
The YOLO v4 model is currently one of the best architectures to use to train a custom object detector, and the capabilities of the Darknet repository are vast. In this post, we discuss and implement ten advanced tactics in YOLO v4 so you can build the best object detection model from your custom dataset.
Note: this discussion assumes that you have already trained YOLO v4. To get started, check out our guide on training YOLOv4. The advanced tactics here will build from that basic training flow.
YOLO v4 Advanced Tactics RoadMap:
- Gather More Data
- Image Preprocessing and Augmentation
- Image Input Resolution Size
- When to Use Pretrained Weights
- Choosing a Model Size and Architecture
- Picking Up From a Previous Training Run
- Choosing the Best Model after Training
- Track Your Model Evaluations
- Exporting Your Model
- Optimizing Inference Times
Resources in this tutorial:
- A review of the YOLO v4 model
- Public Datasets on Roboflow
- YOLO v4 Training Notebook - We make comments from this notebook. Note: this is a fork of the Darknet repository. We fork to maintain consistency, though you may need to make slight changes if you pull the most recent Darknet.
1) Gather More Data
The best way to improve an object detection model is to gather more representative data, and YOLO v4 does not escape from this fact. As Tesla's Senior Director of AI, Andrej Karpathy puts it when explaining how Tesla teaches cars to stop:
"Your dataset is alive, and your labeling instructions are changing all the time. You need to curate and change your dataset all the time."
2) YOLOv4 Image Preprocessing and Augmentation
Gathering and labeling more data is costly. Luckily, there are several ways to improve the scope and size of your training set through augmentation. First, you can annotate images directly in Roboflow – making things faster for you – and we've developed best practices on labeling images.
The YOLO v4 training pipeline does augmentations automatically (see this article on data augmentation in YOLO v4) but you may want to consider adding additional augmentation in Roboflow.
Image preprocessing is also another important step to make sure that your images are the correct image resolution size and you have standardized aspects such as class ontology, grayscale and contrast.
The most important preprocessing decision to make is image input resolution.
3) YOLOv4 Input Resolution Size
The input resolution determines the number of pixels that will be passed into the model to learn and predict from. A large pixel resolution improves accuracy, but trades off with slower training and inference time. Larger pixel resolution can help your model detect small objects.
YOLO model pixel resolution must be a multiple of 32. A standard resolution size to choose is 416x416.
If you are managing your dataset in Roboflow, you can select your dataset input resolution size with the resize preprocessing step.
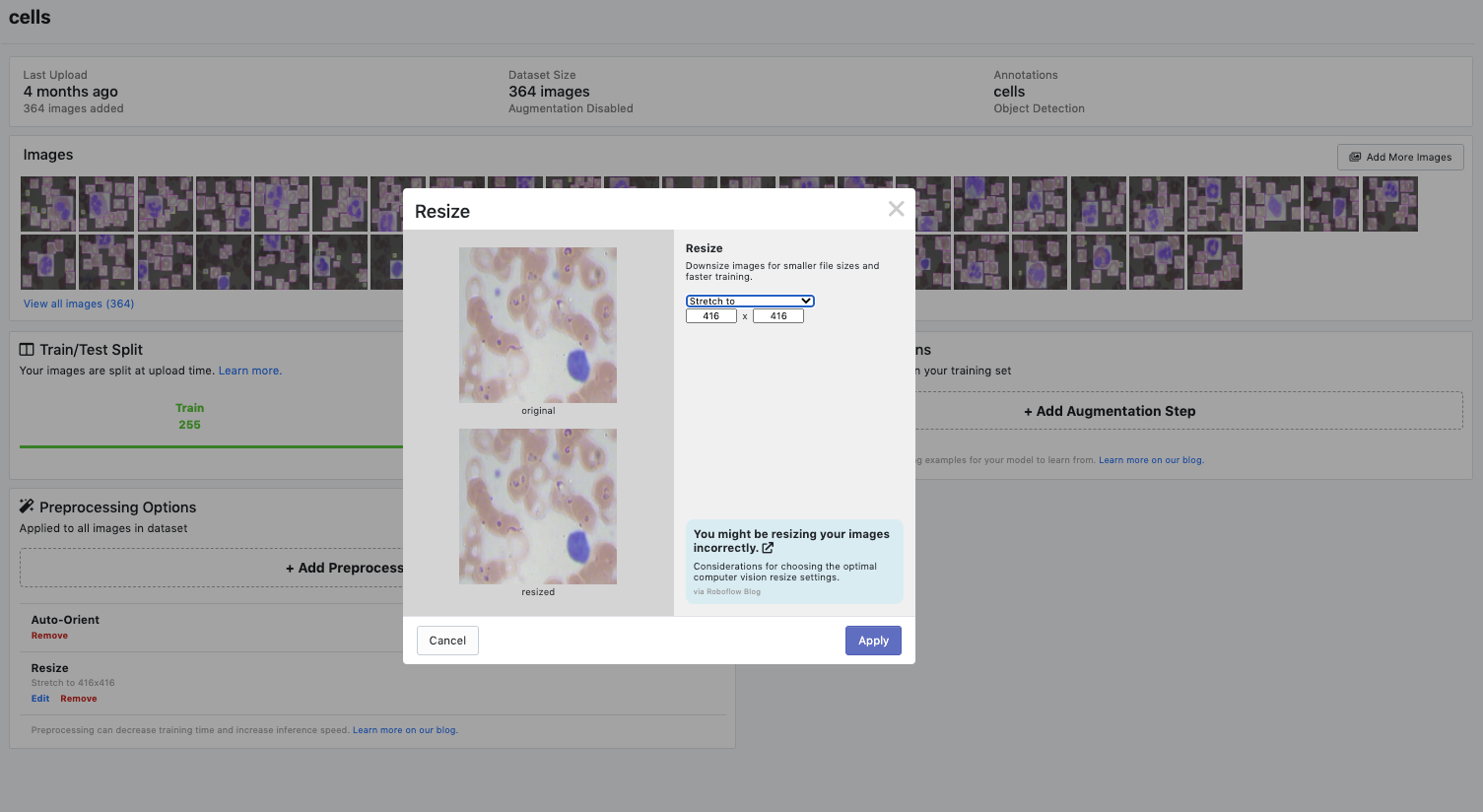
Important: To make sure your input resolution size flows through to your YOLOv4 model you must adjust the model configuration file. In the cfg folder where you specify your model configuration change width and height here.
