
Less than 50 days after the release YOLOv4, YOLOv5 improves accessibility for realtime object detection.
June 29, YOLOv5 has released the first official version of the repository. We wrote a new deep dive on YOLOv5.
June 12, 8:08 AM CDT Update: In response to to community feedback, we have written a more detailed post comparing YOLOv4 and YOLOv5 and included commentary on Glenn Jocher's decision to name the model YOLOv5. Thank you for continued reactions.
Realtime object detection is improving quickly. The rate of improvement is improving even more quickly. The results are stunning.
On March 18, Google open sourced their implementation of EfficientDet, a fast-training model with various sizes, one of which offers realtime output. On April 23, Alexey Bochoviskiy et al. open sourced YOLOv4. On June 9, Glenn Jocher open sourced an implementation of YOLOv5.
Just Looking to Train YOLOv5?
Skip this info post and jump straight to our YOLOv5 tutorial. You'll have a trained YOLOv5 model on your custom data in minutes.
The Evolution of YOLO Models
YOLO (You Only Look Once) is a family of models that ("PJ Reddie") Joseph Redmon originally coined with a 2016 publication. YOLO models are infamous for being highly performant yet incredibly small – making them ideal candidates for realtime conditions and on-device deployment environments.
Redmon research team is responsible for subsequently introducing YOLOv2 and YOLOv3, both of which made continued improvement in both model performance and model speed. In February 2020, Redmon noted he would discontinue research in computer vision.
In April 2020, Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao introduced YOLOv4, demonstrating impressive gains.
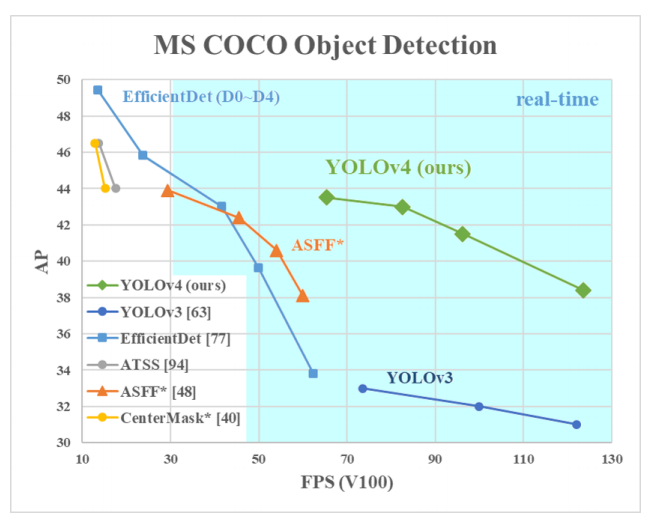
Notably, many of YOLOv4's improvements came from improved data augmentation as much as model architecture. (We've written a breakdown on YOLOv4 as well as how to train a YOLOv4 model on custom objects.)
YOLOv5: The Leader in Realtime Object Detection
Glenn Jocher released YOLOv5 with a number of differences and improvements. (Notably, Glenn is the creator of mosaic augmentation, which is an included technique in what improved YOLOv4.) The release of YOLOv5 includes five different models sizes: YOLOv5s (smallest), YOLOv5m, YOLOv5l, YOLOv5x (largest).
Let's breakdown YOLOv5. How does YOLOv5 compare?
First, this is the first native release of models in the YOLO family to be written in PyTorch first rather than PJ Reddie's Darknet. Darknet is an incredibly flexible research framework, but it is not built with production environments in mind. It has a smaller community of users. Taken together, this results in Darknet being more challenging to configure and less production-ready.
Because YOLOv5 is implemented in PyTorch initially, it benefits from the established PyTorch ecosystem: support is simpler, and deployment is easier. Moreover as a more widely known research framework, iterating on YOLOv5 may be easier for the broader research community. This also makes deploying to mobile devices simpler as the model can be compiled to ONNX and CoreML with ease.
Second, YOLOv5 is fast – blazingly fast. In a YOLOv5 Colab notebook, running a Tesla P100, we saw inference times up to 0.007 seconds per image, meaning 140 frames per second (FPS)! By contrast, YOLOv4 achieved 50 FPS after having been converted to the same Ultralytics PyTorch library.
UPDATE: YOLOv5 achieves 140 frames per second in batch, which the YOLOv5 implementation tested utilizes by default. When batch size is set to 1, YOLOv4 achieves 30FPS while YOLOv5 outputs 10 FPS. Please see our detailed methodology update.
Third, YOLOv5 is accurate. In our tests on the blood cell count and detection (BCCD) dataset, we achieved roughly 0.895 mean average precision (mAP) after training for just 100 epochs. Admittedly, we saw comparable performance from EfficientDet and YOLOv4, but it is rare to see such across-the-board performance improvements without any loss in accuracy.
Fourth, YOLOv5 is small. Specifically, a weights file for YOLOv5 is 27 megabytes. Our weights file for YOLOv4 (with Darknet architecture) is 244 megabytes. YOLOv5 is nearly 90 percent smaller than YOLOv4. This means YOLOv5 can be deployed to embedded devices much more easily.
