
EfficientDet and YOLO are two of the most recognized approaches to real-time object detection. EfficientDet, from the Google Brain team, is built around parameter efficiency: an EfficientNet backbone, a bi-directional feature pyramid network (BiFPN), and a compound scaling rule that produces a D0-to-D7 family. YOLO is a family of single-stage detectors known for fast inference and a broad, active ecosystem, from the original YOLOv3 through many later versions.
This post compares EfficientDet vs YOLO on the dimensions that actually decide a project: architecture, accuracy against compute, inference speed, task versatility, licensing, and how hard each is to take to production. It also covers what to train today if your goal is a deployable detector, which is RF-DETR, and how to train one on your own data in Roboflow.
Find the top object detection model rankings live on Roboflow Playground.
EfficientDet vs YOLO
Both are single-stage detectors, meaning they predict classes and boxes in one pass rather than proposing regions first like the two-stage Faster R-CNN. They differ in what they optimize for.
EfficientDet optimizes for accuracy per unit of compute. Its BiFPN fuses features across scales in both directions with learnable weights, and compound scaling grows the backbone, feature network, and prediction head together, so you can dial model size to your hardware while staying near the efficiency frontier. EfficientDet is strictly an object detector.
YOLO optimizes for real-time speed and developer ergonomics. The family has evolved from YOLOv3's anchor-based head to later anchor-free designs, and modern YOLO versions add tasks beyond detection, such as segmentation, classification, and pose. That versatility and a large community are the main reasons teams reach for it.
Architecture: How Each Works
EfficientDet
EfficientDet keeps detection framed as bounding box regression plus classification, and puts its engineering into three places. It uses EfficientNet, an ImageNet-pretrained convolutional backbone, to extract features. It fuses those features with a BiFPN, which passes information top-down and bottom-up and weights each input by how much it contributes. And it scales the whole network, backbone, BiFPN, and head, with a single compound coefficient. For a deeper walkthrough, see the EfficientDet architecture breakdown.
YOLO
YOLO framed detection as a single regression problem early on, which is what made it fast enough for real-time use. Across versions the family refined the backbone, the training recipe, and the detection head, moving from anchor boxes toward anchor-free heads and multi-task outputs. The through-line is the same: one network, one forward pass, low latency. The tradeoff historically has been accuracy on small or crowded objects relative to heavier designs, which later versions worked to close.
Accuracy, Speed, and Size
On COCO, EfficientDet showed strong accuracy for its compute budget, and its smallest variants are tiny in parameter count, which is attractive for constrained hardware. YOLO's strength is latency: the family is engineered for high frames per second on modern GPUs, and its tooling makes that speed easy to reach.
The accuracy-versus-speed gap between well-implemented detectors narrows every year, and which one wins on a given dataset depends heavily on your data, your input resolution, and how carefully each is trained. Benchmarks on public datasets are a starting point, not a verdict for your problem.
The dimension that tends to matter more in practice is the one benchmarks rarely show: how cleanly the model goes from a trained checkpoint to something running in production, and under what license.
Task Versatility and Licensing
YOLO's later versions support multiple tasks in one architecture, which is a real advantage if you need detection, segmentation, and pose from a single toolchain. EfficientDet is detection only. Licensing is where teams often get surprised: several popular YOLO implementations carry AGPL or other restrictive licenses that create obligations for commercial use, which legal teams flag late in a project. EfficientDet's reference code is more permissively licensed, but it lacks the momentum and production tooling that a modern deployment needs.
This is the gap RF-DETR is built to close.
What to Train Today: RF-DETR
If your goal is a detector you will actually deploy, the strongest current choice is RF-DETR. RF-DETR is a real-time detection transformer that reaches state-of-the-art accuracy on real-world data, fine-tunes quickly on a custom dataset, and runs in real time from cloud to edge. It ships under a permissive Apache 2.0 license, so there is no commercial-use friction to discover late in the process.
RF-DETR takes the goal EfficientDet was chasing, high accuracy at a controlled compute budget, and the goal YOLO delivers on, real-time speed, and gives you both in one architecture with a clean licensing and deployment story. That is why the hands-on path below trains RF-DETR rather than either older family.
Train a Custom Detector in Roboflow
You can train, evaluate, and deploy RF-DETR on your own images without setting up a GPU or a training environment. Here is the full path.
