularly hard example and learn around it. Of the techniques we have covered here, this one is probably the least intuitive and closest to the modeling side of things.
🎉 Now we have a comprehensive view of all the data augmentation techniques utilized in YOLOv4!

Use Data Augmentation in your Own Computer Vision Projects
We're excited to see that the advances in model performance focus on data augmentation just as much as model architecture. In seeing the difference between YOLOv4 versus YOLOv3 focus on data augmentation, we suspect these "bag of freebie" techniques can be useful for any architecture.
Thus, at Roboflow, we're making it easy to one-click augment your data with state-of-the-art augmentation techniques. We handle transforming images and updating bounding boxes in the most optimum way so you can focus on your domain problem, not scripts to manipulate images.
Good luck building! 🖼
Want to put the theory into practice? Try out our tutorial on how to train YOLOv4.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (May 13, 2020). Data Augmentation in YOLOv4. Roboflow Blog: https://blog.roboflow.com/yolov4-data-augmentation/