
GPT-4 Vision and Roboflow address different parts of a computer vision pipeline and work well in combination. GPT-4V handles zero-shot image and video classification, auto-labeling for detection and segmentation datasets via Autodistill and Grounding DINO, and OCR on regions identified by a fine-tuned model. Fine-tuned models remain the production engine for speed and edge deployment, while GPT-4V accelerates dataset creation and handles tasks that require broad world knowledge, such as reading text or refining ambiguous class labels.
In October 2023, OpenAI released an API for GPT-4 with vision, an extension to GPT-4 that enables you to ask questions about images. GPT-4 is now capable of performing tasks such as image classification, visual question answering, handwriting OCR, document OCR, and more. The GPT-4 with vision API opens up a new world of possibilities in building computer vision applications. Read our analysis of GPT-4 Vision’s capabilities.
The capabilities of GPT-4 are enhanced when matched with Roboflow’s object detection, classification, and segmentation models, as well as foundation models available through Roboflow Inference, an open source inference server that powers millions of inferences a month on production models.
In this guide, you will learn three ways you can use Roboflow with GPT-4 for vision related use cases. We see fine-tuned models as the engine behind many specialized vision applications, with GPT-4 Vision providing useful tools to help you build vision-powered applications faster than ever before.
Without further ado, let’s get started!
Zero-Shot Image and Video Classification with GPT-4
Zero-shot classification is when you provide an image and a list of categories to a foundation model and evaluate how relevant each category is to an image. For example, you can upload an image from a yard and identify whether the image is a shipping container, a loading dock, or another environment in the yard.

Zero-shot classification can be applied to a range of use cases. For example, you can use zero-shot classification models to label data for use in training a fine-tuned model. Or you could use a zero-shot classification model to classify frames in a video, identifying the tag(s) most relevant to a given frame or scene.
GPT-4 has impressive zero-shot capabilities, but there are limitations. First, GPT-4 is a remote API, which means you cannot use the tool if you do not have an internet connection. Second, there is a fee for every call to the GPT-4 API. Third, you cannot deploy GPT-4 on-device for edge deployments.
We recommend using an open source zero-shot model like CLIP as a starting point, another model that achieves impressive performance on classification tasks. CLIP can solve many classification problems, and you can run it on your own hardware. Learn more about how to deploy CLIP to your own hardware with Roboflow Inference.
Read our guide that compares zero-shot classification with CLIP and GPT-4V.
Auto-Label Detection and Segmentation Datasets with GPT-4
As of writing this article, GPT-4 is not able to accurately identify the location of objects in images. With that said, you can use a zero-shot model such as Grounding DINO (object detection) or Segment Anything (segmentation) to identify the regions in which objects appear. Then, you can use GPT-4 to assign a specific label to each region.
