
(based on Microsoft COCO benchmarks)
The object detection space remains white hot with the recent publication of Scaled-YOLOv4, establishing a new state of the art in object detection.
Looking to train a Scaled-YOLOv4 model?
Skip this post and jump straight to our Scaled-YOLOv4 training tutorial. You'll have a trained model on your custom data in minutes.
In a David and Goliath fashion, authors Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao (more commonly known by their GitHub monikers, WongKinYiu and AlexyAB) have propelled the YOLOv4 model forward by efficiently scaling the network's design and scale, surpassing the previous state-of-the-art EfficientDet published earlier this year by the Google Research/Brain team.
WongKinYiu and AlexyAB scale the YOLO model up and down, beating prior benchmarks from previous small and large object detection models on both ends of the speed vs. accuracy frontier.
In this blog, we break down the research involved and the creation of Scaled-YOLOv4 and contextualize the advancement within the current object detection landscape - the most interesting twist being that the Scaled-YOLOv4 implementation is written in the YOLOv5 PyTorch framework.
What is Scaled-YOLOv4?
Scaled YOLOv4 is an object detection model based on YOLOv4. In Scaled YOLOv4, the depth of layers and the number of stages in the network backbone and neck are scaled to help the model attain better performance. Some layers in the Scaled YOLOv4 neural network are built using a CSP architecture, too, that reduces the amount of computational power necessary to train the network.
Let's talk a bit more about the background of YOLO and the problem it aims to solve: object detection. Then, we'll come back to talk about the architecture of the scaled YOLOv4 model.
Background on the Models
Object Detection
Object detection involves the task of teaching a computer to recognize objects in an image by drawing a box around them (called a bounding box), and correctly classifying that box among a limited scope of class labels. In the computer vision landscape today there are many custom object detectors that recognize objects from farm animals to phone defects.
The COCO Dataset
The COCO dataset is the gold standard benchmark for evaluating object detection models. The COCO (Common Objects in COntext) dataset contains over 120,000 images for training and testing, with 80 object class labels that are commonly observed in everyday life. Generally, if a model does well on the COCO dataset, it is believed that the model will generalize well to new custom domains - in the spirit of YOLO9000, for 9000 objects.

EfficientDet Models - Model Scaling
The EfficientDet family of models has been the preferred object detection models since it was published by the Google Research/Brain team in recent months. The most novel contribution in the EfficientDet paper was to think strategically about how to scale object detection models up and down.
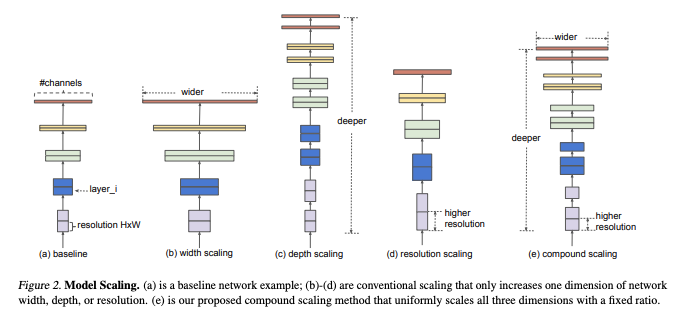
Object detection models can be scaled by using a large image input resolution, scaling the width of the convolutional network layer, scaling the depth of convolutional layers, and scaling all of these things together. The EfficientDet authors use search to find an optimal scaling threshold from EfficientDet-D0 to EfficientDet-D1, and use this setting to linearly scale up to the famed EfficientDet-D7.
YOLO Models
The YOLO family of models, written in the Darknet framework, has a rich history starting with Joseph Redmon (Github moniker pjreddie). Recently, the YOLO name and architecture have been picked up recently by a number of computer vision researchers.
YOLOv4 - Early this spring, AlexyAB formalized his fork of the Darknet repo, publishing the state-of-the-art YOLOv4 model. YOLOv4 was considered one of the best models for speed and accuracy performance, but did not top EfficientDet's largest model for overall accuracy on the COCO dataset.
