
When a computer vision model underperforms, the first place to look is usually the dataset rather than the architecture or hyperparameters. Roboflow's Dataset Health Check surfaces class imbalance, mislabeled images, and annotation distribution problems before they compound in training, and fixing tight bounding boxes around occluded objects is a consistently high-value annotation improvement. The post covers how to use Health Check alongside careful re-annotation of occluded objects and polygon labels to build a cleaner dataset that gives the model a realistic chance of generalizing.
What to do when your computer vision model needs help
Finally, a trained computer vision model. All of the time and effort spent collecting representative images for a dataset; going through the effort of labeling, preprocessing, and augmenting our dataset to create a more robust training set.
Now, for the part we've been waiting for: it's time to take a look at our training metrics, compare our ground truth labels to the model predictions, and prepare for testing and deployment.
If you've been through this process before, you know the feeling of returning to see a completed dataset training job, only to see a poor outcome in the training metrics. The questions begin to flood your mind: Do I have noisy computer vision data? Did I choose the wrong number of epochs? Am I using the correct computer vision model architecture? These are all common, however, one that we will take a deeper look into in this post is: "Do I have a quality dataset with proper annotations?"
Computer Vision Dataset Quality Assurance
Whether your images have already been annotated, or still require labeling, it's best to inspect the quality of your dataset before moving further. Knowing you have a good class balance is an important piece of the puzzle. Without one, there's a high likelihood we end up with poor training results.
The Dataset Health Check feature provides an opportunity to address this. Balanced classes can help to ensure we don't end up overfitting our model to a specific class. Health Check also gives us an opportunity to take a look at our annotations in case we mislabeled something.
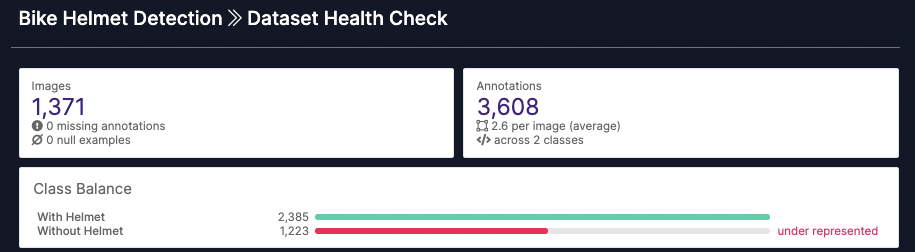
The other great value of the Health Check feature is the ability to search images within our dataset by a specific label present within it. I like to use this as a way to verify I haven't attributed the wrong label to an object within any of my images and for a look at the distribution of labels for a specific class within my train/valid/test split.
Using Roboflow's Dataset Health Check tool to examine class balance and annotation quality.
Improve Computer Vision Models with Better Data
We want to be sure we've created tight bounding boxes around every object of interest that appears within our dataset's images - yes, this includes occluded objects. Occluded objects are those partially obscured behind another object or only present partially within the frame.
We want a model that properly recognizes all objects we've trained it to detect when it is both tested locally, and deployed "in the wild." This is why it is important to create quality annotations the first time. It becomes easier to diagnose the issues with detections, such as low confidence and incorrect detections, when we know we've fed our model with good data, to begin with.
Leveraging the ground truth and model predictions from Roboflow, and the Dataset Health Check feature to search for specific classes within the train/valid/test split, we use the tips from Seven Tips for Labeling Images for Computer Vision to make some upgrades to our annotations.


Labeling and Annotation Examples to Improve Data Quality
Object Detection: Occluded Images
An object is occluded if it is partially "covered" by another object. You still want to label occluded objects, especially if you're wanting to implement object tracking.
Think of it this way: if you want to record a chess match and track the movement of the pieces, you still want to label the white bishop on F1 fully even though it is slightly covered by the white knight on G1. When the white-knight moves and leaves the "full" white bishop in view of your tracking camera, this will help the model with recognizing it as the same object for object-tracking.

Object Detection: Polygons
Alternatively, you can label object detection models on Roboflow with polygons (and bounding boxes too) if you're worried about labeling occluded objects. For example: "hey, I want to label these occluded objects, but there's too much of the bounding box overlapping on other objects." Or: "hey, I want to label all my objects in such a way that the annotations/labels are localized to the outline of the parts of the object that are visible."


Video example of using computer vision with chess
As you've likely guessed by now, if you didn't know already, labeling and quality assurance of your computer vision dataset is not a fun process. This is no secret. Nonetheless, the importance of quality annotations, and balanced classes, cannot be taken for granted. If we want to create a successful model and move towards deploying it, and further improving upon it as we implement active learning, we need to begin with that "end" in mind.
Cite this Post
Use the following entry to cite this post in your research:
Mohamed Traore. (Mar 24, 2022). Improving Computer Vision Datasets and Models. Roboflow Blog: https://blog.roboflow.com/improve-computer-vision-model/