27 Jul 2026 • 10 min read Retail Object Detection with RF-DETR Train a model to detect empty shelf spaces and automate restocking decisions.
27 Jul 2026 • 22 min read Production Line Monitoring With Camera AI Build production line monitoring with camera AI: train RF-DETR to detect defects, count bottles, and trigger alerts with Roboflow Workflows.
22 Jul 2026 • 13 min read How to Make Automatic Highlight Reels from Kids' Soccer Games Upload a soccer game, click your kid once, and get back a highlight reel with every play they were part of. Two RF-DETR models trained in the Roboflow UI handle detection and tracking, and a local Python pipeline reads jersey numbers, finds the goals, and cuts the clips.
22 Jul 2026 • 6 min read Run RF-DETR in NVIDIA DeepStream on Jetson From pretrained weights to live multi-camera inference on a Jetson Orin NX: TensorRT engine build, the custom bbox parser DeepStream needs, and per-class colors with a pyds probe.
22 Jul 2026 • 8 min read Hog Ring Detection with Computer Vision Detect visible hog rings with RF-DETR, compare their positions with predefined attachment zones, and use Gemini 2.5 Pro to generate an automotive seat inspection summary.
22 Jul 2026 • 4 min read Gemini 3.6 Flash for Vision: Evaluation and Benchmarks Cheaper and faster than Gemini 3.5 Flash, and the best model we tested on video. Object detection is the one real step back.
22 Jul 2026 • 10 min read Flanges Quality Inspection with Computer Vision Train RF-DETR to catch flange face defects, then sort results into pass, review, and fail.
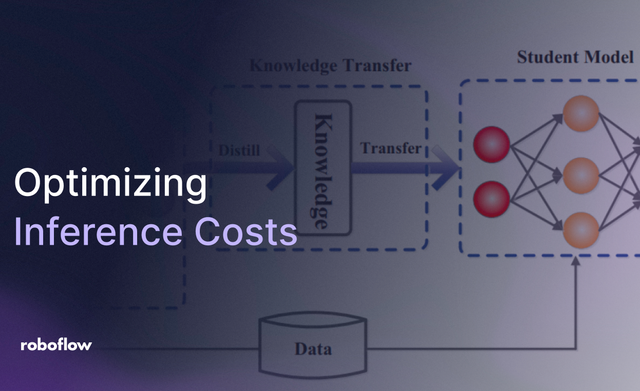
20 Jul 2026 • 13 min read Advanced Techniques for Optimizing AI Inference Costs In this guide, you will learn about advanced techniques that can help reduce AI inference costs across the complete computer vision pipeline.
17 Jul 2026 • 9 min read Pipe and Tubes Quality Inspection with Roboflow Automate tube and pipe defect inspection. Train an RF-DETR model to detect holes, cracks, and ruptures, and build a pass, review, or fail Workflow in Roboflow.
17 Jul 2026 • 9 min read Retail Object Detection with RF-DETR Detect visible beverage products with RF-DETR, compare their counts with fixed camera-frame thresholds, and use Gemini 2.5 Pro to generate a shelf inspection summary.
17 Jul 2026 • 17 min read Teaching a Porch to Recognize Delivery Drivers and Accept Packages An end-to-end build of a self-unlocking porch lockbox: on-device detection on an old iPhone gates a cloud Roboflow Workflow, which validates courier-with-package events inside a drawn porch zone and triggers a solenoid lock through an ESP32. Includes delivery verification and a live dashboard.
17 Jul 2026 • 11 min read Cosmetic Defect Detection with Computer Vision Learn how computer vision can automate cosmetic defect inspection by detecting paint scratches and identifying the affected car part. This guide shows how to train an RF-DETR model in Roboflow, build a part-level inspection Workflow, and return visual results and repair-ready outputs for QA review.
16 Jul 2026 • 6 min read Multi-Model Auto Labeling for Segmentation with Roboflow Workflows Stack SAM 3, Gemini, and GPT into a single Workflow, require a 2-of-3 vote on every mask, and auto-label entire segmentation datasets without drawing a single polygon.
16 Jul 2026 • 18 min read Roboflow Serverless Inference: A Thousand Models on a Shared GPU Fleet Most web services ingest kilobytes and emit the heavy bytes. Vision inference flips that, and breaks a few more production assumptions on the way. Here's the serverless architecture behind a thousand models on a shared GPU fleet.
16 Jul 2026 • 6 min read GPT 5.6 Sol is the best "vision" model OpenAI ever released GPT-5.6 Sol is OpenAI’s strongest vision model yet. We tested Sol, Terra, and Luna across detection, counting, OCR, and extraction, then compared their results, speed, and cost with leading VLMs.
15 Jul 2026 • 4 min read How to Scale a Computer Vision Pilot to Production in Manufacturing See how to scale a computer vision pilot to production: why 77% stall on integration, not the model, and how to get past it in manufacturing.
15 Jul 2026 • 21 min read Best Computer Vision Models in 2026: A Task-by-Task Guide Explore the best computer vision models in 2026 for object detection, segmentation, classification, keypoints, OCR, vision-language tasks, depth estimation, and tracking. Compare leading models, benchmarks, licensing, deployment options, and when to fine-tune on custom data using Roboflow tools.
14 Jul 2026 • 13 min read Open Vocabulary Segmentation Learn how to build a zero-shot segmentation pipeline with SAM 3 and Roboflow Workflows.
14 Jul 2026 • 10 min read Segment Anything with Text Use Segment Anything with Text in Roboflow Workflows to segment workers, helmets, and safety vests without training a custom model.
14 Jul 2026 • 11 min read Analyze Video Feeds for Process Monitoring with RF-DETR Analyze video feeds for process monitoring with Roboflow: RF-DETR detects, ByteTrack tracks, and a line counter logs counts and speed.
13 Jul 2026 • 13 min read Automate Surface Defects Detection with Vision AI Learn how computer vision can detect surface defects. This guide explains common use cases and shows how to build a Roboflow surface inspection workflow that detects defects, visualizes results, and supports quality decisions.
10 Jul 2026 • 16 min read Product Recognition AI Product Recognition AI helps businesses identify, count, and verify products from images or video. This blog explains key use cases and shows how to build a Roboflow Product-to-Bill Verification System that detects products, reads receipts, and checks billing accuracy.
10 Jul 2026 • 11 min read How to Detect Paint Defects with Computer Vision Automate paint defect inspection in manufacturing. Learn how to train an RF-DETR model and build a visual QA pipeline using Roboflow Workflows.
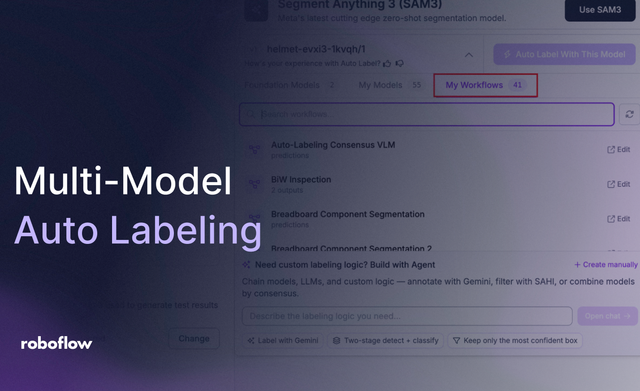
10 Jul 2026 • 6 min read Multi-Model Auto Labeling with Roboflow Workflows Roboflow has brought the full power of Workflows into Auto Label, letting you run custom pipelines serverlessly on your unannotated images. This post walks through building a sample multi-VLM workflow from scratch, then shows how to launch it on an image batch in a few clicks.