
EfficientDet is a single-stage object detector that combines an EfficientNet backbone, a bi-directional feature pyramid network (BiFPN) for multi-scale feature fusion, and compound scaling to produce a D0-to-D7 family that trades accuracy against compute along a clean curve. To train a custom detector on your own data today, you can label images and fine-tune RF-DETR in Roboflow with no GPU, then deploy from cloud to edge.
EfficientDet is a family of object detection models from the Google Brain team that pairs an EfficientNet backbone with a bi-directional feature pyramid network (BiFPN) and a compound scaling rule that grows the backbone, feature network, and prediction head together. The result is a set of detectors, D0 through D7, that trade accuracy against compute along a clean curve, from mobile-sized models to server-grade ones.
This post breaks down how EfficientDet works: the problem it set out to solve, the EfficientNet backbone it builds on, the BiFPN feature fusion at its core, and the compound scaling that ties it together. It also covers where EfficientDet fits today and how to train a custom object detection model on your own data in Roboflow.
What Is EfficientDet?
EfficientDet is a single-stage object detector introduced in the 2019 paper EfficientDet: Scalable and Efficient Object Detection. Its goal was to make detection scale predictably: instead of hand-designing a separate model for every compute budget, define one architecture and one scaling rule, then dial the size up or down for the hardware you have.
An object detector has three parts: a backbone that turns pixels into features, a feature network that fuses those features across scales, and a class/box head that predicts a label and a bounding box for each object. EfficientDet's contribution is a specific, efficient choice for each part plus a rule for scaling all three at once.
The EfficientNet Backbone
EfficientDet builds on EfficientNet, a convolutional backbone the same team designed by studying how to scale a network. The insight behind EfficientNet is compound scaling: rather than making a network only deeper, only wider, or only higher-resolution, you scale depth, width, and input resolution together with a fixed ratio.
A neural architecture search produces a baseline network, EfficientNet-B0, and the compound rule scales it up through B7. Pretrained on ImageNet, EfficientNet is a strong, efficient feature extractor, which is why EfficientDet uses it as the backbone.
BiFPN feature fusion
Features from the backbone come at different resolutions, and a detector has to combine them so it can find both small and large objects. Earlier designs handled this with a top-down feature pyramid network (FPN), then with PANet, which adds a bottom-up path, and then with NAS-FPN, an irregular topology discovered by search.
EfficientDet introduces the BiFPN, a bi-directional feature pyramid network. It fuses features top-down and bottom-up, and it adds learnable weights so the network can decide how much each input feature contributes rather than treating them equally. The BiFPN block is designed to be stacked, and the number of stacks is one of the things the scaling rule adjusts.
Compound scaling for detection
The final piece extends compound scaling from the backbone to the whole detector. A single compound coefficient jointly scales the backbone size, the BiFPN width and depth, the class/box head, and the input resolution. That is what produces the D0-to-D7 family: one architecture, one scaling knob, a spread of models that stay near the efficiency frontier at every size. On COCO, EfficientDet posted strong accuracy for its compute compared to the detectors of its era.
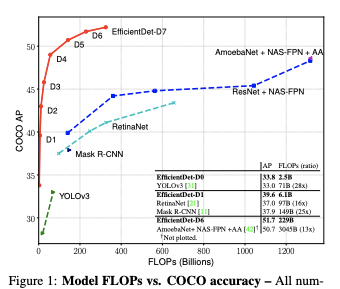
Where EfficientDet fits today
EfficientDet remains a clear, well-documented example of how compound scaling and multi-scale feature fusion work, and the paper is still worth reading to understand modern detector design. For building a detector you plan to deploy, though, transformer-based architectures have moved the accuracy-latency frontier forward since EfficientDet's release.
That is why the hands-on path below trains RF-DETR. RF-DETR is a real-time detection transformer that fine-tunes quickly on a custom dataset, reaches state-of-the-art accuracy on real-world data, and ships under a permissive Apache 2.0 license, so there is no commercial-use friction when you deploy it. You get the efficiency goal EfficientDet was chasing, with an architecture and a training path built for production today.
Train a custom object detection model in Roboflow
You do not need to configure a detector by hand or manage a training environment to get a working model. In Roboflow you upload images, label them, generate a dataset version, and train RF-DETR in the cloud with no GPU to provision. Here is the full path.
What you need
A free Roboflow account, a set of images (your own, or a public dataset), and a web browser. To run inference from a script afterward, you also need Python locally.