What you need
Three things: a free Roboflow account, some images to work with (yours or a public dataset), and a browser. Add a local Python install only if you intend to script inference at the end.
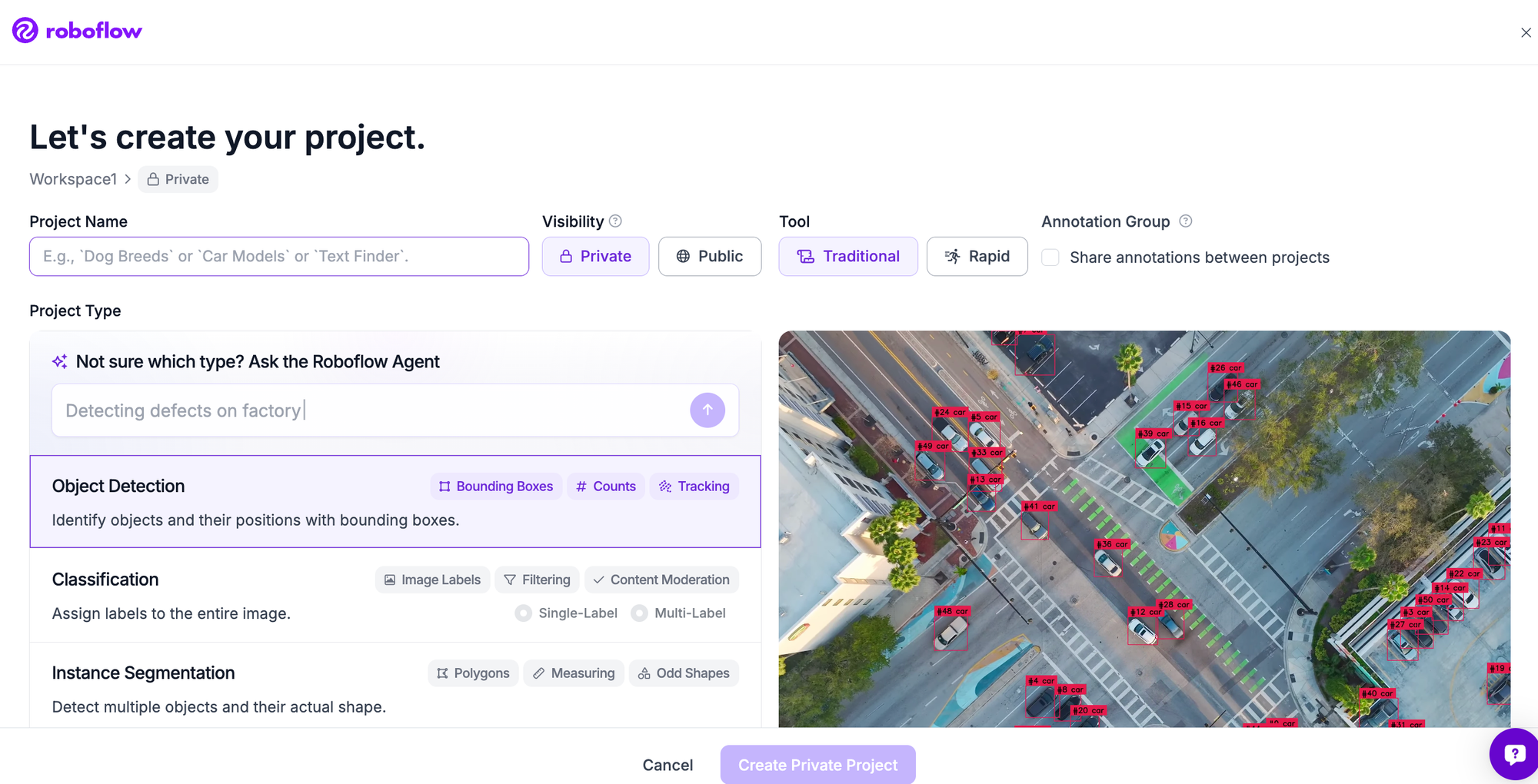
Step 1: Create a project
Once you are signed in, spin up a new project, pick Object Detection as its type, and define the classes you want the model to find.
