
Occlusion is when part of an object is hidden from view, and models trained on clean images fail on it: augmentations like Cutout, CutMix, Mosaic, and Copy-Paste block or mix regions during training to force generalization beyond one canonical feature. Architecture now does part of the work too, since vision transformers like RF-DETR hold accuracy under heavy occlusion (a ViT keeps 60% top-1 with 80% of the image hidden, while ResNet-50 drops to 0.1% at 50%).
Computer vision models learn a task from a training set. Like all deep learning models, they are prone to overfit the data they have been shown, making poor inferences in the wild.
In this post, we take an overview of occlusion techniques in computer vision and discuss how occlusion based data augmentation techniques can be used to combat the problem of overfitting in computer vision. We also cover newer methods like Copy-Paste, segmentation-aware augmentation with SAM 3, and model architectures that are robust to occlusion out of the box.
What Is Occlusion in Computer Vision?
Occlusion techniques block a portion of an image during training, challenging the network to learn not to rely on one canonical feature.
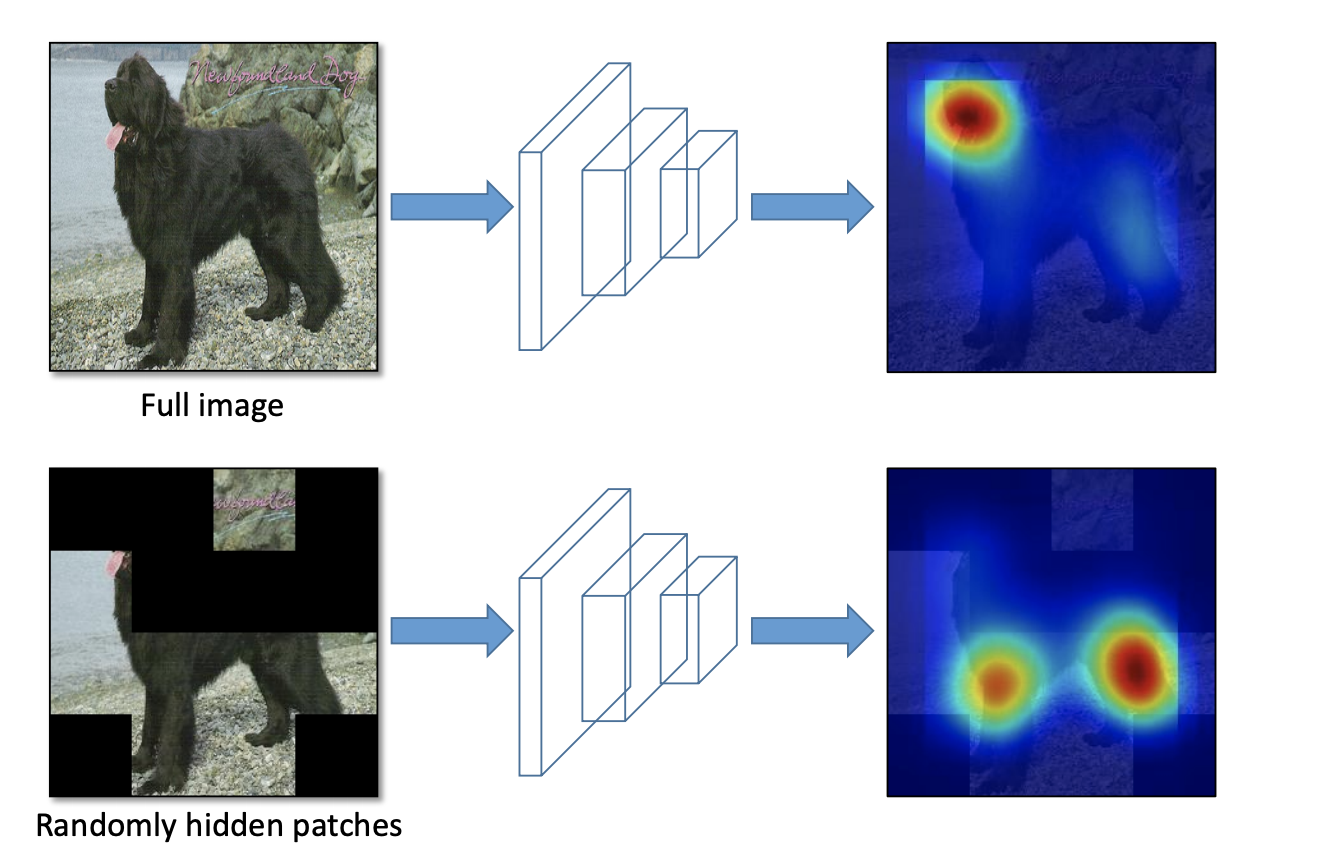
For example, if we train an object detection model to detect dogs, we might only have training data with the dog's head in view. Looking at the Class Activation Map, or CAM (the pixels that contribute the most to a prediction), we might see that the network relies heavily on the dog's head to make predictions.

