
Running computer vision models offline, whether on a laptop, an NVIDIA Jetson, or a fully air-gapped factory network, removes cloud dependency and is increasingly required where latency, reliability, and data privacy matter. This guide walks through two deployment paths using Roboflow Inference: the native Python library, where models including RF-DETR run directly in-process on an edge device, and the Inference Server (Docker, CLI, and SDK), which exposes inference over HTTP for distributed or air-gapped setups where multiple clients connect to a local service. A bonus section covers running a complete Roboflow Workflow offline on an RTSP stream.
Running computer vision locally in offline mode means deploying and executing models directly on a device such as a laptop, an edge device like NVIDIA Jetson, or an embedded system, instead of relying on cloud servers. This also includes air-gapped systems where devices operate in complete isolation without any network connectivity.
This allows real-time processing with lower latency and is commonly used in applications such as surveillance, drones, and industrial inspection, where fast and reliable on-device inference is required.
Deploy Computer Vision Models Offline
In this guide, we will explore how to deploy computer vision models offline using Roboflow Inference, an open-source, scalable inference library. It enables you to run fine-tuned and foundation vision models such as RF-DETR, YOLO, SAM 3, and more, as well as complete computer vision workflows built from these models, entirely offline in your local environment.
What Is Roboflow Inference?
The inference Python package from Roboflow is the core library that powers Roboflow's computer vision deployment stack. It handles model serving, video stream management, preprocessing and postprocessing, as well as GPU and CPU optimizations.
You can use the inference package directly in your Python scripts to run various computer vision models.The Inference Server wraps this package and exposes it over HTTP (distributed as a Docker image with all dependencies installed). You can start an inference server using inference_cli and then communicate with it over HTTP using inference_sdk from a Python script.
The relationship between them is demonstrated below:
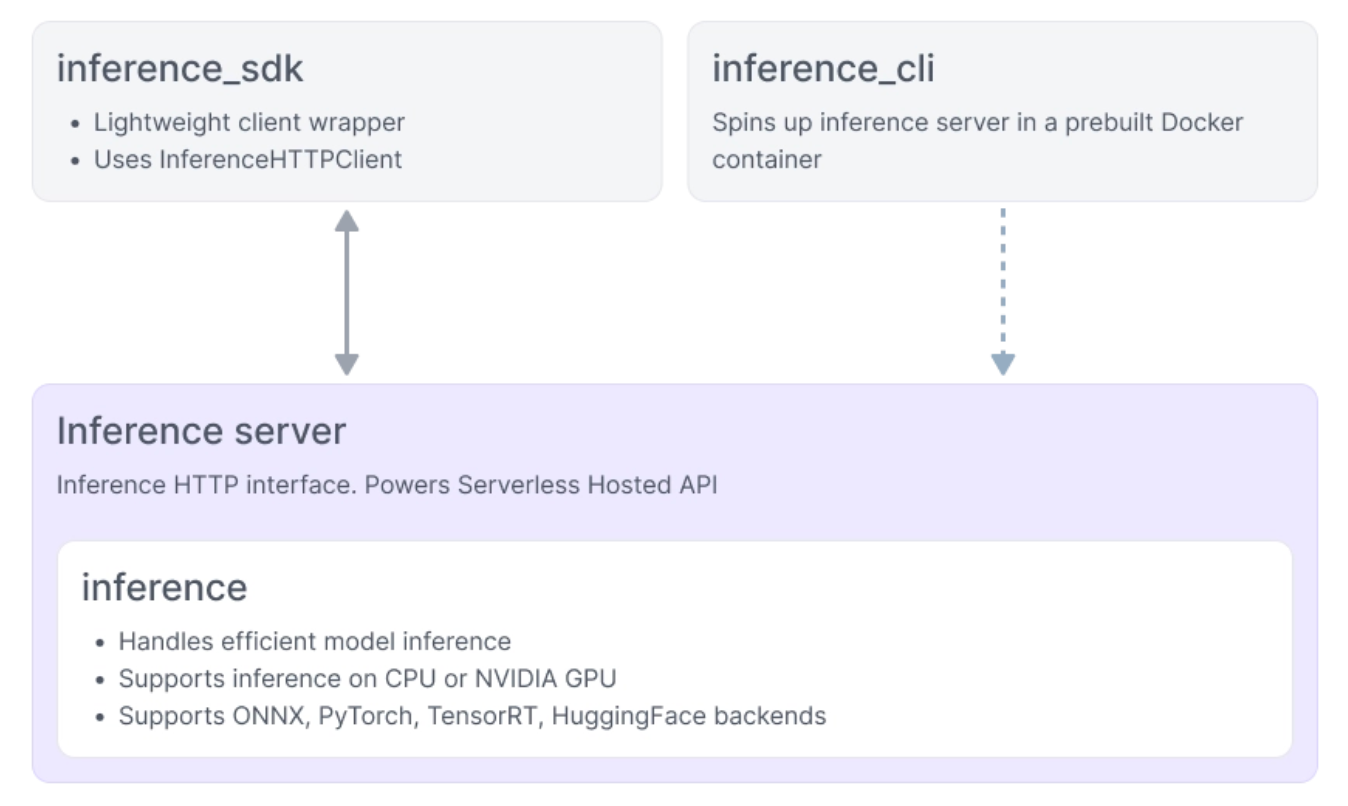
In an offline computer vision setup, you would use the inference library when you want everything to run inside a local Python process, such as on an edge device like a Jetson or an industrial PC, where the model is loaded and executed directly in code.You would use the inference cli + sdk combination when you instead want to deploy a dedicated local Inference Server on a factory network or air-gapped environment, where factory devices send images or video streams over HTTP to the local server for inference.This guide demonstrates both deployment approaches:Native inference (direct Python usage)Inference Server (cli + sdk)
