
An independent benchmark of AWS Rekognition Custom Labels, Azure Custom Vision, and Google Cloud AutoML Vision measures each across training time, training cost, model accuracy on MS COCO and Pascal VOC, inference speed, and inference cost. Open source models perform on par with all three cloud options, and the right choice depends on budget, required latency, and inference volume. Teams needing a balance of accuracy and sustainable long-term cost should test all three through Roboflow before committing.
Comparing AWS Rekognition, Google Cloud AutoML, and Azure Custom Vision for Object Detection
All three major cloud providers have recently launched no-code tools for training custom object detection models. But, until now, there has been little independent research published on their performance (both relative to each other and against state of the art open source models). We ran a standard dataset through all three tools to see how they stack up against each other.
If you are considering using computer vision services from Google Cloud, AWS, or Azure in your product (or you have trained an object detection model of your own and are wondering where you stand in comparison to AutoML) this is the post for you.
In this post, we review Amazon Rekognition Custom Labels, Azure Custom Vision, and Google Cloud AutoML Vision. We'll weigh the pros/cons between them and we'll also compare them against results from YOLOv5x, a current-generation open source model.
Looking for a better option?
Roboflow Train provides state of the art custom models trained on your dataset deployed to an infinitely scalable API (and supports deploying that same model to a web browser and edge devices too).
We evaluate each product on the following factors:
- Training Time (how long to train the model)
- Training Cost (how much to train the model)
- Model Performance (how accurate is the model)
- Inference Time (how long to predict on a test image)
- Inference Costs (how much to predict once on a test image)
We also provide insight into the major limitations of each platform and ease of use.
Summary:
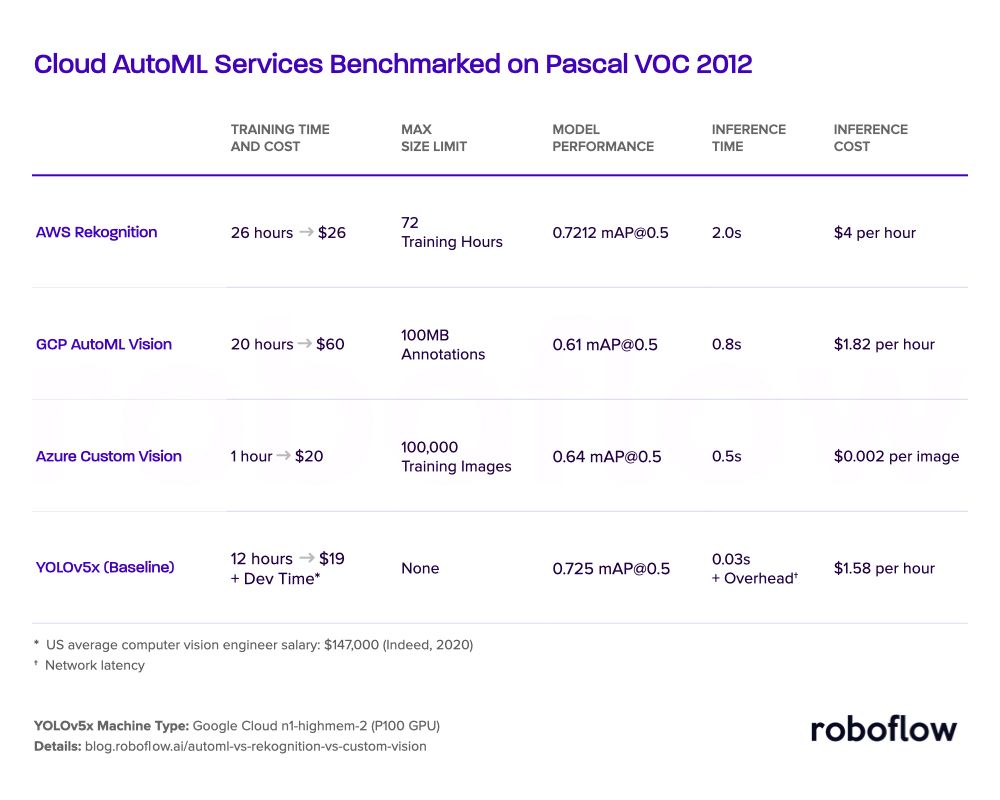
Our overall conclusion: AutoML tools are a great way to assess the feasibility of a computer vision project, even if you plan to eventually train a custom model architecture. Evaluating tradeoffs among the big three cloud providers depends on your project specifications (how important is inference speed; what accuracy threshold is required; what inference volume do you expect; what is the size of your dataset). Open source model architectures, while expensive to build and maintain, perform on par with big cloud provider options.
Unfortunately, each platform uses its own proprietary API and data format so it is very cumbersome to get started and compare solutions. Moreover, once you're up and running, you're locked in. (Luckily, Roboflow Pro solves this by seamlessly integrating with all three including exporting to Amazon Sagemaker Ground Truth Object Detection Manifest format and Google Cloud AutoML Vision CSV format.)
Overview of the AutoML Process
No matter which platform you choose, you will be entering a similar workflow to create and deploy your computer vision model.
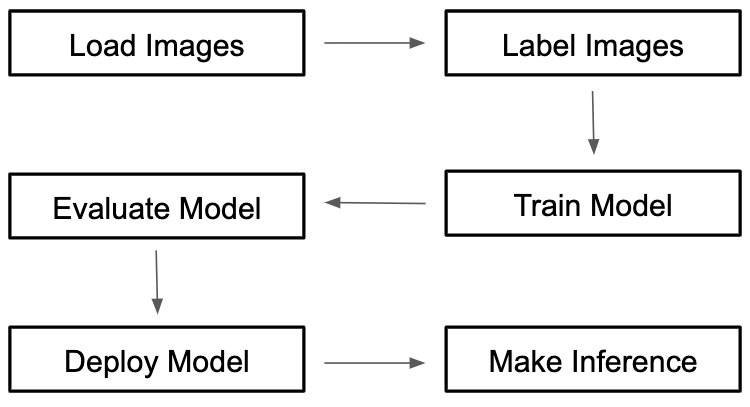
Data Preparation - In order to train a computer vision model, you first need to acquire images that appear in your domain of interest. The narrower you keep your domain the better your model will perform. Then, your images will need to be labeled (in the proper annotation format) providing supervision to train your model to learn the vision concepts in question.
