
YOLOv7 advances real-time object detection by introducing Extended Efficient Layer Aggregation Networks (E-ELAN) for better gradient flow, compound model scaling that preserves architecture structure, and auxiliary head coarse-to-fine training to improve accuracy without adding inference cost. This breakdown explains each architectural contribution from authors WongKinYiu and AlexeyAB, covering how YOLOv7 improves on YOLOv5 in both speed and accuracy, and what the multiple model variants (YOLOv7, YOLOv7-tiny, YOLOv7-W6) are each suited for.
Realtime object detection advances with the release of YOLOv7, the latest iteration in the life cycle of YOLO models. YOLOv7 infers faster and with greater accuracy than its previous versions (i.e. YOLOv5), pushing the state of the art in object detection to new heights.
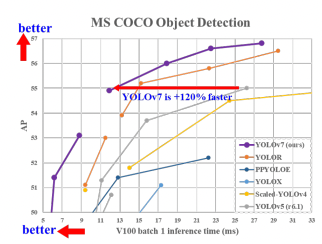
In this post, we break down the internals of how YOLOv7 works and the novel research involved in its construction. We'll then get on to a video about how you can train a model using YOLOv7 with a custom dataset and Roboflow.
Jump to Training YOLOv7
If you are more interested in the practical side of YOLOv7, you can skip this breakdown post and jump straight to our YOLOv7 Tutorial. You can train a YOLOv7 model on your custom data in minutes.
What is YOLOv7?
The YOLO (You Only Look Once) v7 model is the latest in the family of YOLO models. YOLO models are single stage object detectors. In a YOLO model, image frames are featurized through a backbone. These features are combined and mixed in the neck, and then they are passed along to the head of the network YOLO predicts the locations and classes of objects around which bounding boxes should be drawn.
YOLO conducts a post-processing via non-maximum supression (NMS) to arrive at its final prediction.
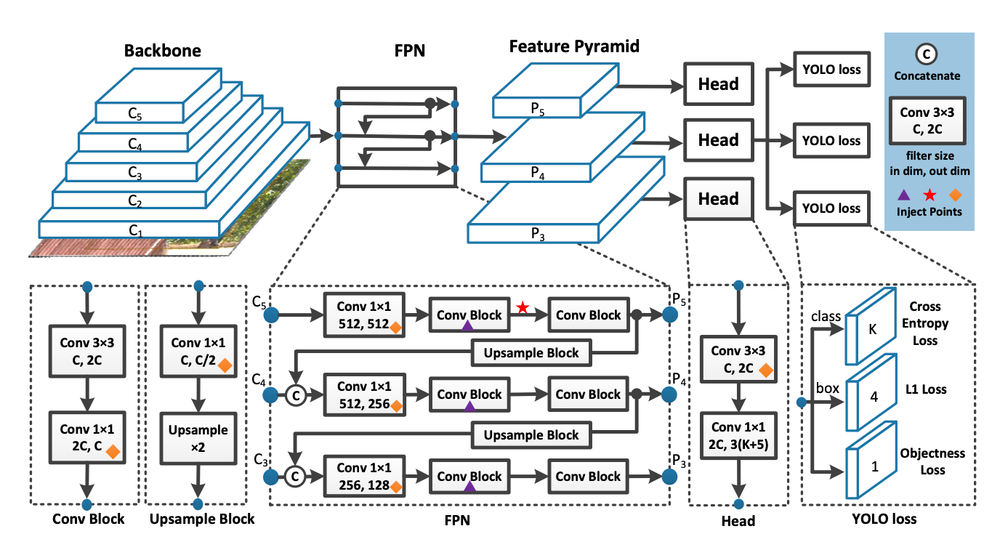
In the beginning, YOLO models were used widely by the computer vision and machine learning communities for modeling object detection because they were small, nimble, and trainable on a single GPU. This is the opposite of the giant transformer architectures coming out of the leading labs in big tech which, while effective, are more difficult to run on consumer hardware.
Since their introduction in 2015, YOLO models have continued to proliferate in the industry. The small architecture allows new ML engineers to get up to speed quickly when learning about YOLO and the realtime inference speed allows practitioners to allocate minimal hardware compute to power their applications.

The YOLOv7 Authors
The YOLO v7 model was authored by WongKinYiu and Alexey Bochkovskiy (AlexeyAB).
AlexeyAB took up the YOLO torch from the original author, Joseph Redmon, when Redmon quit the Computer Vision (CV) industry due to ethical concerns. AlexeyAB maintained his fork of YOLOv3 for a while before releasing YOLOv4, an upgrade on the previous model.