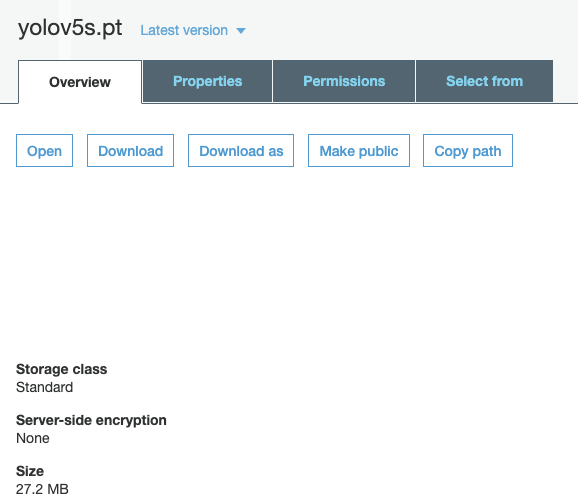
UPDATE: The YOLOv5 model tests is YOLOv5s, which is 27MB. The YOLOv4 model tested is "big YOLOv4," which is 250 MB. The biggest YOLOv5 implementation, YOLOv5l, is 192 MB. We've shared more details about reproducing this in our YOLOv4 versus YOLOv5 update post.
Many of these changes are well-summarized in YOLOv5's graphic measuring performance.
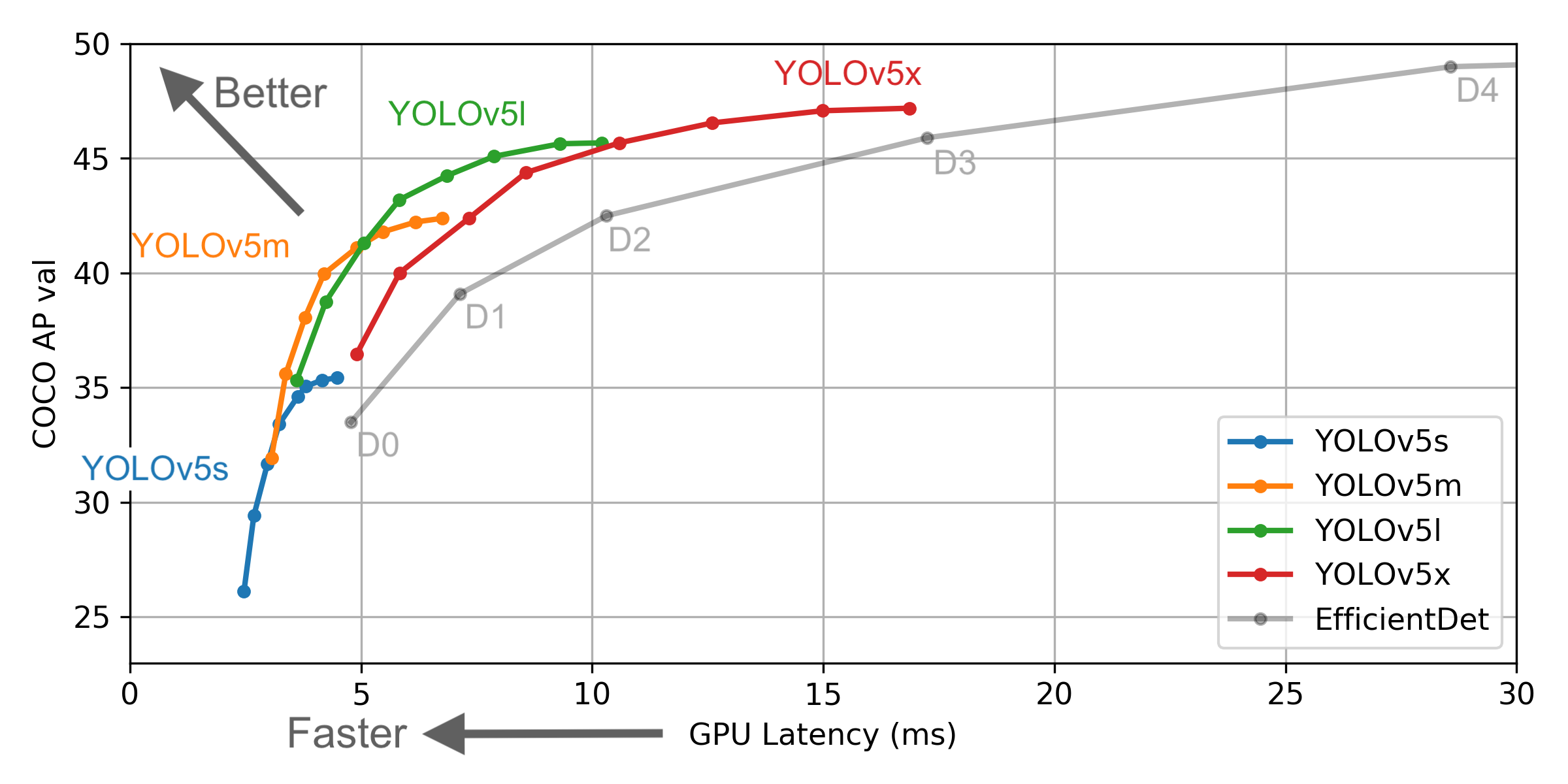
Update June 29th, for an updated evaluation discussion, please see this breakdown of the first YOLOv5 version.
Get Started with YOLOv5
We're eager to see what you are able to build with new state-of-the-art detectors.
To that end, we've published a guide on how to train YOLOv5 on a custom dataset, making it quick and easy. If you would like to use standard COCO weights, see this notebook.
You can always visit YOLOv5 for more resources as they become available.
Stay tuned for additional deeper dives on YOLOv5, and good luck building!
Cite this Post
Use the following entry to cite this post in your research:
Joseph Nelson, Jacob Solawetz. (Jun 10, 2020). YOLOv5 is Here: State-of-the-Art Object Detection at 140 FPS. Roboflow Blog: https://blog.roboflow.com/yolov5-is-here/