Model Training and Evaluation - you will kick of training, a process where the computer formulates an algorithm based on training images to apply to images that it has never seen. Your model will then be evaluated based on how well it performs during predictions. This may be an iterative process as you add data and adjust training length.
Model Deployment and Inference - Once you have a suitable model, you will deploy this model to a compute instance and stand up an API endpoint that you can hit to receive predictions based on what your model is seeing in your production images.
The cloud providers separate data labeling from AutoML, and we will be focusing on reviewing the AutoML service in this post, assuming you have already collected a labeled dataset.
If you still need to label your images, please follow one of these tutorials:
- CVAT Object Detection Annotation Tutorial
- VoTT Object Detection Annotation Tutorial
- LabelImg Object Detection Annotation Tutorial
- LabelMe Object Detection Annotation Tutorial
The Big Cloud AutoML Challenge - MS COCO
The original plan was to benchmark these services on the modern standard, the Microsoft Common Objects in Context Object Detection (COCO) dataset.
Unfortunately, all three tools failed this challenge and we were unable to complete training on COCO.
Rekognition Custom Labels - has a hard-cap on the maximum training time of 72 node-hours per job. If your dataset takes longer than that to converge, the job will time out. Rekognition did not complete the MS COCO job before its time limit was exceeded and, thus, failed our test. Limits Page
Google Cloud AutoML - there was a limit of 100MB for annotation upload. We were able to work around this by splitting the file into several chunks but the estimated budget for training MS COCO on Google Cloud AutoML was $6000. Sorry, but there's no way we're spending that on a blog post... Quotas and Limits Page
Azure Custom Vision - maxes out at 100,000 training images (COCO has over 200,000). Limits and Quotas Page
The Big Cloud AutoML Challenge - Pascal VOC
In order to compare the accuracy of AutoML vision solutions, we fell back to an older benchmark object detection task, the Pascal VOC 2012 Object Detection dataset.
The object detection task - Object detection challenges the computer to learn to draw bounding boxes around objects belonging to collection of object classes of interest.

The Pascal VOC 2012 dataset has 13,690 training images and 3,428 validation images across 20 object classes.
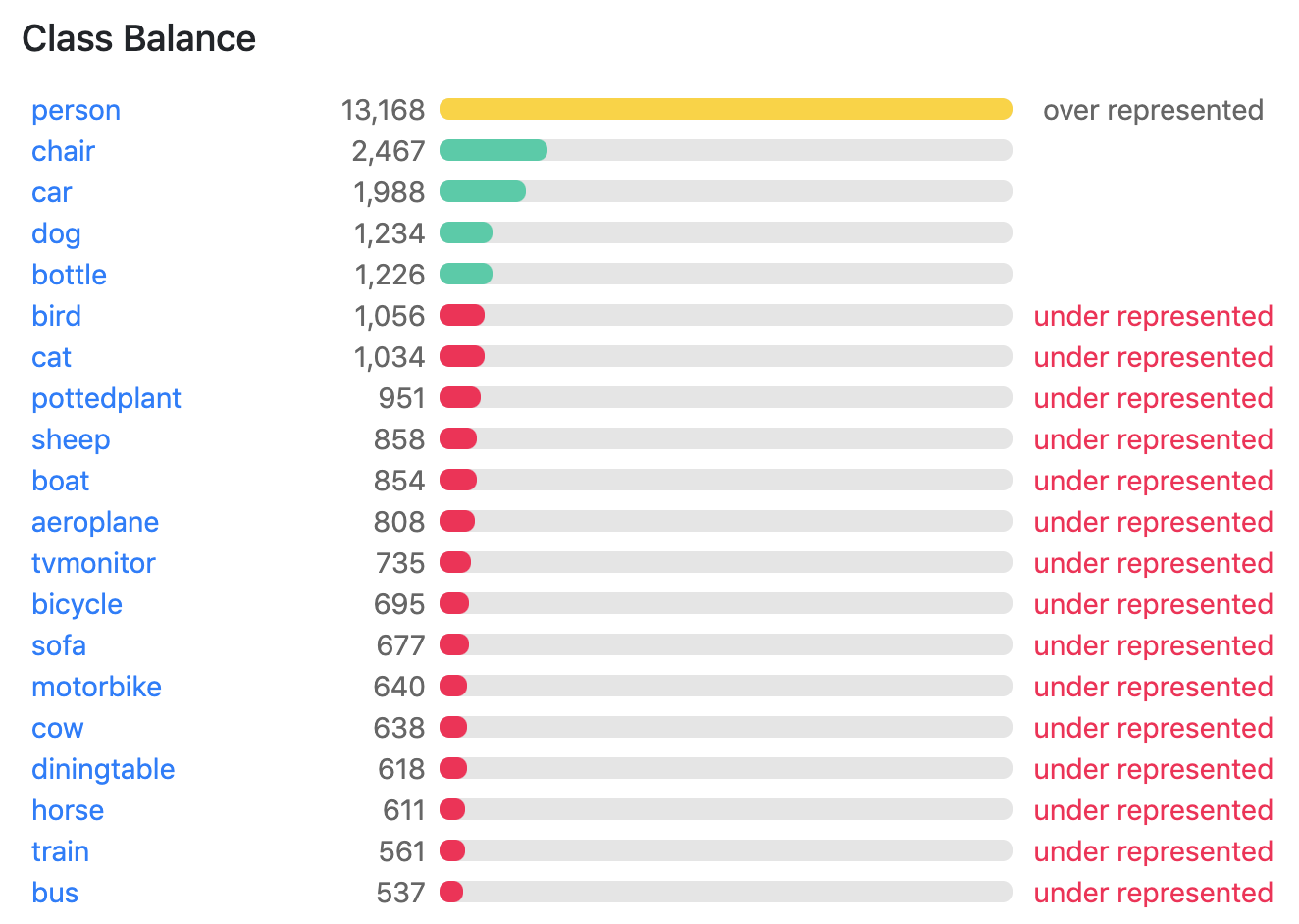
Pascal VOC withholds the dataset's test set so we evaluate the cloud platforms with their performance on the validation set.
Training Costs
Once you have loaded your dataset into Amazon Rekognition, Google Cloud AutoML Vision, or Azure Custom Vision, you are ready to train your model.