But what about when the dog's head is behind a bush? We want our network to generalize to situations like this, so it can help to occlude some training images to hide the dog's head and force the network to identify a dog from other parts of its shape.

Classic Occlusion Techniques
Research in occlusion techniques for training deep learning vision models is not new. These methods have been around for years and are still in use today, often built directly into modern training pipelines.
Random Erase: A random rectangular section of the image is erased and replaced with noisy pixels. In a training pipeline, random erase is applied with a random location, width, and height within a set range, and can be applied probabilistically.

Cutout: Random square regions of the input image are zeroed out. The Cutout authors originally tried removing maximally activated features from intermediate layers, but found that simply masking random squares of the input image worked just as well, and it is much simpler to implement.

Hide and Seek: Divide the image into a grid, and randomly hide sections of the grid with some probability. This is similar to GridMask but with random grid cells being removed.
GridMask: Draw a regular grid over the image and hide all squares of the grid.

Techniques That Built On Them
New techniques grew out of the old ones, pushing the state of the art in computer vision modeling with data augmentation.
CutMix: A section of the image is cut out and replaced with a section from a different image, with labels mixed proportionally. This forces the model to predict around occlusion and to stop relying on the surrounding context an object usually appears in. The numbers hold up: CutMix improved ResNet-50 top-1 accuracy on ImageNet by +2.28% over the baseline, cutting top-1 error from 23.68% to 21.40% and beating both Cutout and Mixup. Later variants like PuzzleMix, SaliencyMix, and ContextMix have squeezed out a further ~0.4%, but CutMix remains the standard because it is simple and adds negligible compute.

Mosaic: Mosaic is not an occlusion technique directly, but it accomplishes a similar goal. Mosaic stitches together 4 images in a window, randomly shifting and cropping them along the way. This forces the model to learn around objects occluded at the edges, identify objects in different contexts, and identify objects in different portions of the image.
Introduced with YOLOv4, mosaic is now a default online augmentation in modern trainers. The latest YOLO release, YOLO26, applies mosaic heavily for most of training and then disables it in the final epochs via a close_mosaic schedule, so the model finishes on clean, realistic images. It also scales the augmentation recipe to model size: larger models get stronger mixup and copy-paste, while the nano model gets the mildest recipe. Occlusion augmentation is no longer something you bolt on. It is an engineered schedule inside the trainer.

Copy-Paste: Copy object instances from one image and paste them onto another, using their segmentation masks. Unlike CutMix, only the object's pixels are transferred, not its whole bounding box, so the pasted objects naturally occlude whatever is behind them. Google Research showed that adding Copy-Paste to an already strong model improved COCO results by +1.2 box AP, and combined with self-training it set a new state of the art at the time: 57.3 box AP and 49.1 mask AP, a gain of +1.5 box AP over the previous best. Copy-Paste is now a standard option in most detection and segmentation training pipelines.