Option 1: Deploy Computer Vision Models for Offline Usage with Native Roboflow Inference (direct Python usage)
In this approach, the model runs directly within your Python process. No Docker setup is required, and there is no need to run a separate server. It uses the inference Python package from Roboflow.
Step 1: Install Inference library
Start by installing the inference Python package. Make sure your Python version is <3.13 and >=3.10 (Supported Python versions as of 5/31/2026).
pip install inference
Step 2: Run model locally
You can now use the get_model function, which loads a model into your script and returns an object on which you can call the infer function to perform inference.
With the get_model function, you can load a variety of models for tasks such as object detection, segmentation, and classification, and more, including fine-tuned models available in your Roboflow workspace or on Roboflow Universe.
from inference import get_model
IMAGE_PATH = "construction_site.jpg"
# Load a pre-trained RF-DETR model for object detection
# You can optionally pass `api_key` if you need access to private models or datasets
model = get_model(model_id="rfdetr-small")
# Run inference on the input image and get detection results
results = model.infer(IMAGE_PATH)
# Print model output
print(results)
On a test image, the model produced the following outputs after inference.
[ObjectDetectionInferenceResponse(visualization=None, inference_id=None, frame_id=None, time=None, image=InferenceResponseImage(width=4928, height=3264), predictions=[ObjectDetectionPrediction(x=2636.8984375, y=906.7336273193359, width=613.43798828125, height=1062.0249328613281, confidence=0.8969464302062988, class_name='person', class_confidence=None, class_id=1, tracker_id=None, detection_id='07d071f6-5ac0-4600-8819-e9094f37b266', parent_id=None), ObjectDetectionPrediction(x=2497.64990234375, y=2050.1674194335938, width=508.060546875, height=1565.0767822265625, confidence=0.8966809511184692, class_name='person', class_confidence=None, class_id=1, tracker_id=None, detection_id='d692491f-b2ab-49ac-bfd6-c9865237aa39', parent_id=None)])]Note: An internet connection is required for the initial inference to download the model. After the first run, the model is cached locally, allowing all subsequent runs to execute offline and with improved speed.