Training a model is a computationally intensive task, as the computer iterates through your dataset it will be optimizing millions of neural network parameters. To do this efficiently, the AutoML services will boot up GPU nodes.
Amazon Rekognition Custom Labels Training Cost - Training is started and runs until the model has reached maximum performance. You are unable to control how long training occurs for. Training costs $1/hr/instance and Amazon may provision multiple compute instances to train your model. So your training job may complete in two hours but you will be billed for more if more instances were started. Training can run for a maximum of 72 node hours. If it times out, your training cost is refunded. Be careful, you cannot stop training jobs that have started! Pricing Page.
Google Cloud AutoML Vision Training Cost - Google Cloud AutoML Vision trains their model with 8 nodes with Tesla V100 GPUs. Each node hour is $3.15/hr, so ~$25 per wall clock hour. AutoML Vision allows you the ability to start, stop, and resume model training, which can be nice to anticipate the costs before the training job has started. There is no limit to the amount of training time you can provision in Google Cloud AutoML Vision. Pricing Page.
Azure Custom Vision Training Cost - Azure Custom Vision is less verbose in explaining their training costs - it costs $20/compute hour, but the underlying hardware is undisclosed so it is unclear how this stacks up against the Google and Amazon price/performance. Pricing Page.
Training Time
It is hard to benchmark training costs without factoring in training time. Each service may be running a larger or smaller model architecture, and may have varying levels of training time software optimization.
When starting your training job, you have the ability to choose between large or compact models based on your downstream inference time needs in Azure and Google Cloud. Amazon Rekognition just provides one size fits all.
Smaller models train faster, infer faster, but perform less well.

In this face off, we optimized all models for accuracy (and tried to train with a similar budget).
Amazon Rekognition Custom Labels Training Time- Rekognition completed the training job on the Pascal VOC 2012 training set in 26 node hours, costing $26. To make a fair comparison, we sought to use this as our training budget across platforms.
Google Cloud AutoML Vision Training Time - To stick with with the Rekognition training cost baseline, we would need to use 9 node hours in Google Cloud AutoML Vision, but the minimum time allowed was 20 hours for our PascalVOC 2012 dataset, costing $60. The recommended training time was 1,080 node hours - which would have cost a whopping $3402. We chose to train for the minimum time allowed (which still cost >2x Rekognition).
Azure Custom Vision Training Time - Sticking with the Rekognition baseline, we provisioned 1 hour of training time for Azure Custom Vision, costing $20.
It is worth noting that Google Cloud AutoML Vision and Azure Custom Vision could have likely earned better evaluation performance with a larger training budget. Rekognition does not let you configure this tradeoff at all.
Reported Evaluation Metrics
Object detection systems are rated by the mean average precision metric, a measure of how well the model is detecting objects in test images that it has never seen.
Google Cloud AutoML Vision is the only platform that reports unbiased evaluation metrics. Azure Custom Vision and Rekognition are slanting their results in their favor. Here are the gory details.
As a primer, you may consider reading the blog regarding what is mean average precision in object detection or really getting into it with the mean average precision YouTube (by the way... have you subscribed to our YouTube channel yet? ಠ_ಠ).
Google Cloud AutoML Vision Evaluation Methodology - Google Cloud reports performance according to the mAP @ 0.5. This means the mean average precision metric calculated at 50% Intersection over Union.
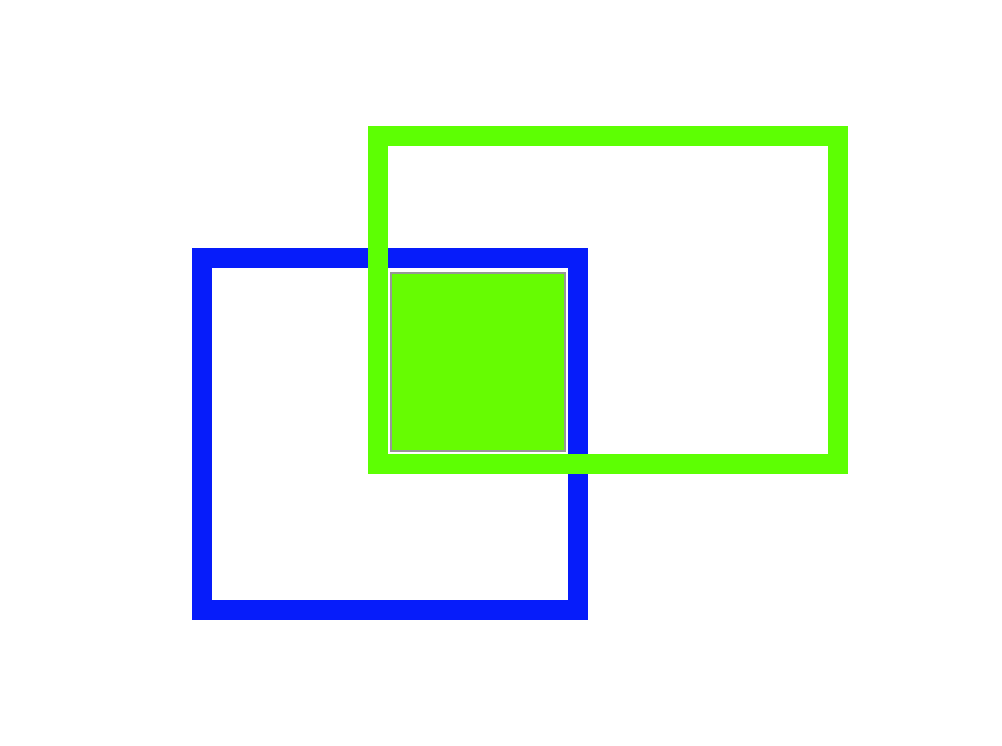
The Intersection over Union threshold means that the intersection of the predicted box and the ground truth box relative to their union must be at least 50%. The less the IoU the easier it is to make the mAP metric higher.
