
In September 2023, OpenAI rolled out the ability to ask questions about images using GPT-4. A month later at the OpenAI DevDay, these capabilities were made available through an API, allowing developers to build applications that use GPT-4 with image inputs.
While GPT-4 with Vision has captured significant attention, the service is only one of many Large Multimodal Models (LMMs). LMMs are language models that can work with multiple types, or "modalities," of information, such as images and audio.
In this guide, we are going to explore five alternatives to GPT-4 with Vision: four LMMs (LLaVA, BakLLaVA, Qwen-VL, and CogVLM) and training a fine-tuned computer vision model. Interested in the TL;DR? Check out our table showing the results from our tests covering VQA, OCR, and zero-shot object detection:
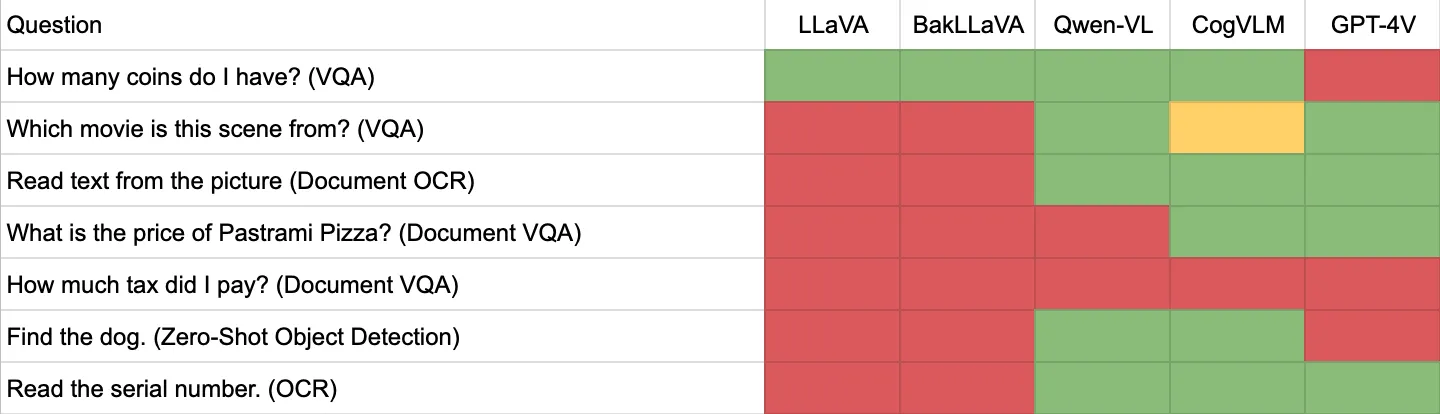
We walk through each of these tests, and the considerations when using fine-tuned vision models (i.e. object detection models), in this guide. We have included excerpts from tests below, but you can see all of our results in our LMM evaluation results (ZIP file, 10.6 MB).
Our tests are not comprehensive, rather a snapshot of a series of tests we ran consistently across all models.
Without further ado, let's get started!
What is GPT-4 with Vision?
Introduced in September 2023, GPT-4 with Vision enables you to ask questions about the contents of images. This is referred to as visual question answering (VQA), a computer vision field of study that has been researched in detail for years. You can also perform other vision tasks such as Optical Character Recognition (OCR), where a model reads characters in an image.
Using GPT-4 with Vision, you can ask questions about what is or is not in an image, how objects relate in an image, the spatial relationships between two objects (is one object to the left or right of another), the color of an object, and more.
GPT-4 with Vision is available through the OpenAI web interface for ChatGPT Plus subscribers, as well as through the OpenAI GPT-4 Vision API.
The Roboflow team has experimented extensively with GPT-4 with Vision. We have found strong performance in visual question answering, OCR (handwriting, document, math), and other fields. We have also noted limitations. For example, GPT-4 with Vision struggles to identify the specific location of objects in images.
Alternatives to GPT-4 with Vision
The computer vision industry is moving fast, with multimodal models playing a growing role in the industry. At the same time, fine-tuned models are showing significant value in a range of use cases, as we will discuss below.
