
What if you could retrieve the location of an object in an image without training a custom model? That is the task that zero-shot object detection models aim to solve. Zero-shot detection models are trained on large datasets to identify a vast range of objects, allowing you to localize objects without training a custom model.
In this guide, we are going to talk about what zero-shot object detection is, the applications of these types of models, popular zero-shot detection models, and how you can use zero-shot detection. Without further ado, let's get started!
What is Zero-Shot Object Detection?
Zero-shot object detection models identify the location of objects in images. Zero-shot object detection models accept one or more text prompts (i.e. "car") and will aim to identify the location of all the objects of interest you have listed.
Zero-shot object detection models are designed to identify a wide range of images, examples of which include Grounding DINO, OWL-ViT, and OWLv2.
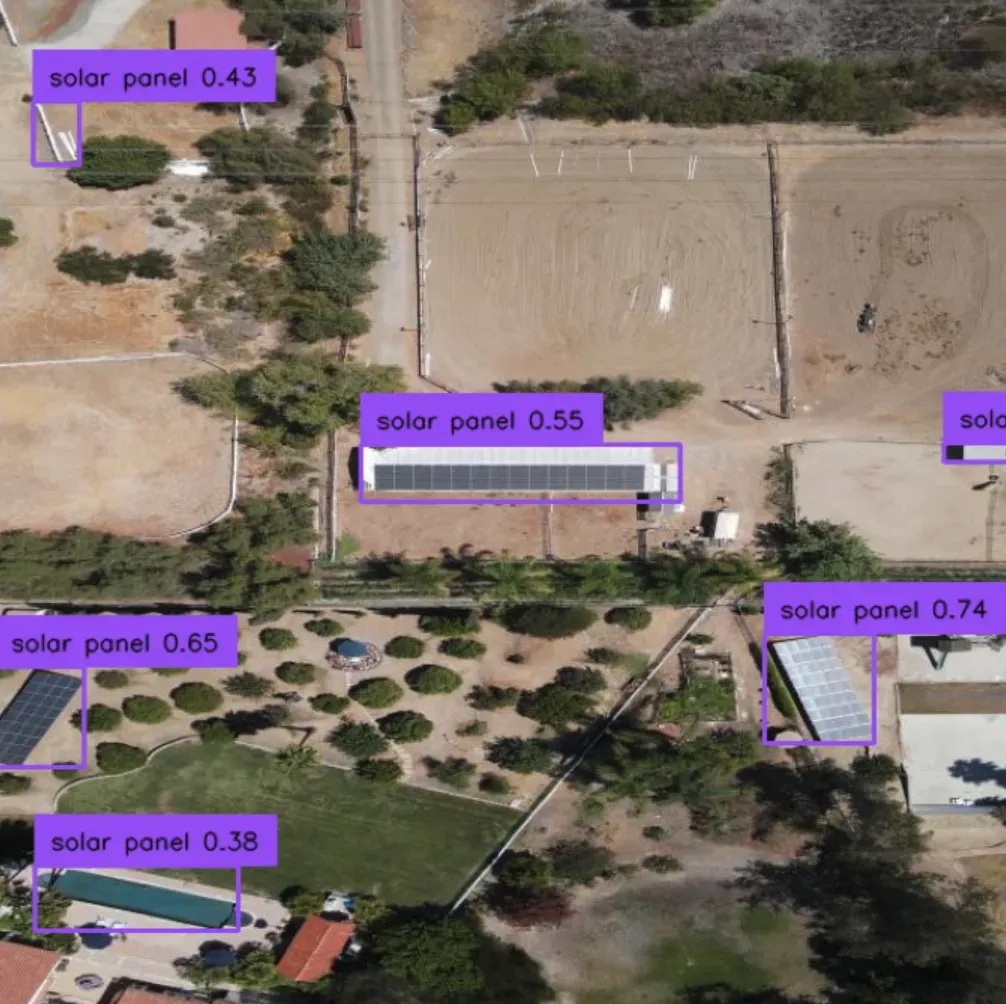
Let's use Grounding DINO to identify solar panels. We will use the text prompt "solar panel":
The following image shows using Grounding DINO without a prompt next to Grounding DINO with the prompt "dogs tail":

In all cases above, Grounding DINO was able to successfully identify objects of interest.