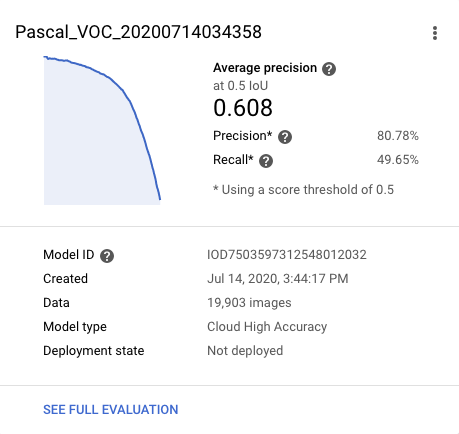
Amazon Rekognition Custom Labels Evaluation Methodology - Rekognition does not expose the IoU metric used for evaluation, which is questionable. Furthermore, they calculate an average precision metric based on a confidence threshold that is optimized per class label. This means for sheep they make a prediction if the model is more than 40% correct, but for person they make a prediction if the model is more than 80% correct. This is useful in an application setting, but for evaluation it is completely apples to oranges.
That said, here are the results for Rekognition:

In order to compare directly, we calculated a custom evaluation for Rekognition (details below).
Azure Custom Vision Evaluation Methodology - Azure commits the greatest harm of all big cloud evaluations by only evaluating on training images(?!) It is correct practice to create a held out testing set that the model has not seen for your evaluation. Otherwise, the model can just memorize patterns in the training set. Furthermore, the evaluation preset IoU for Azure Custom Vision is 30%, which is extremely lenient - they do let you adjust this with a slider.
That said, here are the results for Azure Custom Vision:
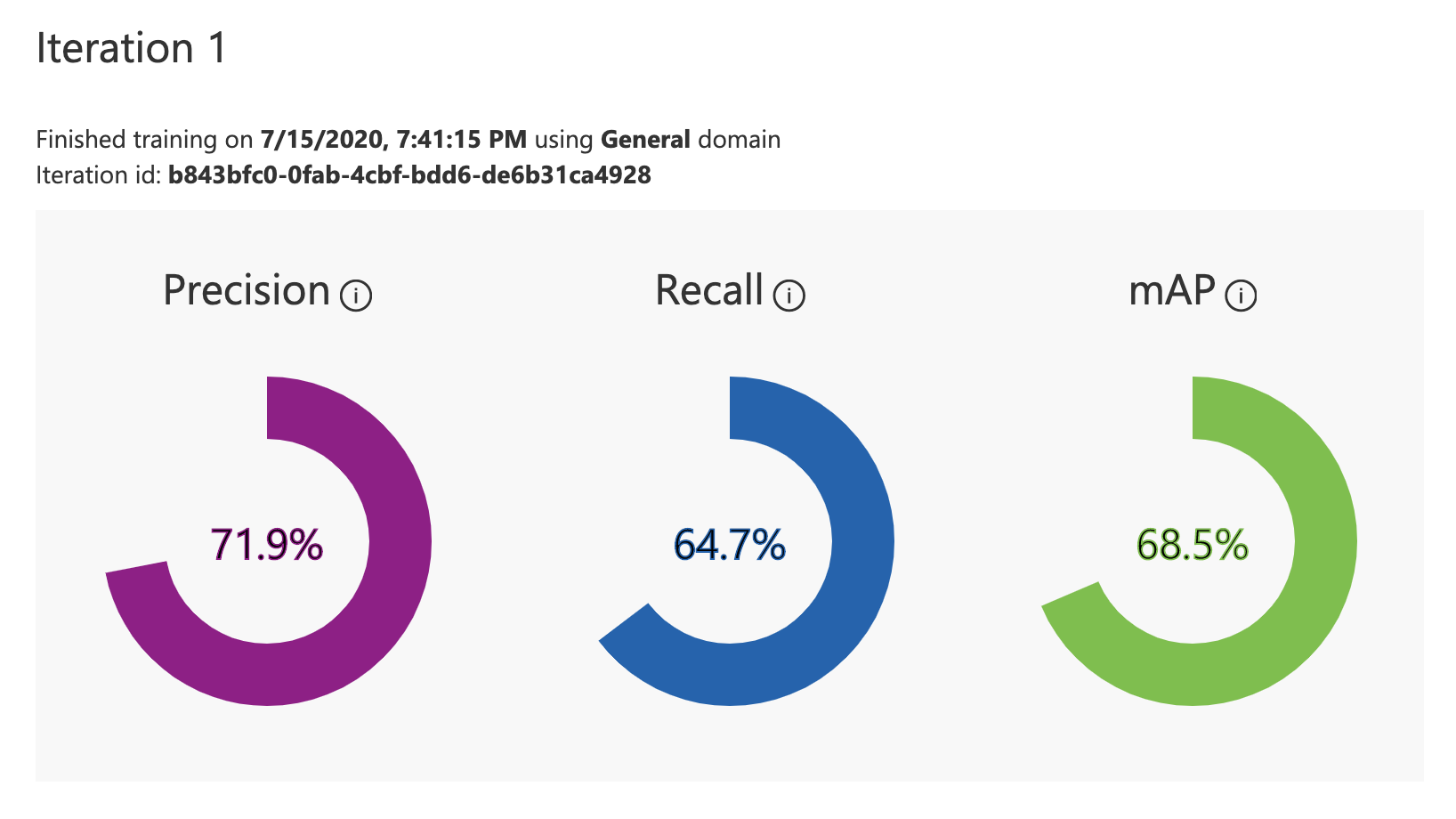
We also calculated our own evaluation metrics for Azure (details below).
Custom Head to Head Evaluation
Due to the confounding evaluation methodologies presented by Azure Custom Vision and Amazon Rekognition, we conducted a custom evaluation process to compare models head to head. To do so, we uploaded only the PASCAL VOC training set to Rekognition and Azure and held back the validation set.