OpenAI is one of many research teams pursuing LMM research. In the last year, we have seen GPT-4 with Vision, LLaVA, BakLLaVA, CogVLM, Qwen-VL, and other models all aim to connect text and image data together to create an LMM.
Every model has its own strengths and weaknesses. The vast capabilities of LLMs – covering areas from Optical Character Recognition (OCR) to Visual Question Answering (VQA) – are hard to compare; this is the role of benchmarking. Thus, no model below "replaces" GPT-4 with Vision, rather acts as an alternative to GPT-4 with Vision.
Let's talk about some of the alternatives to GPT-4 with Vision, noting pros and cons. One important difference is the alternatives being evaluated are open source whereas GPT-4 is closed source. This means you can deploy the alternatives offline and on-device using something like the Roboflow Inference Server to have more control when using these models.
Qwen-VL
Qwen-VL is an LMM developed by Alibaba Cloud. Qwen-VL accepts images, text, and bounding boxes as inputs. The model can output text and bounding boxes. Qwen-VL naturally supports English, Chinese, and multilingual conversation. Thus, this model may be worth exploring if you have a use case where you expect Chinese and English to be used in prompts or answers.
Below, we use Qwen-VL to ask from what movie the photo was taken:
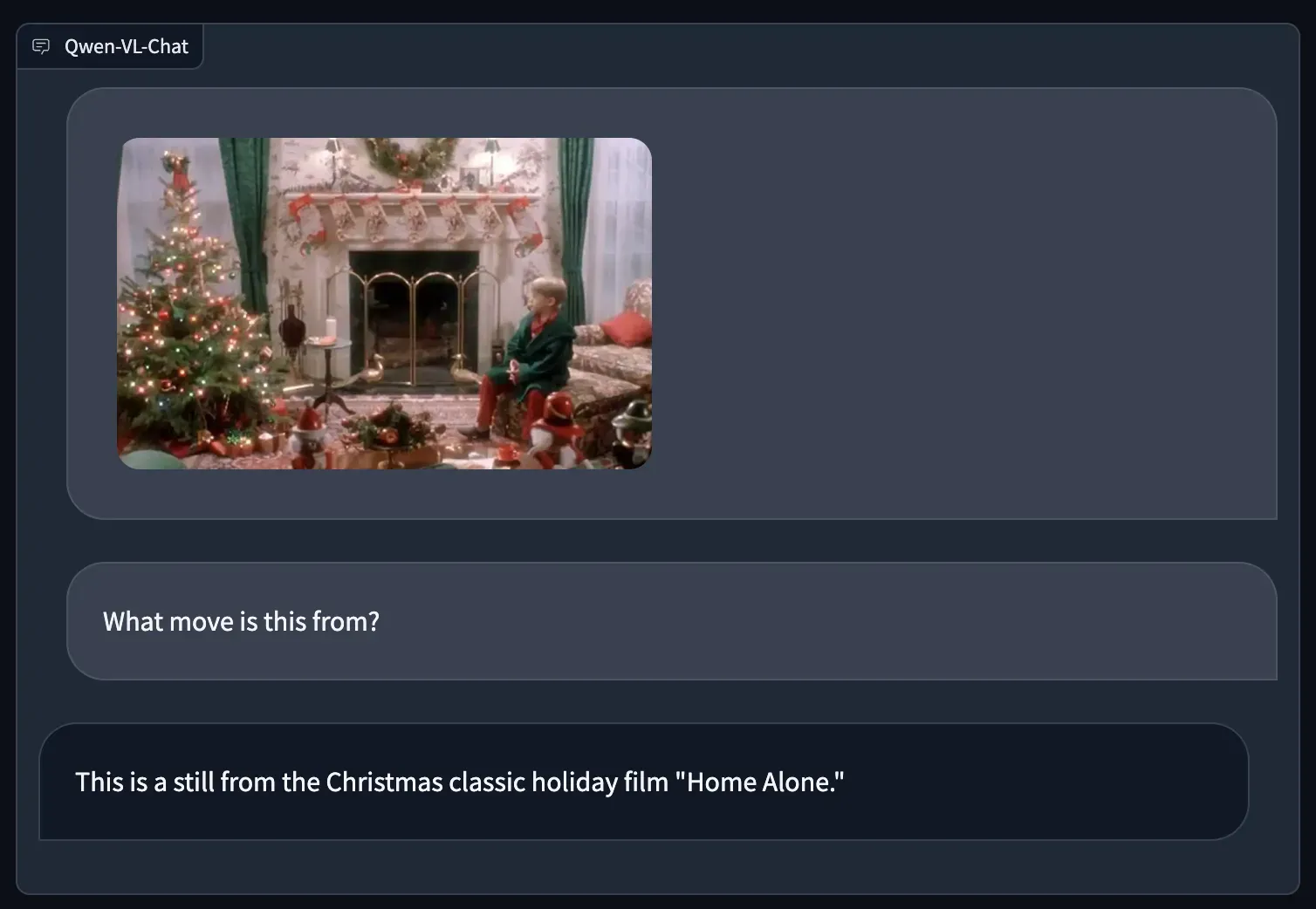
Qwen-VL successfully identifies the movie from the provided image as Home Alone.