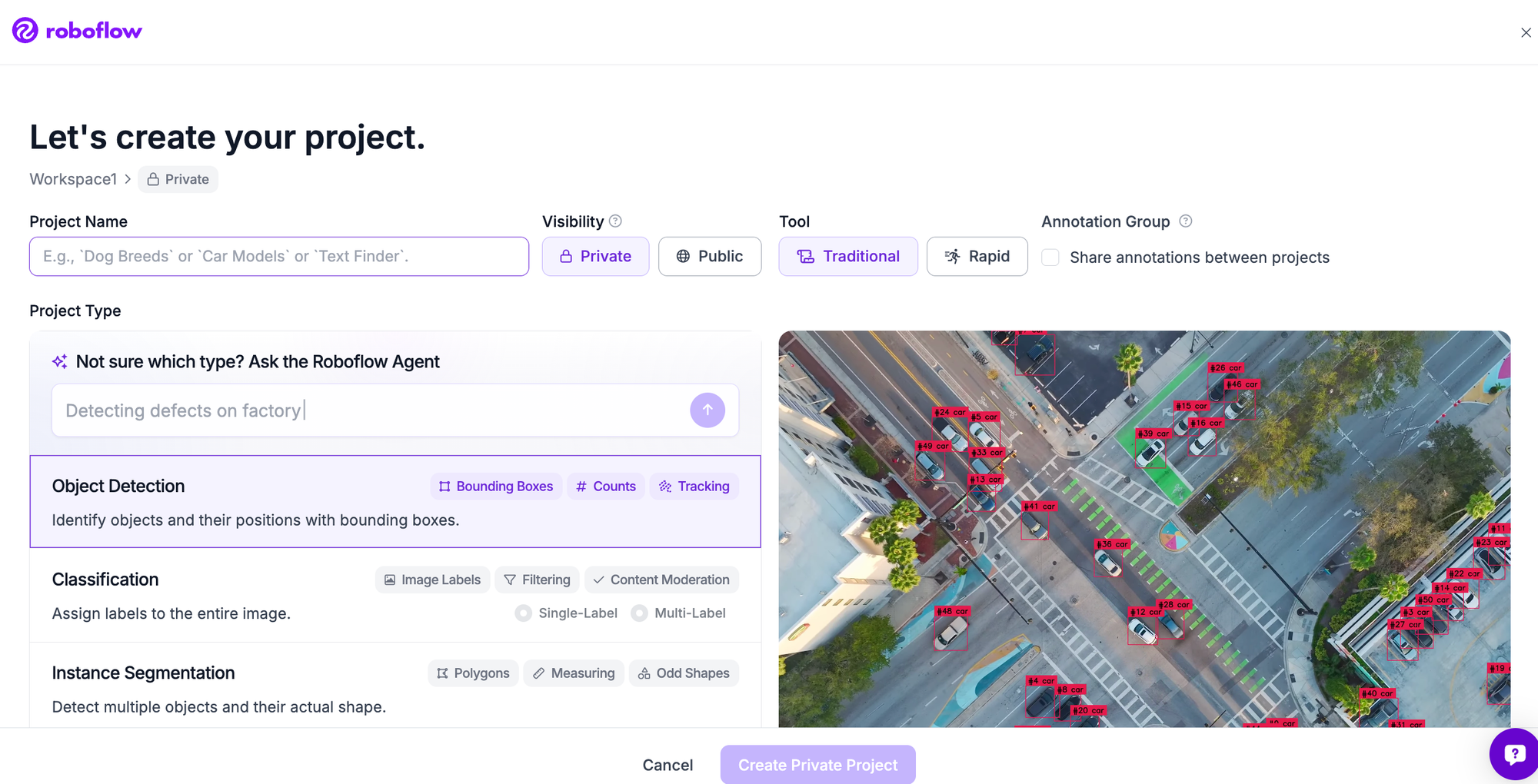
Step 1: Create a project
Sign in to Roboflow, create a project, set the type to Object Detection, and name your classes. This project holds your images, annotations, dataset versions, and trained models.