Detected custom labels for Pascal_VOC_test_images/2009_003951_jpg.rf.84034d373c5e22f708af7c177e87e806.jpg
Detected custom labels for Pascal_VOC_test_images/2009_003965_jpg.rf.4c9750ed8c6383e30f087b5d8df232d2.jpg
Detected custom labels for Pascal_VOC_test_images/2009_003975_jpg.rf.e93d55d198402c969db470c56bbe1432.jpg
Detected custom labels for Pascal_VOC_test_images/2009_003976_jpg.rf.340afb150f459810fc40e336145daf29.jpg
Detected custom labels for Pascal_VOC_test_images/2009_003995_jpg.rf.244ac5855fba6469ff7a0b359bde0263.jpg
Detected custom labels for Pascal_VOC_test_images/2009_004004_jpg.rf.59277dc0388ff956b4fcbe76cf82543c.jpgazure detected objects for :/Users/wolf/Downloads/Pascal_VOC_2012/val-corrupted/2009_002445_jpg.rf.afc8bb54acd8e8b2a7ec6110fc11eb06.jpg
detection_time 0.36528491973876953
azure detected objects for :/Users/wolf/Downloads/Pascal_VOC_2012/val-corrupted/2011_006121_jpg.rf.08fba4e44cc22a4e81b45390b64995c2.jpg
detection_time 0.33763909339904785
azure detected objects for :/Users/wolf/Downloads/Pascal_VOC_2012/val-corrupted/2011_004730_jpg.rf.c083830630b8c51555a29db05a79e0f3.jpg
detection_time 0.4244537353515625
azure detected objects for :/Users/wolf/Downloads/Pascal_VOC_2012/val-corrupted/2010_003667_jpg.rf.9d48e35fe50f100e98b80daed42870a7.jpg
detection_time 0.4153890609741211Then, we held those model inferences up against the ground truth labels for a genuine mAP @0.5 IoU calculation. For code methodology see this repository.
Yielding the true evaluation for Rekognition:
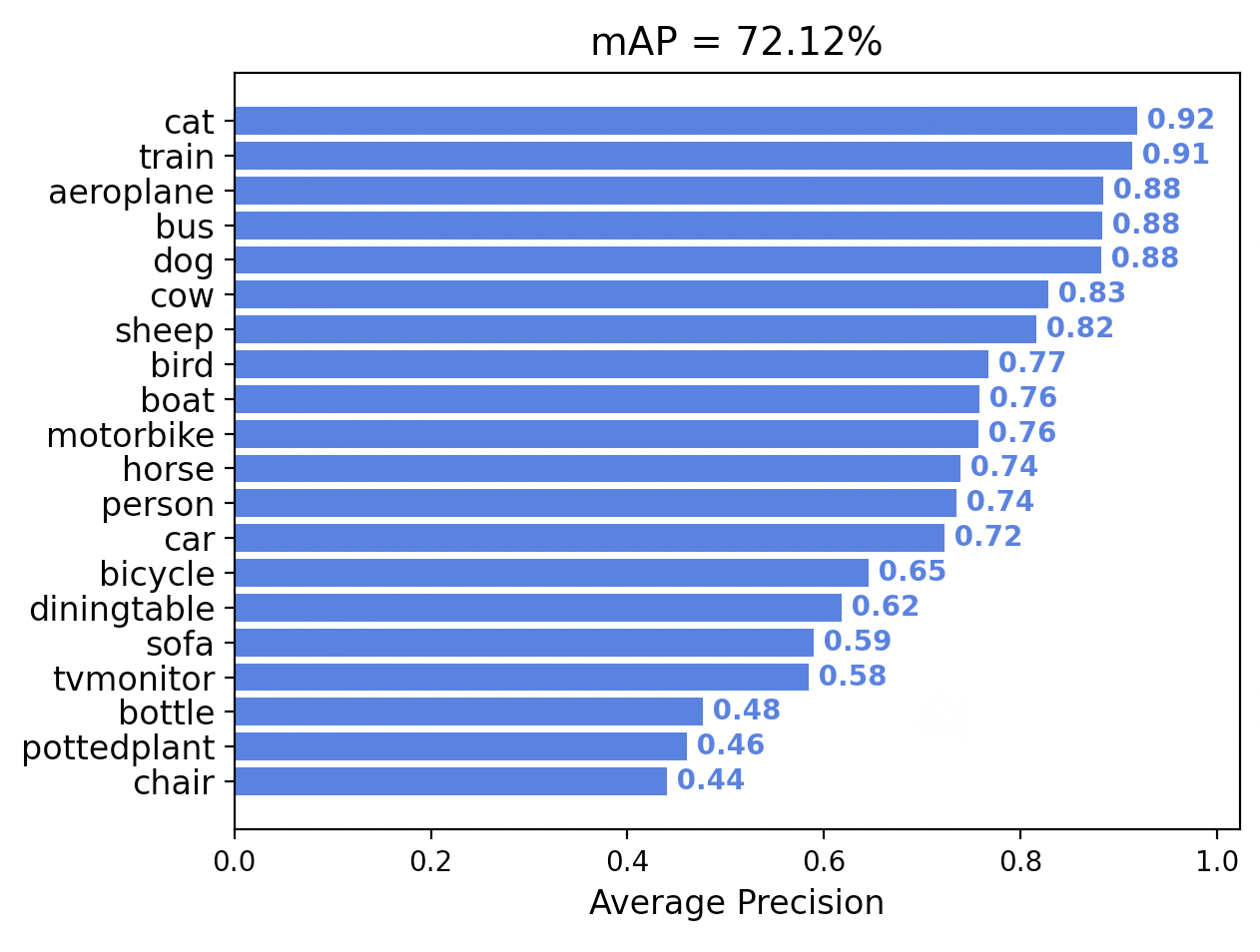
And the true evaluation for Azure Custom Vision:
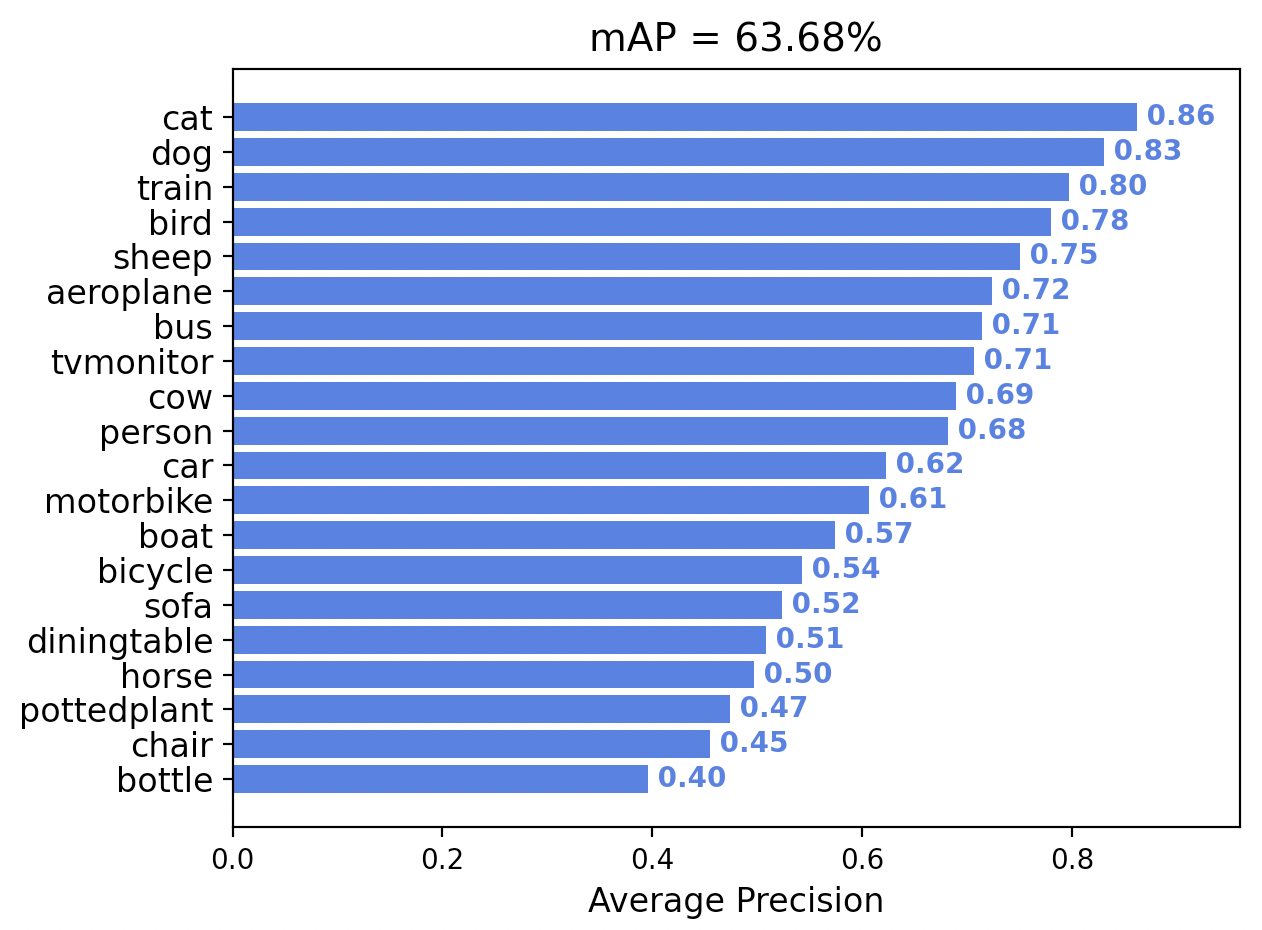
Given these new evaluations, we can see that the Amazon Rekognition model performs the best amongst the three big cloud providers on a shared object detection task, subject to similar training budgets.
Inference Time
One key consideration when selecting a model or service is how quickly you can receive predictions. Some use-cases (like identifying objects in a user-uploaded video) can be processed after the fact and parallelize well. Other use-cases (like next-gen augmented reality) need to run in real-time with low latency. Inference time can also be the difference between the ability to launch and application based on cloud vision, or not.
In our hands-on inference using the Amazon Rekognition Python Library and the Azure Custom Vision Python Library, we found that Amazon Rekognition inferences in ~2.1 seconds per image. Glacially slow... some small state of the art object detection models are inferencing at 400FPS.
We saw Azure Custom Vision inferencing anywhere from 400ms to 600ms, a pretty fast rate. (Azure also lets you train a smaller model and export your weights for on-device inference on a number of platform architectures like Apple CoreML, Tensorflow Lite, and ONNX.)