WongKinYiu entered the CV research stage with a Cross Stage Partial networks, which allowed YOLOv4 and YOLOv5 to build more efficient backbones. From there, WongKinYiu steamrolled ahead making a large contribution to the YOLO family of research with Scaled-YOLOv4. This model introduces efficient scaling of YOLOv4 CSPs to hit a COCO state of the art mAP.
Scaled-YOLOv4 was the first paper AlexeyAB and WongKinYiu collaborated on, and in doing so they ported YOLOv5 PyTorch implementations over to their line of repositories. This was a more convenient place to research than their traditional YOLOv4 Darknet repository, which already had a defined scope.
After that, WongKinYiu released YOLOR, which introduced new methods of tracking implicit knowledge in tandem with explicit knowledge in neural networks. The video below is a walk given by Alexey Bochkovskiy on real-time object detection with three models in the YOLO family:
WongKinYiu and AlexeyAB are back with the introduction of YOLOv7, quickly following the release of YOLOv6 from the Meituan Technical Team.
What Makes YOLOv7 Different?
The YOLOv7 authors sought to set the state of the art in object detection by creating a network architecture that would predict bounding boxes more accurately than its peers at similar inference speeds.
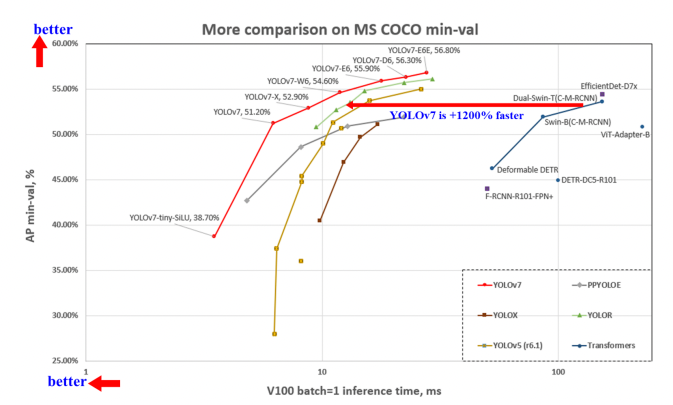
In order to achieve these results, the YOLOv7 authors made a number of changes to the YOLO network and training routines. Below, we're going to talk about three notable contributions to the field of computer vision research that were made in the YOLOv7 paper.
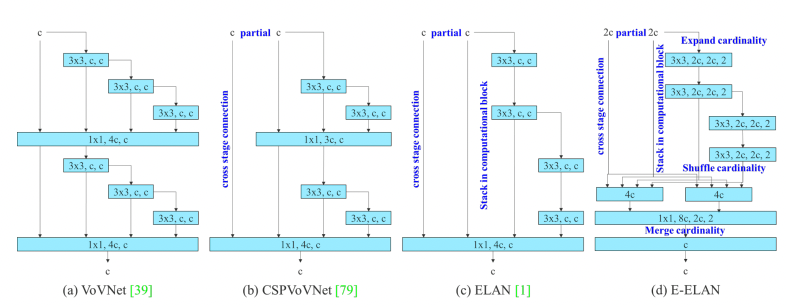
Extended Efficient Layer Aggregation
The efficiency of the YOLO networks convolutional layers in the backbone is essential to efficient inference speed. WongKinYiu started down the path of maximal layer efficiency with Cross Stage Partial Networks.
In YOLOv7, the authors build on research that has happened on this topic, keeping in mind the amount of memory it takes to keep layers in memory along with the distance that it takes a gradient to back-propagate through the layers. The shorter the gradient, the more powerfully their network will be able to learn. The final layer aggregation they choose is E-ELAN, an extend version of the ELAN computational block.
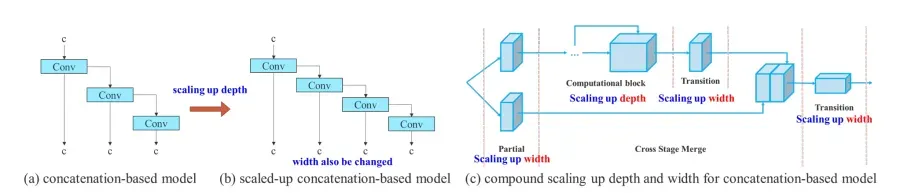
Model Scaling Techniques
Object detection models are typically released in a series of models, scaling up and down in size, because different applications require different levels of accuracy and inference speeds.