Popular Zero-Shot Object Detection Models
Throughout this post, we have mentioned a few of the many zero-shot detection models available today. Here are a few that you can use:
- Grounding DINO
- OWLv2
- DETIC (can detect 21k classes)
There are also classification models that can be used to refine predictions from models. For example, you can use a model like DETIC to detect a general object (i.e. a computer mouse) then a classification model like OpenAI's GPT-4V model to refine the prediction (i.e. the mouse is from Logitech vs. another brand).
Zero-Shot Object Detection Applications
Although Grounding DINO and other zero-shot models are powerful, they are large and require significant compute resources to run compared to fine-tuned models. As a result, many state-of-the-art zero-shot models are impractical to run at large scale, in real-time, or on the edge.
Zero-shot models can be run across images for analysis, or you can use zero-shot models to automatically label data for use in training a smaller, fine-tuned model. The Autodistill framework enables you to do this in a few lines of code. You can use a model like Grounding DINO or OWLv2 to label data, then train a smaller model like RF-DETR on your labeled dataset. The resultant model is suitable for real-time edge deployment, unlike large zero-shot models.
How to Use Zero-Shot Object Detection Models
Let's talk through how to use a zero-shot object detection model. For this guide, we will use Grounding DINO through Autodistill, an ecosystem for using foundation and zero-shot models. Note that inference speeds with Grounding DINO will likely be ~1 FPS on devices with CUDA-enabled GPUs.
Grounding DINO is most effective at identifying common objects (i.e. cars, people, dogs, etc.). But, the model is less effective at identifying uncommon objects (i.e. a specific type of car, a specific person, a specific dog, etc.).
To get started, install the following dependencies:
pip install autodistill autodistill-grounding-dinoThen, create a new Python file and add the following code:
from autodistill_grounding_dino import GroundingDINO
from autodistill.detection import CaptionOntology
from autodistill.utils import plot
import cv2
base_model = GroundingDINO(ontology=CaptionOntology({"deer": "deer"}))
results = base_model.predict("image.jpg")
plot(
image = cv2.imread("image.jpg"), detections = results, classes = ["deer"]
)In this code, we load Grounding DINO with an ontology. This ontology describes the classes we want to identify and how we want to save each class. In this case, we use the ontology:
"deer": "deer"The first value is the prompt that will be sent to Grounding DINO. The second is the class name we will record. Then, we display a prediction. Here is an example of our script running on an image:

Grounding DINO successfully labeled our image with 0, the class associated with the deer (deer is the first class in the list we created).
We can also label a whole folder of images. To do so, add the following line of code to your script:
base_model.label("./context_images", extension=".jpeg")
This will label all images in a folder called "context_images" and save the results to a folder called "context_images_labeled". Learn more about labeling data for use in training fine-tuned object detection models using large zero-shot models.
Conclusion
Zero-shot models are a new frontier in the world of vision. These models have a vast amount of knowledge and, as a result, do not require fine-tuning to use. However, zero-shot models are slow. Thus, we recommend using zero-shot models to train a fine-tuned model that can run faster and on the edge.
Zero-shot detection models cannot identify every object. For those use cases, training a fine-tuned model is the only available option. Furthermore, zero-shot models may not perform well on your data; if that is the case, training a fine-tuned model, using the model to label where possible, is recommended.
You can also use zero-shot detection for object tracking. Read our guide on object tracking with zero-shot models.
Today, there are zero-shot models available for classification, object detection, and segmentation. As the years progress, zero-shot models will likely continue to improve, enabling you to identify more objects without training a fine-tuned model.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Nov 16, 2023). What is Zero-Shot Object Detection?. Roboflow Blog: https://blog.roboflow.com/what-is-zero-shot-object-detection/