For Google Cloud AutoML Vision, the larger model used in this post infers at 800ms using the AutoML Python API.
Prediction results:
annotation_spec_id: "4359503130992312320"
image_object_detection {
bounding_box {
normalized_vertices {
x: 0.5619745850563049
y: 0.07531488686800003
}
normalized_vertices {
x: 0.7575701475143433
y: 0.3709263801574707
}
}
score: 0.973810613155365
}
display_name: "person"
prediction took : 0.8128330707550049Inference Costs
Most of the cost of an AutoML solution will accrue over the long-term after deploying your model for inference.
Amazon Rekognition Custom Labels Inference Cost - Rekognition charges $4/inference hour. Inference hours are based on how long it takes your custom model to process images and can depend on the size of the image as well as the complexity of the custom model - which you do not have much control over, but presumably more difficult tasks will utilize larger less computationally efficient models.
In our tests, we were able to do about 1 inference every 2 seconds. So if your instance was fully utilized, it would cost about $0.002/image.
If you can do batch inference, you can spin up instances at a prescribed time each day and spin them back done after you are finished. If you need on-demand inference, you will need to continue to pay the hourly rate to keep the compute resources running.
AWS Rekognition Custom Labels Pricing Page.
Google Cloud AutoML Vision Inference Cost - With on-demand prediction, you pay $1.82/hour per node (even if no predictions are made). They estimate 1.5 predictions can be made per second per node. Our tests yielded x predictions per second. So, if fully utilized, it would cost about $0.0003/image.
AutoML vision also supports batch prediction (where they scale up and down your compute resources for you) for $2.02/hour per node.
Google Cloud AutoML Pricing Page.
Azure Custom Vision Inference Cost - Costs for inference are $2 per 1000 transactions ($0.002/image). Charging per inference vs per hour is a huge advantage if you need on-demand predictions because it means you aren't paying for idle compute infrastructure.
If you only need to make predictions sporadically, Azure is worth a look. And the per-image cost is comparable to Rekognition for batch prediction.
Azure Custom Vision Pricing Page.
Benchmarking Against Open Source Object Detection
In order to provide context for the results that we have found for the three cloud AutoML services, we also benchmark performance against an open source object detection library, YOLOv5.
Our training evaluation is documented here in this Colab Notebook training YOLOv5 on Pascal VOC. You can replicate this on your own dataset with our YOLOv5 tutorial.