Typically, object detection models consider the depth of the network, the width of the network, and the resolution that the network is trained on. In YOLOv7 the authors scale the network depth and width in concert while concatenating layers together. Ablation studies show that this technique keep the model architecture optimal while scaling for different sizes.
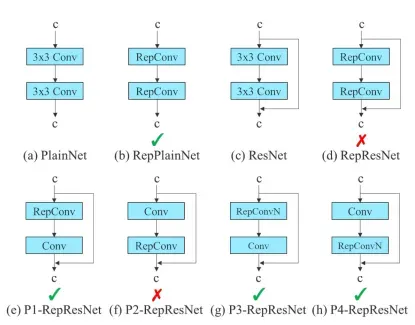
Re-parameterization Planning
Re-parameterization techniques involve averaging a set of model weights to create a model that is more robust to general patterns that it is trying to model. In research, there has been a recent focus on module level re-parameterization where piece of the network have their own re-parameterization strategies.
The YOLOv7 authors use gradient flow propagation paths to see which modules in the network should use re-parameterization strategies and which should not.
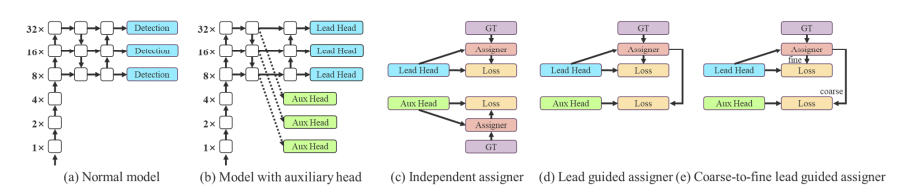
Auxiliary Head Coarse-to-Fine
The YOLO network head makes the final predictions for the network, but since it is so far downstream in the network, it can be advantageous to add an auxiliary head to the network that lies somewhere in the middle. While you are training, you are supervising this detection head as well as the head that is actually going to make predictions.
The auxiliary head does not train as efficiently as the final head because there is less network between it an the prediction - so the YOLOv7 authors experiment with different levels of supervision for this head, settling on a coarse-to-fine definition where supervision is passed back from the lead head at different granularities.
For more detail on the research contributions in YOLOv7, check out the YOLOv7 research paper.
The YOLOv7 Codebase
The YOLOv7 GitHub repository contains all of the code you need to get started training YOLOv7 on your custom data.
The network is defined in PyTorch . Training scripts, data loaders, and utility scripts are written in Python.
python train.py --workers 8 --device 0 --batch-size 32 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml The repository is evolution of the YOLOR and Scaled-YOLOv4 repositories, which is derived from WongKinYiu's YOLOv4-PyTorch repository, which arguably gathers a lot of its backbones from the original YOLOV3-PyTorch and YOLOv5 repositories by Ultralytics.
While initial benchmarks on the COCO benchmark are strong, we will see where the YOLOv7 repository evolves relative to the well-maintained YOLOv5 repository.
The YOLOv7 authors left us with an exciting teaser to watch - the unification of pose and instance segmentation tasks within YOLO, a long anticipated evolution.

YOLOv7 Next Steps
The YOLOv7 models here were all trained to detect the generic 80 classes in the COCO dataset. To use YOLOv7 for your own application, watch our guide on how to train YOLOv7 on your own custom dataset:
Video guide for training YOLOv7 in Colab
To read about other recent contributions in the field of object detection, check out our breakdown of YOLOv6, which dives deep into the architecture of YOLO.
If you are using your object detection models in production, look to Roboflow for setting up a machine learning operations pipeline around your model lifecycles and deployment schemas.
If you need to identify the specific location of items in a photo or video, check out our YOLOv7 Instance Segmentation tutorial. In the tutorial, we'll guide you through the process of preparing and training your own instance segmentation model using YOLOv7.
Frequently Asked Questions
What are the versions of YOLOv7?
YOLOv7 has multiple versions. YOLOv7 is the main version of the model. YOLOv7-tiny is a smaller model that is optimised for inference on edge devices. There is also YOLOv7-W6 which is commonly used in cloud computing.
What is YOLO used for?
YOLO is used to implement real-time object detection algorithms. For instance, you could use YOLO to detect cars in a video, or people walking on a street. One of the most prominent applications for YOLO is autonomous driving applications.
Cite this Post
Use the following entry to cite this post in your research:
Jacob Solawetz. (Jan 4, 2024). What is YOLOv7? A Complete Guide.. Roboflow Blog: https://blog.roboflow.com/yolov7-breakdown/