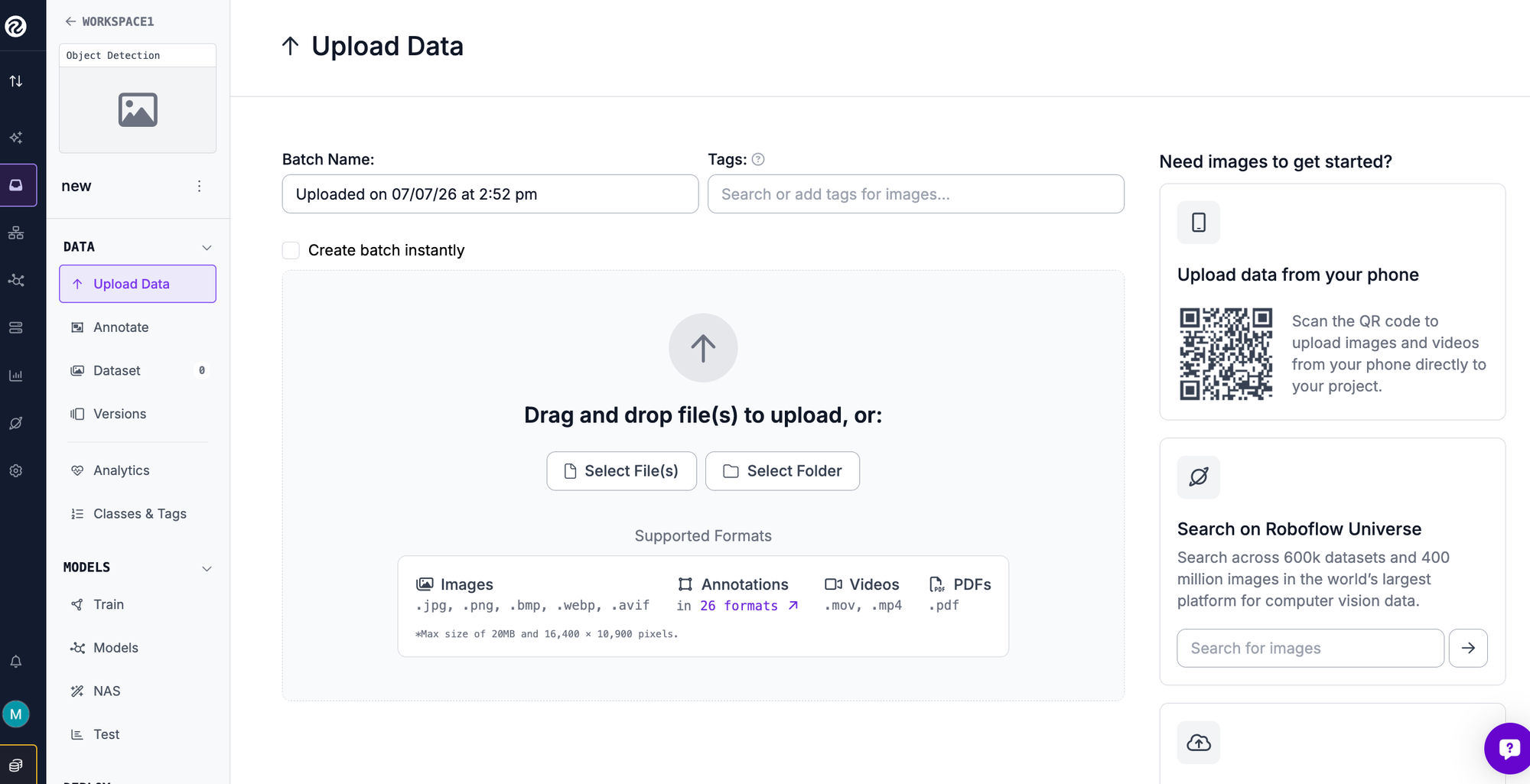
Step 2: Upload your images
Drag in your images. If you want a running start, Roboflow Universe hosts more than 200,000 open datasets and pre-trained models you can fork into your workspace, many already labeled. Roboflow reads existing annotations in COCO, Pascal VOC, and other common formats, or leaves images unlabeled for you to annotate.
Step 3: Annotate your images
Label your images in Roboflow Annotate. Auto Label uses a foundation model to draft annotations for you to review, and Label Assist pre-draws boxes with a model as you go, so you confirm and adjust instead of drawing every box. Tight, consistent labels matter more to final accuracy than any architecture choice.
Step 4: Generate a dataset version
A version is a frozen snapshot of your labeled data plus preprocessing and augmentation. Roboflow auto-splits into train, validation, and test sets. Auto-orient and resize are worth applying to almost any dataset, and augmentations like flips and small rotations expand a small dataset and reduce overfitting. Add only augmentations that reflect variation the model will actually see.