YOLOv5 - Shortly after the release of YOLOv4, Glenn Jocher (Github moniker glenn-jocher) published his version of the YOLO model in PyTorch as YOLOv5. Comparing how YOLOv4 and YOLOv5 models stacked up against each other was nuanced – we wrote a bunch on the YOLOv4 vs. YOLOv5 debate here.
The YOLOv5 PyTorch training and architecture conversion was the most notable contribution, making YOLO easier than ever to train, speeding up training time 10x relative to Darknet.
One of the main reasons Scaled-YOLOv4 is implemented in the YOLOv5 PyTorch framework is, no doubt, the training routines. Glenn Jocher notably gets a shoutout in the Acknowledgments of Scaled-YOLOv4.
PP-YOLO - This summer, researchers at Baidu released their version of the YOLO architecture, PP-YOLO, surpassing YOLOv4 and YOLOv5. The network, written in the PaddlePaddle framework, performed well but has yet to gain much traction among practitioners.
But all of that's old news: Scaled-YOLOv4 is here and YOLOv4 has been fully CSP-ized!
Scaled-YOLOv4 Techniques
To scale the YOLOv4 model, the Scaled-YOLOv4 authors explore the following strategies.
In general, the Scaled-YOLOv4 authors are holding a few scaling concepts in balance as they are working on the construction of their models - image size, number of layers, and number of channels, while optimizing for model performance and inference speed. They consider a few CSP-ized CNN backbones in their network, ResNet, ResNeXt, and the traditional Darknet backbone.
"CSP-izing"
In the Scaled-YOLOv4 paper the authors often write that they "CSP-ized" a given portion of the network. To CSP-ize means to apply the concepts laid out in the Cross-Stage Partial Networks paper, written by WongKinYiu. The CSP is a new way to architect convolutional neural networks that saves on computation for various CNN networks - up to 50% (for the Darknet backbone in FLOPs).
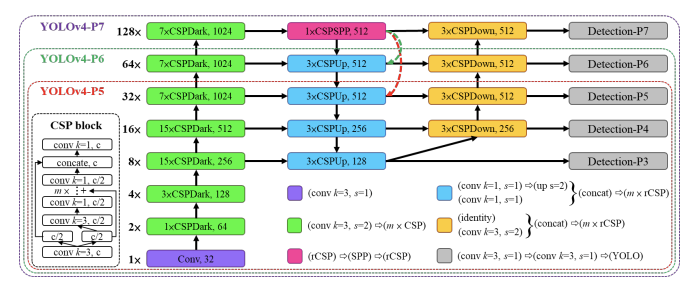
Scaling the YOLOv4-tiny model
The YOLOv4-tiny model had different considerations than the Scaled-YOLOv4 model because, on the edge, different constraints come into play, like memory bandwidth and memory access. For the YOLOv4-tiny's shallow CNN, the authors look to OSANet for its favorable computational complexity at little depth.
Scaling the YOLOv4-CSP models
To detect large objects in large images, the authors find that it is important to increase the depth and number of stages in in the CNN backbone and neck. (Increasing the width reportedly has little effect.) This allows them to first scale up input size and number of stages, and dynamically adjust width and depth according to realtime inference speed requirements. In addition to these scaling factors, the authors also adjust the configuration of their model's architecture in the paper.
Data Augmentations
Data augmentation in YOLOv4 was one of the key contributions to YOLOv4's impressive performance. In Scaled-YOLOv4, the authors train on a less augmented dataset first, then turn up the augmentations for fine-tuning at the end of training. They also use "Test Time Augmentations," where a number of augmentations are made on the test set. Predictions are then averaged across those test augmentations to further boost their non-real time results.