Beyond Augmentation: Models Built for Occlusion
Occlusion robustness used to be something you had to train into a CNN. That is no longer the whole story.
Vision transformers are naturally robust to occlusion. The paper Intriguing Properties of Vision Transformers showed that ViTs retain up to 60% top-1 accuracy on ImageNet even after randomly occluding 80% of the image. The CNN comparison is stark: with 50% of image content removed, ResNet-50 dropped to 0.1% accuracy while a similarly sized DeiT-S held 70%. Self-attention lets transformers reason from whatever visible patches remain instead of depending on local texture.
Detection models inherited this. RF-DETR, Roboflow's real-time detection transformer, uses a DINOv2 vision transformer backbone that adapts well to small datasets and complex, occluded scenes. RF-DETR-2XL is the first real-time model to break 60 AP on the Microsoft COCO benchmark, and RF-DETR-L reaches 56.5 AP at 6.8 ms on an NVIDIA T4, ahead of YOLO models of comparable size. It also leads RF100-VL, the benchmark that measures how well models transfer to real-world domains, where occlusion is the norm rather than the exception.
Since launch, the family has grown to cover instance segmentation (3x faster and more accurate than the largest YOLO11 on the COCO segmentation benchmark) and keypoint detection, in sizes from Nano to 2XL, and the neural architecture search used to build these models is now available on the Roboflow platform to find the best architecture for your own dataset. If your deployment environment has heavy occlusion, picking an architecture like RF-DETR can matter as much as your augmentation strategy.
Segmentation models now track through occlusion. SAM 2 introduced a streaming memory architecture that maintains object identity across video frames even when objects are temporarily hidden. SAM 3, Meta's latest Segment Anything model, integrated across the Roboflow platform, goes further: its tracker merges propagated masks with new detections each frame, keeping instances consistent through occlusion and re-appearance, all from a plain text prompt like "helmet" or "forklift." Masks capture exact object shapes, which matters most when objects are small, overlapping, or partially hidden. You can run SAM 3 zero-shot in Workflows, use it to auto-label entire datasets, or fine-tune it on your own data.
None of this makes occlusion augmentation obsolete. Fine-tuned models still overfit to small datasets, and augmentation is still the cheapest fix. But it changes the baseline you are starting from.
Occlusion Augmentation, the Modern Way
A few practical notes for applying these techniques today:
Establish a baseline first. Train once with no augmentations so you have something to compare against. If the un-augmented model performs poorly, look at class balance, data representation, and dataset size before reaching for augmentation. This is Roboflow's recommended workflow.
Don't apply mosaic twice. Modern trainers like YOLO26's apply mosaic, mixup, copy-paste, and random erasing online during training by default. If you also bake mosaic into your dataset offline, the model sees mosaics of mosaics, and it never gets the clean final epochs the close_mosaic schedule is designed to provide. Roboflow's mosaic augmentation docs flag this explicitly. Check what your trainer already does before adding offline occlusion augmentations on top.
Use masks to make occlusion augmentation label-safe. Cropping and erasing can truncate bounding boxes or leave labels pointing at hidden objects. With instance segmentation masks, transformations preserve object integrity. You can auto-label a dataset with SAM 3 and apply segmentation-aware augmentation in Roboflow, simulating real-world occlusion without introducing label noise.
Both Cutout and Mosaic are available in Roboflow as Enhanced Augmentations, alongside crop, noise, and the other standard options.
A Hands On Occlusion Example (Chess)
Let's suppose we want to train an object detection model to recognize chess pieces. We have gathered a chess dataset and made our chess dataset public on Roboflow Universe.
With limited training data, it is possible that our model will only see chess pieces in a non-occluded fashion like this image:

Yet, at inference time, our model may need to make predictions on chess pieces that are occluded like this image:

Therefore, it may be advantageous to experiment with adding some occlusion augmentations to our training data to improve our model's resilience.
Experimenting with adding occlusion to our training images in Roboflow
Conclusion
Occlusion techniques improve the resiliency of your computer vision model, teaching it to generalize beyond the canonical features of an image.
Two things are true at once: augmentation methods like CutMix and Copy-Paste are now standard parts of training pipelines, and transformer-based models like RF-DETR and SAM 3 are robust to occlusion by design. If your model is overfitting to certain features in your training set, occlusion augmentation is still one of the first things to try. Just make sure it isn't already happening online in your trainer, and consider whether your architecture is doing some of the work for you.
Happy occluding, and as always, happy training.
Cite this Post
Use the following entry to cite this post in your research:
Aarnav Shah. (May 8, 2026). Occlusion Techniques in Computer Vision. Roboflow Blog: https://blog.roboflow.com/occlusion-computer-vision/