Consider a scenario where you want to label car brands for use in building an insurance valuation application that uses computer vision. You could use Grounding DINO to identify cars in images, then GPT-4 to identify the exact brand of the car (i.e. Mercedes, Tesla). A fine-tuned model will run faster than GPT-4 or Grounding DINO, can be deployed to the edge, and can be tuned as the needs you want to address with vision evolve.
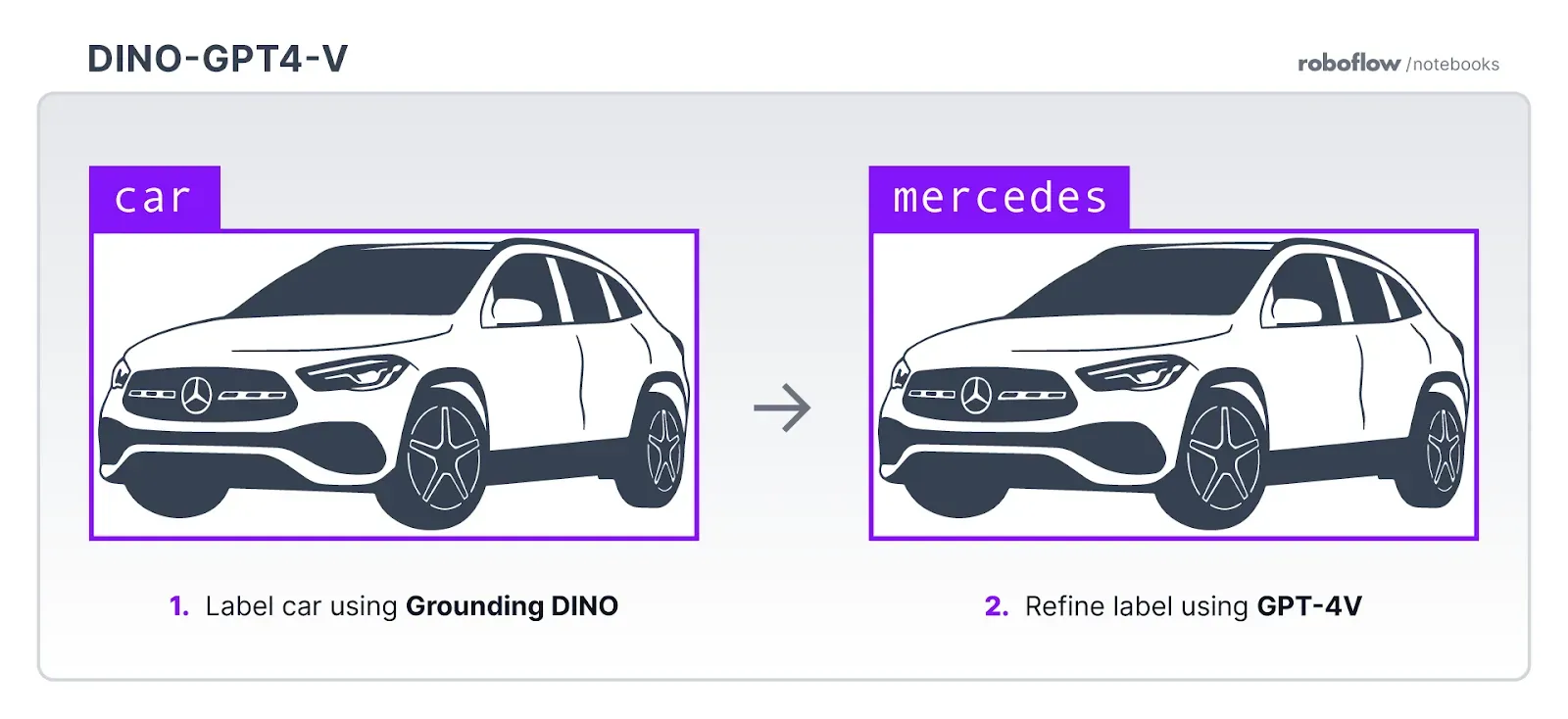
You can use this approach with Autodistill, a framework that enables you to use large, foundation models like Grounding DINO and GPT-4 to label data for use in training a fine-tuned model.
Check out our blog post that shows how to use Grounding DINO and GPT-4 together for automated labeling for more information.
Use Fine-Tuned Models and GPT-4 for OCR
Fine-tuned models and GPT-4 can work together as part of a two-stage process. For example, you can use a fine-tuned object detection model to detect serial numbers on shipping containers. Then, you can use GPT-4 to read the characters in the image.
A fine-tuned model can isolate the exact regions in an image that you want to read, which enables you to read only text in relevant regions. You can also map text returned by GPT-4 to each region using the label returned by an object detection model.
As with all OCR tasks, we recommend that you test to see if GPT-4 is able to accurately read characters in the images with which you are working. In our tests, we have seen mixed performance; GPT-4 performed well in a handwriting test, for example, but made errors in odometer reading.
Use Few-Shot Prompting for Image Tasks
Autodistill, an open source framework for training fine-tuned models using large, foundation vision models, will soon support few-shot image prompting, powered by Retrieval Augmented Generation (RAG). Few-shot prompting involves providing additional examples or references to help a model learn. Through this system, you can craft a GPT-4 prompt that features an image, a text prompt, and reference images from a computer vision dataset.
Consider a scenario where you want to identify if a car part contains a scratch. You can use Roboflow to retrieve car parts that are similar to the image you have uploaded. Then, you can provide those car parts as context in your prompt to GPT-4. This enables you to provide more context that can be used to answer a question.
Conclusion
Fine-tuned models are the engine behind modern computer vision applications, enabling you to accurately detect and segment images. These models can be combined to reduce the time it takes to launch a vision model in production.
For example, you can use GPT-4 and another foundation model like Grounding DINO to auto-label images with Autodistill. You can use a fine-tuned model to identify text regions in an image (i.e. a shipping container label) then GPT-4 to read the text in the image.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher. (Nov 15, 2023). How to Use Roboflow with GPT-4 Vision. Roboflow Blog: https://blog.roboflow.com/use-roboflow-with-gpt-4-vision/