We trained the YOLOv5x model for 12 hours. Notably, it achieved 0.725 mAP on the Pascal VOC 2012 validation set, surpassing the set of object detectors trained in AWS Rekognition, Azure Custom Vision, and GCP Custom Vision. Furthermore, it trains much faster than its AutoML cousins.
Local inference is much much faster than hitting an AutoML API. Note, however, that inference is not a fair comparison, because most of the inference time of AutoML tools is wrapped up in the network overhead. GCP and Azure (but not Rekognition) offer the ability to export your trained weights for on device deployment.
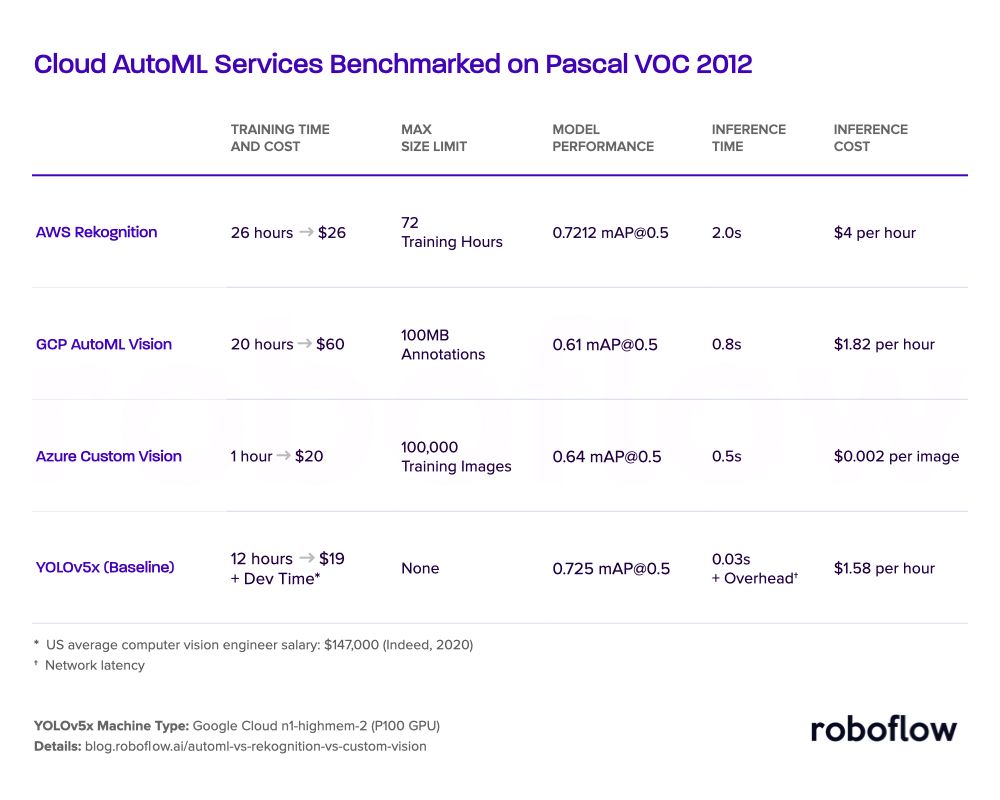
Replicate Our Benchmarking On Your Own Data
Here we provide details on how to run these benchmarks on your own custom computer vision task.
The easiest way is to use Roboflow for your data transformation and upload to the cloud platforms. Roboflow's Pro Tier has seamless integrations with all three cloud AutoML platforms. Otherwise, you will be spending days if not weeks parsing through disparate data formats, APIs, and formalities.
First sign up for an account. Then you can create a dataset.
The next step is to upload your data to Roboflow.
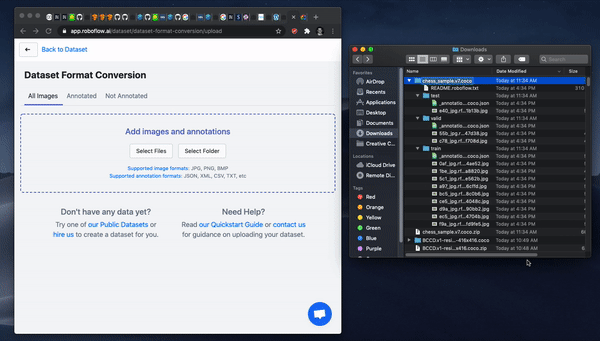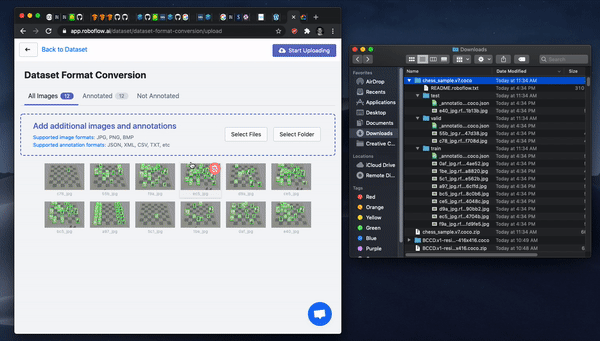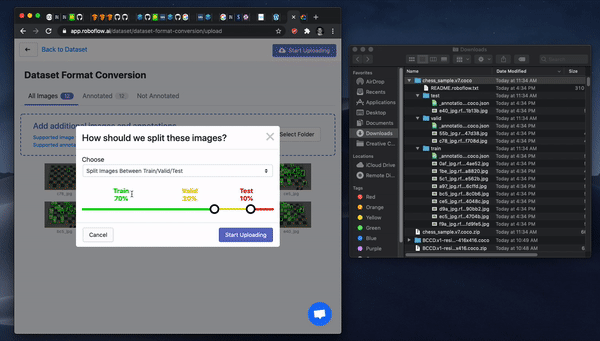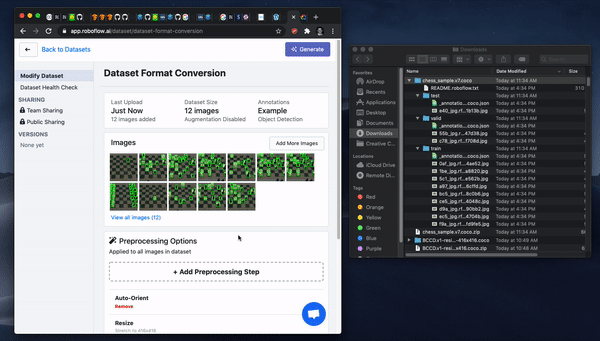
Next, pick or clear Preprocessing and Augmentation options for your dataset version and then Generate. After Generate you can export to the three big cloud providers.