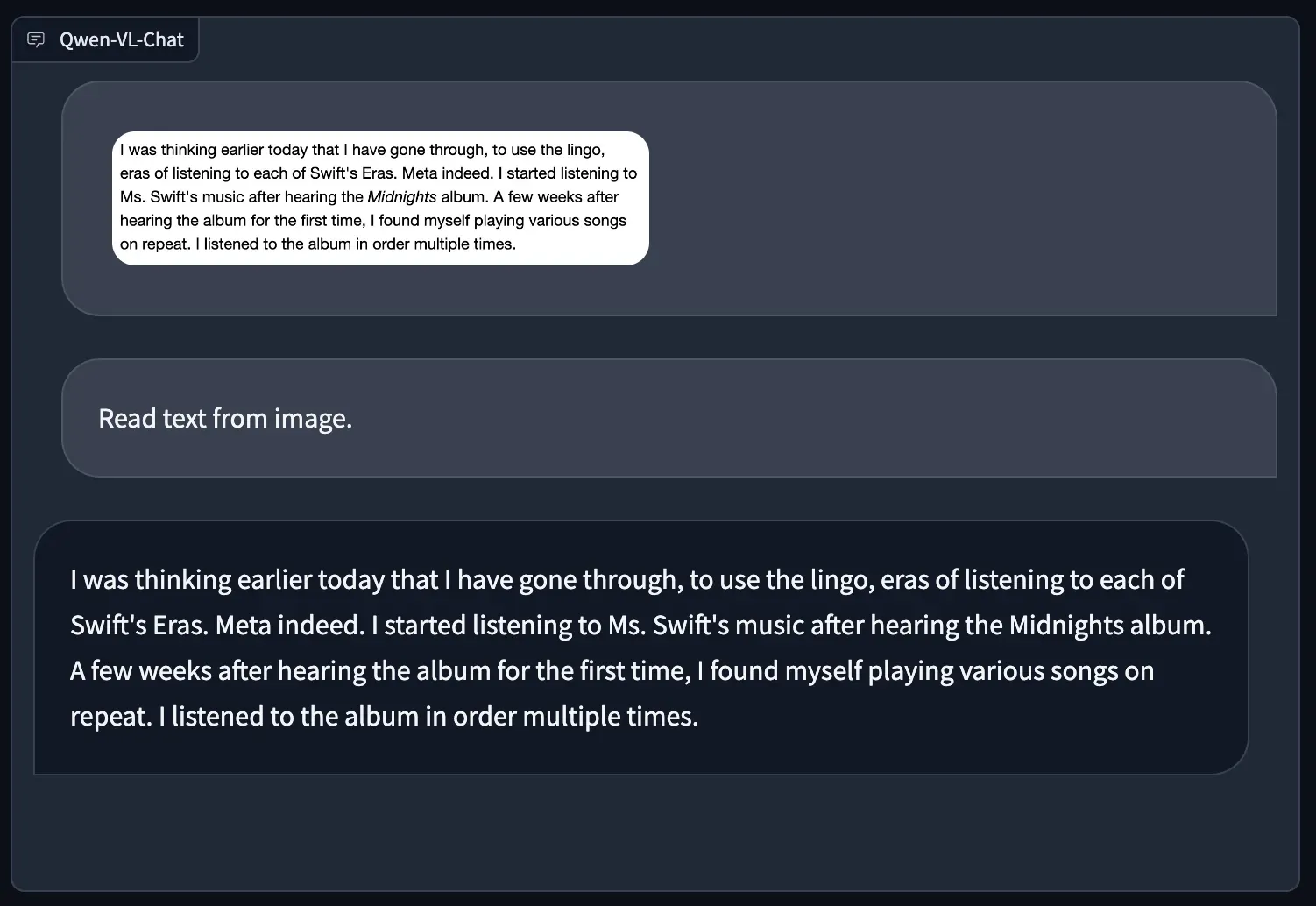
Qwen-VL succeeded with document OCR, too, in which we asked the model to provide the text in a screenshot of a web page:
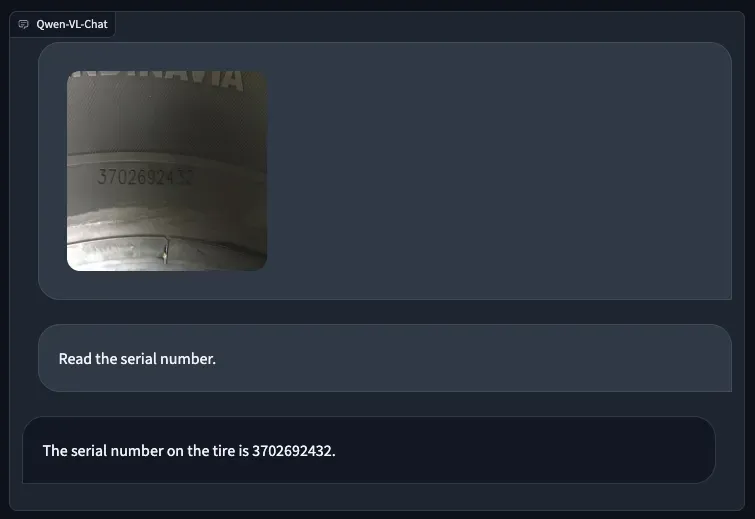
Qwel-VL also succeeded in identifying the serial number on a tire:
CogVLM
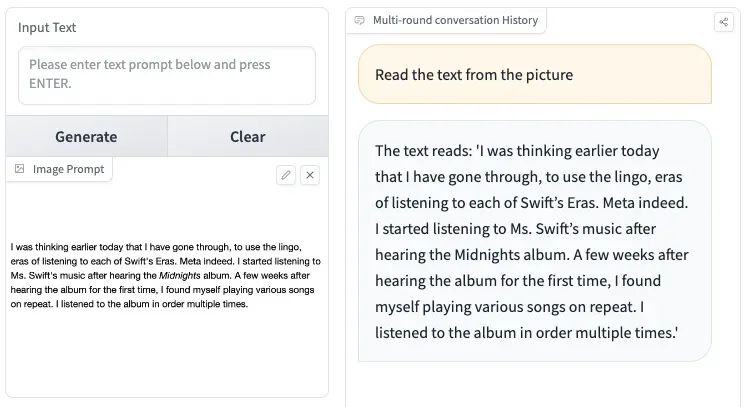
CogVLM can understand and answer various types of questions and has a visual grounding version. Grounding the ability of the model to connect and relate its responses to real-world knowledge and facts, in our case objects on the image.