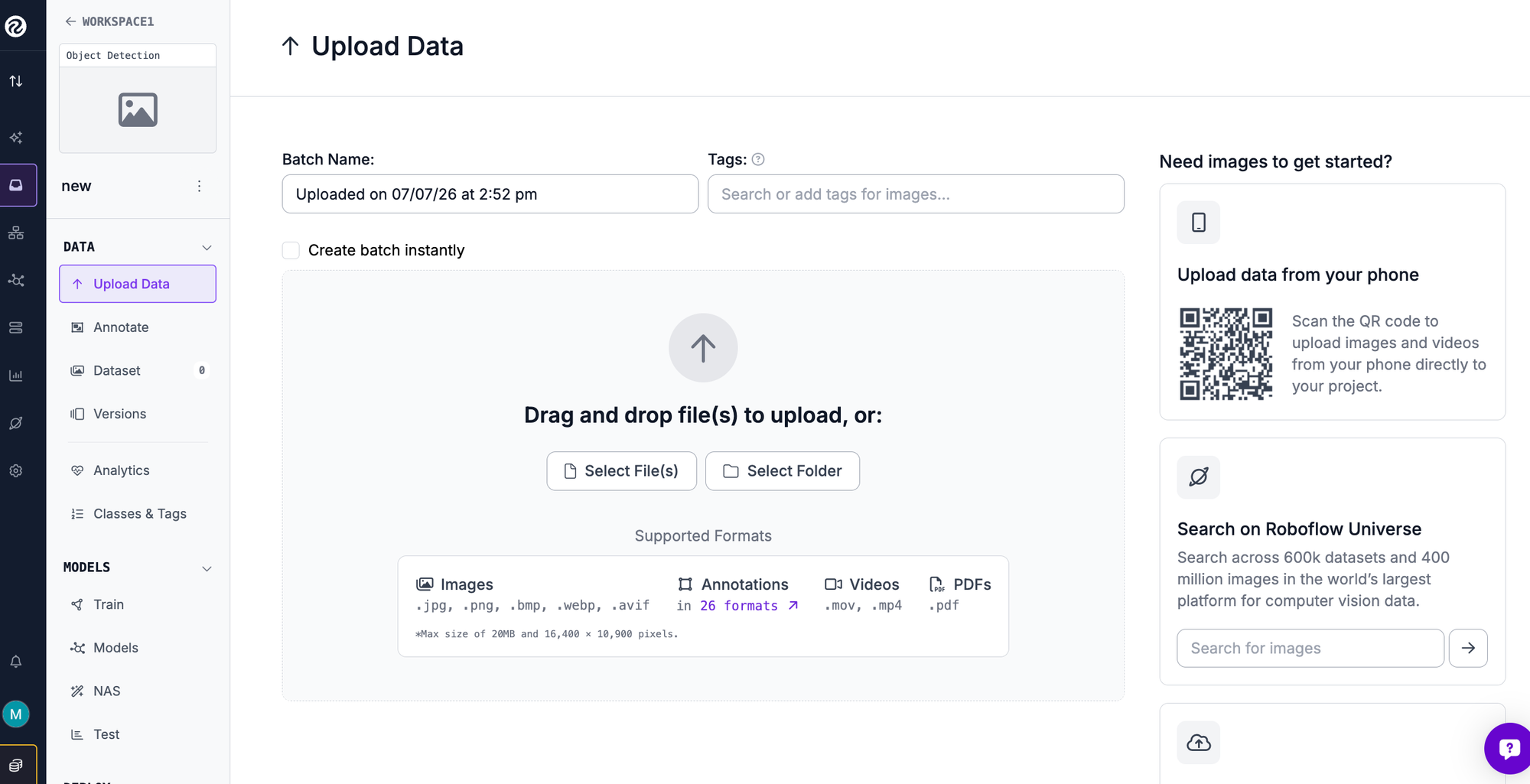
Step 2: Upload your images
Bring images into the project by dragging them in. To skip the cold start, Roboflow Universe offers over 200,000 open datasets and pretrained models you can fork, many of which arrive already annotated. Labels in COCO, Pascal VOC, and other formats import on their own.
Step 3: Annotate your images
Draw and class your boxes in Roboflow Annotate. Auto Label pre-fills annotations with a foundation model for you to correct, while Label Assist suggests boxes on each frame as you work. Clean, consistent annotations lift accuracy more than any model swap.