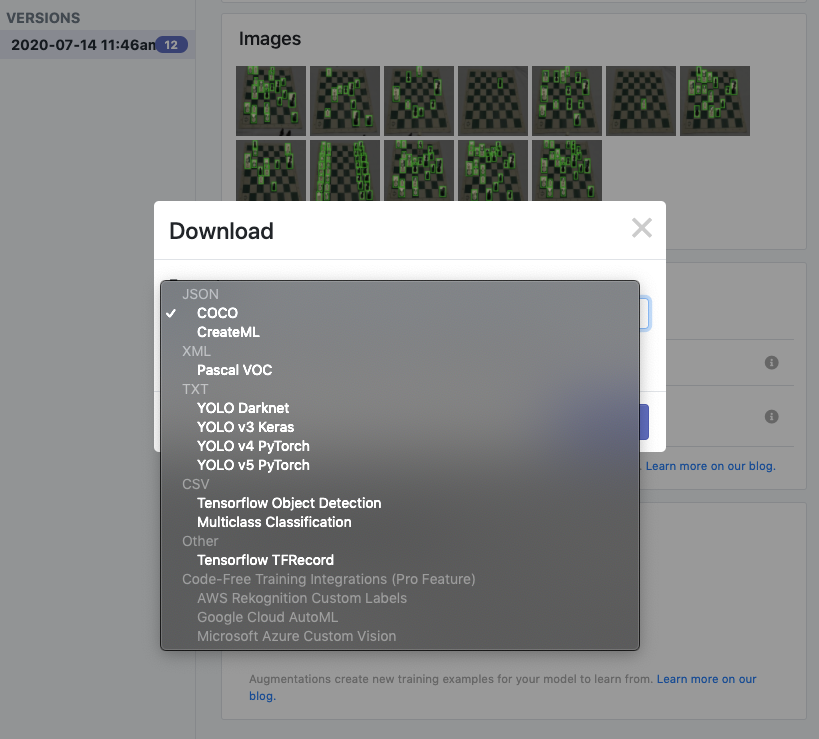
Once your data has entered the cloud providers vision service, you will be able to one click train to achieve benchmarks akin to the ones we have provided here in this blog post.
Conclusion and Recommendation
We have thoroughly vetted all three major cloud providers' no-code tools for training custom object detection models - and here are the results:
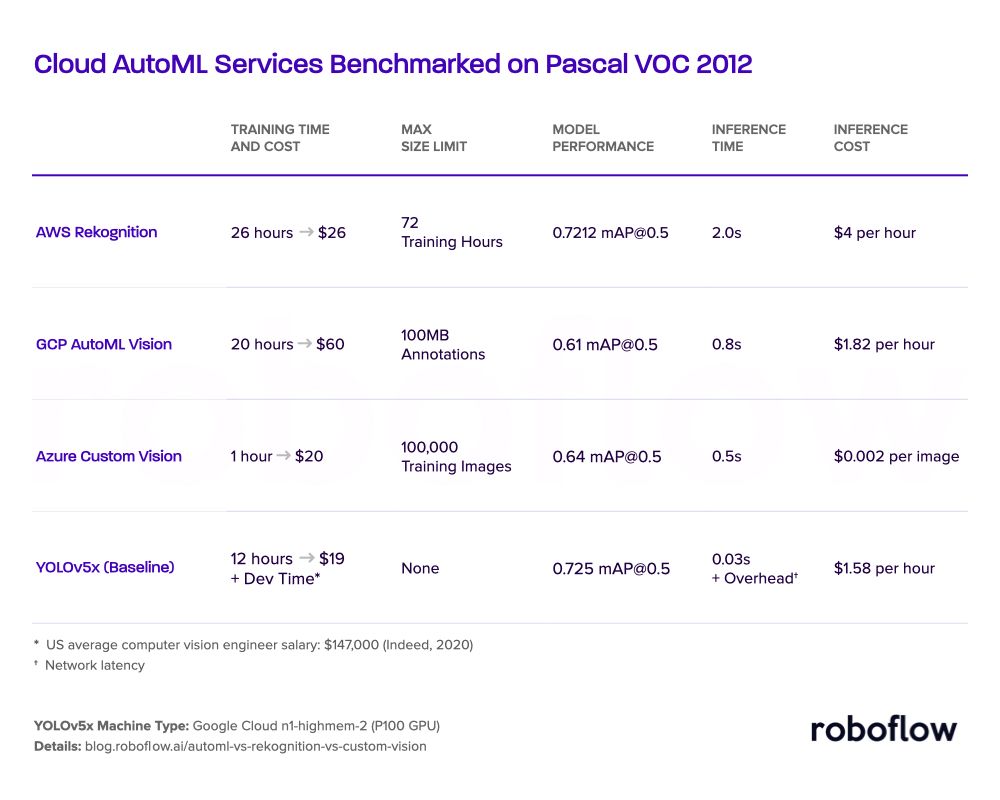
You have many factors to weigh when choosing an AutoML service, including training time and costs, model performance, and inference time and costs. From our exploration above, we recommend the following for different use cases:
Small Budget Seeking To Explore Computer Vision - Amazon Rekognition.
Large Budget Seeking Best Performance - Use Roboflow to test all three and see which one works best for your dataset and kick off long running training jobs in Azure and GCP.
Large Budget Seeking Sustainable Long Term Costs - GCP or Azure based on your inference workload (batchable: GCP, on-demand: Azure).
Need Realtime Inference - Export models from GCP Custom Vision or Azure AutoML. Consider training open source if you need better performance (at the expense of lots of development time).
The Best of All Worlds - try Roboflow Train to get a state of the art model deployed as an infinitely scalable API (or on your edge devices) for a fraction of the price.
We hope you enjoyed reading our thorough breakdown of the cloud AutoML solutions. Happy training!
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Jul 28, 2020). Benchmarking the Major Cloud Vision AutoML Tools. Roboflow Blog: https://blog.roboflow.com/automl-vs-rekognition-vs-custom-vision/