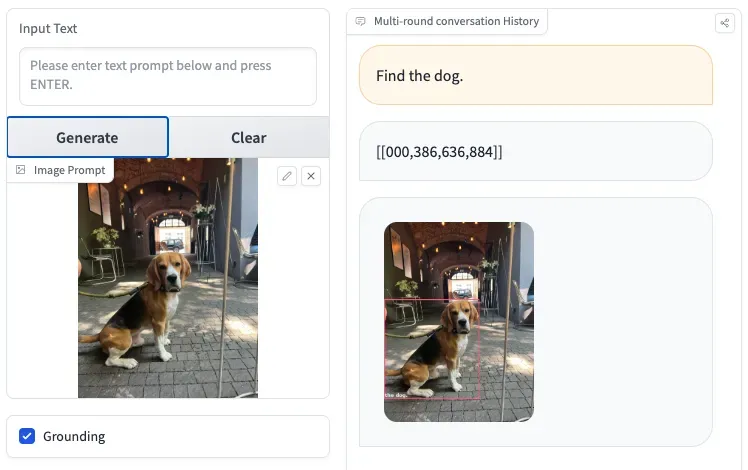
CogVLM can accurately describe images in detail with very few hallucinations. The image below shows the instruction "Find the dog". CogVLM has drawn a bounding box around the dog, and provided the coordinates to the dog. This shows that CogVLM can be used for zero-shot object detection, as it returns coordinates of grounded objects. (Note: In the demo space we used, CogVLM plotted bounding boxes for predictions)
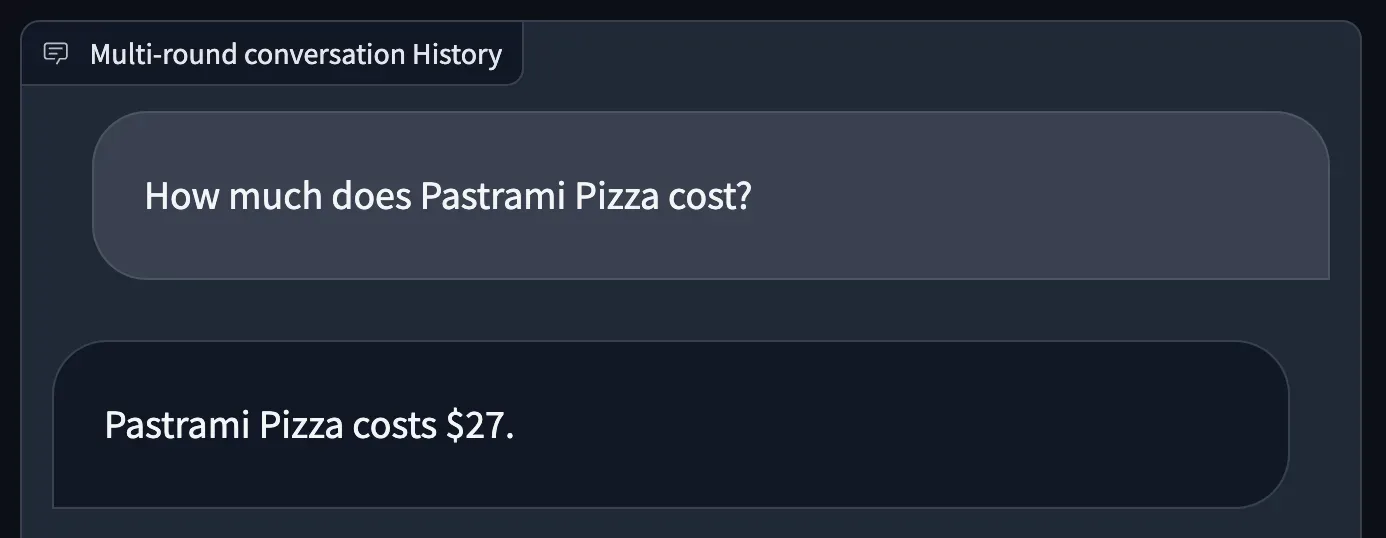
CogVLM, like GPT-4 with Vision, can also answer questions about infographics and documents with statistics or structured information. Given a photo of a pizza, we asked CogVLM to return the price of a pastrami pizza. The model returned the correct response:

LLaVA
Large Language and Vision Assistant (LLaVA) is a Large Multimodal Model (LMM) developed by Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. At the time of writing this article, the most recent version of LLaVA is version 1.5.