Step 4: Generate a dataset version
A dataset version locks your labeled images together with the preprocessing and augmentation you select, and Roboflow handles the train, validation, and test split. Auto-orient and resize are safe defaults for nearly any dataset, and augmentations such as flips or slight rotations stretch a small dataset further while curbing overfitting.
Step 5: Train your model
Kick off Roboflow Custom Training, select RF-DETR, and begin from the COCO-pretrained checkpoint so the model already grasps generic objects and only has to learn yours. That head start, transfer learning, is why a few hundred labeled images usually does the job. The run happens in the cloud, and small datasets tend to finish inside an hour.
Step 6: Evaluate your model
When training ends, Roboflow surfaces mean average precision (mAP) on the held-out test set alongside precision and recall. Study the per-class figures rather than the headline number, since an imbalanced dataset can bury a struggling class under a strong average. Wherever a class falls short, fix or add labels and train again.
Step 7: Run inference
Serve your model through the Serverless Hosted API and call it from a few lines of Python. Install the SDK:
pip install inference-sdk supervision
Then run your model on an image, passing your API key through an environment variable:
import os
import cv2
import supervision as sv
from inference_sdk import InferenceHTTPClient
client = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key=os.getenv("ROBOFLOW_API_KEY"),
)
# model_id is "project-name/version", e.g. "your-project/1"
result = client.infer("image.jpg", model_id="your-project/1")
image = cv2.imread("image.jpg")
detections = sv.Detections.from_inference(result)
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
annotated = box_annotator.annotate(scene=image.copy(), detections=detections)
annotated = label_annotator.annotate(scene=annotated, detections=detections)
cv2.imwrite("annotated.png", annotated)
The supervision library handles drawing and post-processing so you are not writing box math by hand.
Step 8: Deploy to production
To run the model close to where images are captured, Roboflow Inference is the open source engine for cloud, on-prem, or edge hardware such as NVIDIA Jetson. Stitch it into an application with Roboflow Workflows, a low-code builder for adding logic like filtering, counting, and triggers, and connect your workspace to coding agents such as Claude Code, Codex, and Cursor through the Roboflow MCP server.
Should I use EfficientDet or YOLO?
Both are capable detectors, and the winner on a given dataset depends on your data, resolution, and training care more than on the architecture name. EfficientDet leans toward parameter efficiency, YOLO toward real-time speed and multi-task versatility. If you are choosing a detector to deploy today, RF-DETR is the stronger option: it matches the accuracy goal of EfficientDet and the speed goal of YOLO, and it ships under a permissive Apache 2.0 license with a clean path to production.
Is EfficientDet faster than YOLO?
It depends on the variant and hardware. YOLO is engineered for high frames per second and usually wins on raw latency, while EfficientDet's small variants win on parameter count and memory. For most teams the more decisive factor is deployment and licensing, which is where RF-DETR has an edge over both.
Can I train EfficientDet or YOLO in Roboflow?
Roboflow trains RF-DETR for custom object detection, because it reaches state-of-the-art accuracy, fine-tunes fast, runs in real time, and ships under a permissive license. Roboflow also trains YOLO (see how to train YOLOv8 in Roboflow). You can still export your dataset in COCO, Pascal VOC, and other standard formats if you want to train EfficientDet or a YOLO variant in your own environment.
What is the difference between EfficientDet and YOLOv3?
YOLOv3 is an anchor-based single-stage detector optimized for real-time speed. EfficientDet is a later single-stage detector that adds an EfficientNet backbone, a BiFPN for multi-scale feature fusion, and compound scaling to improve accuracy per unit of compute. EfficientDet generally posts better accuracy for its size, while YOLOv3 is prized for simplicity and speed.
How much data do I need to train a custom detector?
With transfer learning from a COCO-pretrained checkpoint, a few hundred labeled images per class is often enough to get a working model. Start small, evaluate the per-class metrics, and add data where the model is weak.
Get Started: EfficientDet vs YOLO
You can train a custom object detection model on your own images today, entirely in the browser, and have a deployable model in an afternoon. Create a free Roboflow account and start with your dataset or one from Universe.
Further reading:
Cite this Post
Use the following entry to cite this post in your research:
Erik Kokalj. (Feb 11, 2026). EfficientDet vs YOLO for Object Detection. Roboflow Blog: https://blog.roboflow.com/yolov3-versus-efficientdet-for-state-of-the-art-object-detection/