[net]
batch=64
subdivisions=8
# Training
#width=512
#height=512
width=608
height=608
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
Change width and height in the YOLOv4 model cfg file
4) When to Use Pretrained YOLOv4 Weights
To start training on YOLOv4, we typically download pretrained weights:
!wget
https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.conv.137And start from this pretrained checkpoint during training:
!./darknet detector train data/obj.data cfg/custom-yolov4-detector.cfg yolov4.conv.137 -dont_show -map
These weights have been pretrained on the COCO dataset, which includes common objects like people, bikes, and cars. It is generally a good idea to start from pretrained weights, especially if you believe your objects are similar to the objects in COCO.
However, if your task is significantly difficult than COCO (aerial, document, etc.), you may benefit from starting your training from scratch.
!./darknet detector train data/obj.data cfg/custom-yolov4-detector.cfg -dont_show -mapAnd of course, it is always advantageous to experiment with both, and look empirically to see what works best for your model.
5) Choosing a Model Size and Architecture
YOLOv4 comes in two flavors YOLOv4 and YOLOv4-tiny.
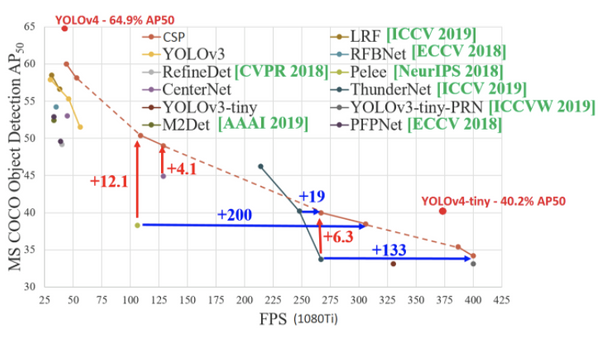
If inference speed is your end goal, the smaller model may be of interest. And it may be possible to pick up accuracy drops by improving your dataset.
Shifting from YOLOv4 to YOLOv4-tiny is a matter of model configuration. You can experiment with intermediary configurations to construct a custom YOLO model. To do so, look in the cfg folder, and experiment with changing the networks architecture and layers. One thing to consider may be to implement custom anchor boxes, if your object shapes are vastly different than the COCO dataset. This is a very advanced tactic!
[yolo]
mask = 0,1,2
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.2
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=5
6) Picking Up From a Previous YOLOv4 Training Run
It can take a while to train your YOLOv4 model in the Darknet framework. It is important to save your model periodically. You can always resume training by invoking training with the previous training runs weights like so:
!./darknet detector train data/obj.data cfg/custom-yolov4-detector.cfg [YOUR WEIGHTS HERE] -dont_show -map
Be sure that the weights were trained with the same configuration file and trained under the same version of the Darknet framework!
Just like pretrained weights, you can pick up from previous training runs and apply your model's learnings from other datasets to new datasets.
7) Choosing the Best YOLOv4 Model after Training
Darknet model weights are saved in the backup folder and automatically save every 1000 iterations. Darknet will automatically save the best model for you with extension _best.weights. This is based on performance on your validation set. Darknet will also save the last weights from your training run with extension _last.weights.
8) Track Your YOLOv4 Model Evaluations
As you are working through various tweaks in your dataset and in YOLOv4 modeling, it can be useful to track your results, so you can see what combination of techniques works best on your dataset.
Darknet will output a mean average precision score, which is the primary metric to track as you decide which model is working best on your data. Another important metric to consider is the speed of inference.
9) Exporting Your YOLOv4 Model
Once you have a trained model it will be in a Darknet .weights format. You will likely want to convert it to a new format for deployment.
YOLOv4 Darknet model conversion guides:
10) Optimizing YOLOv4 Inference Times
The primary way to speed up the inference time of your model is to use a smaller model like YOLOv4-tiny. Further inference time improvements are possible through hardware selection, such as GPU or inferring with OpenVino on the Intel VPU. For GPU inference, it is advisable to deploy with the YOLOv4 TensorRT framework.
Conclusion
Congratulations! Now you have ten new advanced tactics to get the most out of YOLO v4 for creating an object detector to model your custom dataset.
Want to checkout the newest YOLOv4 in PyTorch? Checkout Scaled-YOLOv4.
As always, happy training.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Nov 13, 2020). YOLOv4 - Ten Tactics to Build a Better Model. Roboflow Blog: https://blog.roboflow.com/yolov4-tactics/