LLaVA 1.5 is arguably the most popular alternative to GPT-4V. LLaVA is mainly used in VQA. You can ask LLaVA questions about images and retrieve answers. With that said, the Roboflow team has found some capabilities in zero-shot object detection and Object Character Recognition (OCR).
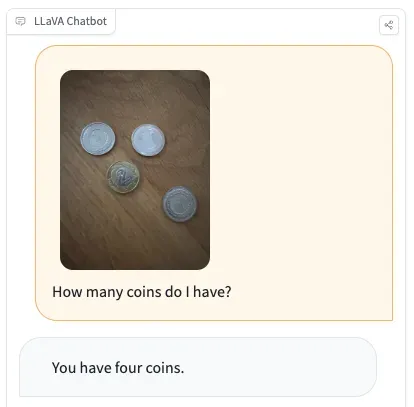
In all but one of our tests (the coin example above), LLaVA failed to return the correct response to a question.
BakLLaVA
BakLLaVA is a LMM developed by LAION, Ontocord, and Skunkworks AI. BakLLaVA uses a Mistral 7B base augmented with the LLaVA 1.5 architecture. Used in combination with llama.cpp, a tool for running the LLaMA model in C++, you can use BakLLaVA on a laptop, provided you have enough GPU resources available.
BakLLaVA is a faster and less resource-intensive alternative to GPT-4 with Vision. However, without fine-tuning LLaVA more often returns incorrect results. In all but one of our tests, BakLLaVA failed to return the correct response.
ChatGPT with page completely local & private & offline
— Robert Lukoszko — e/acc (@Karmedge) October 28, 2023
This Extension allows you to ask questions on any page for FREE. Keeping your privacy intact
Comment if you want it open source!
cc: @xenovacom @Scobleizer @llamacommunity_#buildinginpublic #llama pic.twitter.com/ub29s4yEJ4
Fine-Tuned Computer Vision Models
Fine-tuned models are trained to identify a limited set of objects. For example, you may train a fine-tuned model to identify specific product skus for use in a retail store application, or train a model to identify forklifts for use in a safety assurance tool.
To build a fine-tuned model, you need a collection of labeled images. These images should be representative of the environment in which your model is deployed. Each label should point to an object of interest (i.e. a product, a defect). This information is then used to train a model to identify all of the classes you added as labels to your dataset.
Fine-tuned models, such as models trained using the RF-DETR or ViT architectures, can run in close to real time. For example, you could connect an RF-DETR model to the output of a camera that monitors a construction yard to look for when forklifts get too close to a person.
Training a fine-tuned model takes time since you need to gather and label data. This is in contrast to LMMs, which work out of the box without any fine-tuned training. With that said, the requirement to gather and label data is a blessing in disguise: because you know what goes in your model, you can debug what is going wrong.
For example, if your model struggles to identify a class, you can tweak your model until it performs well. LMMs, in contrast, are much harder to understand; fine-tuning an LMM is prohibitively expensive for most, and technically challenging.
The Future of Multimodality
GPT-4 with Vision brought multimodal language models to a large audience. With the release of GPT-4 with Vision in the GPT-4 web interface, people across the world could upload images and ask questions about them. With that said, GPT-4 with Vision is only one of many multimodal models available.
Multimodality is an active field of research, with new models released on a regular basis. Indeed, all of the models listed above were released in 2023. Multimodal models like GPT-4 with Vision, LLaVA, and Qwen-VL demonstrate capabilities to solve a wide range of vision problems, from OCR to VQA.
In this guide, we walked through two main alternatives to GPT-4 with Vision:
- Using a fine-tuned model, ideal if you need to identify the location of objects in images.
- Using another LMM such as LLaVA, BakLLaVA, Qwen-VL, or CogVLM, which are ideal for tasks such as VQA.
With the pace that multimodal models are being developed, we can expect many more to be trained and released over the coming years.
Cite this Post
Use the following entry to cite this post in your research:
James Gallagher, Piotr Skalski. (Nov 23, 2023). GPT-4 Vision Alternatives. Roboflow Blog: https://blog.roboflow.com/gpt-4-vision-alternatives/