Scaled-YOLOv4 Results
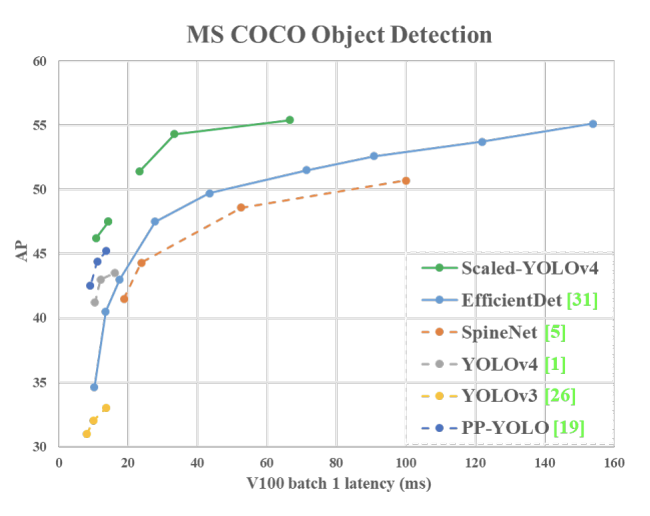
Evaluations show that the Scaled-YOLOv4 models set the standard for both large and small object detection models.
The language in the Scaled-YOLOv4 paper speaks for itself:
We can see that all scaled YOLOv4 models, including YOLOv4-CSP, YOLOv4-P5, YOLOv4-P6, YOLOv4- P7, are Pareto optimal on all indicators. When we compare YOLOv4-CSP with the same accuracy of EfficientDetD3 (47.5% vs 47.5%), the inference speed is 1.9 times [that of EfficientDetD3]. When YOLOv4-P5 is compared with EfficientDet-D5 with the same accuracy (51.4% vs 51.5%), the inference speed is 2.9 times [that of EfficientDet-D5]. The situation is similar to the comparisons between YOLOv4-P6 vs EfficientDet-D7 (54.3% vs 53.7%) and YOLOv4-P7 vs EfficientDet-D7x (55.4% vs 55.1%). In both cases, YOLOv4-P6 and YOLOv4-P7 are, respectively, 3.7 times and 2.3 times faster in terms of inference speed.
And notably for YOLOv4-tiny:
In addition, if one uses TensorRT FP16 to run YOLOv4-tiny on general GPU RTX 2080ti, when the batch size respectively equals to 1 and 4, the respective frame rate can reach 773fps and 1774fps, which is extremely fast.
If you want to push the ceiling for performance or speed for your object detection task, Scaled-YOLOv4 is the new place to look.
The authors provide myriad ablation studies and many more research insights than we have written here. Learn more in the paper!
How to Train Scaled-YOLOv4 on Your Own Task
How to Train YOLOv4-tiny
If you want to train an object detector that is lightning fast and can be deployed on edge devices, then you can train it on YOLOv4-tiny. We have written a nice guide here on how to train and deploy YOLOv4-tiny on your custom data to detect your custom objects.
Note: YOLOv4-tiny is implemented in the Darknet framework, not PyTorch.
How to Train YOLOv4-CSP/P5/P6/P7
If you want to use a medium sized model, you'll want to use YOLOv4-CSP, and this can be a good place to start iterating on the Scaled-YOLOv4 models.
If you want to scale up from there for ultimate accuracy, the YOLOv4-P5/P6/P7 models will be of use.
Here is the Scaled-YOLOv4 repo, though you will notice that WongKinYiu has provided it there predominantly for research replication purposes and there are not many instructions for training on your own dataset. To train on your own data, our guide on training YOLOv5 in PyTorch on custom data will be useful, as it is a very similar training procedure.
As is customary with new models, we expect that the implementation of this network on custom tasks will become easier with time and development – including work we will be doing here at Roboflow. Stay tuned!
Scaled-YOLOv4 Custom Training
Train Scaled-YOLOv4 on custom objects. Scaled-YOLOv4 is the new state of the art in object detection and you can easily apply it on your own task with this tutorial and Colab Notebook.
Conclusion
The computer vision landscape is more exciting than ever before. In 2020 alone, a new standard for object detection (as measured on the COCO dataset) has been set four times.
Faster and more accurate models are making tasks that were marginally outside the reach for vision developers more achievable, whether it is in providing the required accuracy for a given task or making it less expensive to deploy models to the edge.
Unlike many of the state-of-the-art AI models today, Scaled-YOLOv4 sets the high water mark for object detection through the work of a couple of impassioned researchers on a few cloud GPUs - not a major institution with a huge budget for compute resources. This is a huge win for the future of open source AI technology.
As always, happy training!