Step 5: Train your model
Start a job with Roboflow Custom Training, choose RF-DETR, and train from the COCO-pretrained checkpoint so the model starts with a general understanding of objects and only learns your classes. This is transfer learning, and it is why a few hundred labeled images is often enough. Training runs in the cloud, so there is nothing to install, and small datasets usually finish in under an hour.
Step 6: Evaluate your model
Roboflow reports mean average precision (mAP) on the held-out test set, along with precision and recall. Read the per-class breakdown, not just the headline number: a class imbalance can hide a weak class behind a healthy overall score. If a class underperforms, add or fix labels for it and retrain. Two or three passes usually move a model from promising to production-ready.
Step 7: Run inference
Serve your model through the Serverless Hosted API and call it from a few lines of Python. Install the SDK:
pip install inference-sdk supervision
Then run your model on an image, passing your API key through an environment variable:
import os
import cv2
import supervision as sv
from inference_sdk import InferenceHTTPClient
client = InferenceHTTPClient(
api_url="https://serverless.roboflow.com",
api_key=os.getenv("ROBOFLOW_API_KEY"),
)
# model_id is "project-name/version", e.g. "your-project/1"
result = client.infer("image.jpg", model_id="your-project/1")
image = cv2.imread("image.jpg")
detections = sv.Detections.from_inference(result)
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
annotated = box_annotator.annotate(scene=image.copy(), detections=detections)
annotated = label_annotator.annotate(scene=annotated, detections=detections)
cv2.imwrite("annotated.png", annotated)
The supervision library handles drawing and post-processing so you are not writing box math by hand.
Step 8: Deploy to production
When you need the model to run where the images are, Roboflow Inference is the open source engine that runs it on the cloud, on-prem, or at the edge on devices like NVIDIA Jetson. To wrap the model in application logic without building a service, Roboflow Workflows is a low-code visual builder for chaining your model with steps like filtering, counting, and triggering actions. And if you work with a coding agent, the Roboflow MCP server connects your workspace to tools like Claude Code, Codex, and Cursor over the Model Context Protocol.
Why RF-DETR for custom object detection?
EfficientDet set out to hit high accuracy at a controlled compute budget, and its compound scaling made that trade explicit. RF-DETR delivers on the same goal with an architecture suited to current production work. It fine-tunes fast, so the evaluate-and-retrain loop that actually improves a model is quick. It runs in real time, so the model you train for analysis can go straight into a live pipeline.
It ships under an Apache 2.0 license, so deploying it in a commercial product is unambiguous. And it lives in one platform that carries you from labeling to training to deployment, so you are not stitching together a backbone, a training framework, and a separate serving stack that each age on their own schedule.
Can I still train EfficientDet in Roboflow?
Roboflow trains RF-DETR for custom object detection rather than EfficientDet. RF-DETR reaches state-of-the-art accuracy, fine-tunes faster, runs in real time, and ships under a permissive license, so it is the better choice for nearly any project that would have reached for EfficientDet. You can still export your dataset in standard formats if you want to train EfficientDet in your own environment.
Is EfficientDet a one-stage or two-stage detector?
EfficientDet is a single-stage detector. It predicts classes and bounding boxes directly from the fused features, without a separate region proposal stage like the two-stage Faster R-CNN.
What is the difference between EfficientNet and EfficientDet?
EfficientNet is an image classification backbone built around compound scaling. EfficientDet is an object detection architecture that uses EfficientNet as its backbone, adds a BiFPN for multi-scale feature fusion, and adds a class/box head to predict detections.
What is a BiFPN?
A BiFPN, or bi-directional feature pyramid network, is EfficientDet's feature fusion module. It combines features across resolutions in both top-down and bottom-up directions and uses learnable weights so the network can weigh each input feature by how much it contributes to the prediction.
How much data do I need to train a custom detector?
With transfer learning from a COCO-pretrained checkpoint, a few hundred labeled images per class is often enough to get a working model. Start small, evaluate the per-class metrics, and add data where the model is weak.
Get started
You can train a custom object detection model on your own images today, entirely in the browser, and have a deployable model in an afternoon. Create a free Roboflow account and start with your dataset or one from Universe.
Cite this Post
Use the following entry to cite this post in your research:
Erik Kokalj. (Feb 22, 2026). EfficientDet for Object Detection. Roboflow Blog: https://blog.roboflow.com/breaking-down-efficientdet/