Step 3: Visualize Predictions
You can now use the model predictions to visualize them directly on the image using the supervision Python library.
Install Supervision Supervision is an open-source Python library by Roboflow used in computer vision to make it easier to work with model predictions. It focuses on processing, visualizing, and manipulating outputs from object detection, segmentation, and tracking models.
pip install supervisionVisualize the Prediction classes
You can now add the code snippet below to the script above that performs model inference. The snippet uses the supervision library to visualize bounding boxes and class labels for detected objects.
import cv2
import supervision as sv
# Get first result
predictions = results[0]
# Convert to Supervision detections
detections = sv.Detections.from_inference(predictions)
# Read image
image = cv2.imread(IMAGE_PATH)
# Labels
labels = [
pred.class_name
for pred in predictions.predictions
]
# Auto-scale annotation sizes
thickness = sv.calculate_optimal_line_thickness(
resolution_wh=(image.shape[1], image.shape[0])
)
text_scale = sv.calculate_optimal_text_scale(
resolution_wh=(image.shape[1], image.shape[0])
)
# Annotators
box_annotator = sv.BoxAnnotator(
thickness=thickness * 2
)
label_annotator = sv.LabelAnnotator(
text_scale=text_scale,
text_thickness=thickness,
text_padding=10
)
# Draw boxes
annotated_frame = box_annotator.annotate(
scene=image.copy(),
detections=detections
)
# Draw labels
annotated_frame = label_annotator.annotate(
scene=annotated_frame,
detections=detections,
labels=labels
)
# Display
sv.plot_image(
image=annotated_frame,
size=(16, 16)
)The image below shows the output produced by the script above on a test image:

Step 4: Run inference on webcam (native pipeline)
Inference Pipeline interface provided by inference package is made for streaming and is likely the best route to go for real time use cases.It is an asynchronous interface that can consume many different video sources including local devices (like webcams), RTSP video streams, video files, etc. With this interface, you define the source of a video stream and sinks.
The script below demonstrates how to use it to utilize your webcam stream to perform inference on a model:
from inference import InferencePipeline
from inference.core.interfaces.stream.sinks import render_boxes
pipeline = InferencePipeline.init(
model_id="rock-paper-scissors-sxsw/11", # from Roboflow Universe
video_reference=0, # integer device id of webcam or "rstp://0.0.0.0:8000/password" for RTSP stream
on_prediction=render_boxes,
api_key="YOUR_ROBOFLOW_API_KEY",
)
pipeline.start()
pipeline.join()Note: Similar to get_model, the InferencePipeline caches the model locally after the first run. This enables all subsequent runs to execute offline and with improved performance.
When you run the above code, the model performs inference on frames captured from your webcam.
Option 2: Deploy Computer Vision Models for Offline Usage with Roboflow Inference Server (CLI + SDK)
In this approach, we first start a local inference server using the inference-cli package and Docker. Docker is a platform that packages applications and their dependencies into lightweight, portable containers.Once the server is running, we can interact with it over HTTP using the inference-sdk.
Step 1: Set up Local Inference Server
Roboflow Inference runs in Docker, with prebuilt Docker images available for a variety of popular edge devices and compute architectures.
This Docker-based setup handles all required dependencies for the models you deploy, allowing you to focus on building your application logic instead of environment configuration.
To begin, you must first install Docker. Refer to the official Docker installation instructions for guidance.
Install Inference CLIOnce Docker is installed, install the roboflow inference-cli Python package. It is a command-line tool used to run and manage inference servers.
pip install inference-cliMake sure your Python version is <3.13 and >=3.10 (Supported Python versions as of 5/31/2026).
Start the Inference Server
You can use the inference-cli to start the inference server with the command below:
inference server start --port 9001Once the command finishes pulling the Docker inference server image, the Inference server will be available at http://localhost:9001 as shown below.
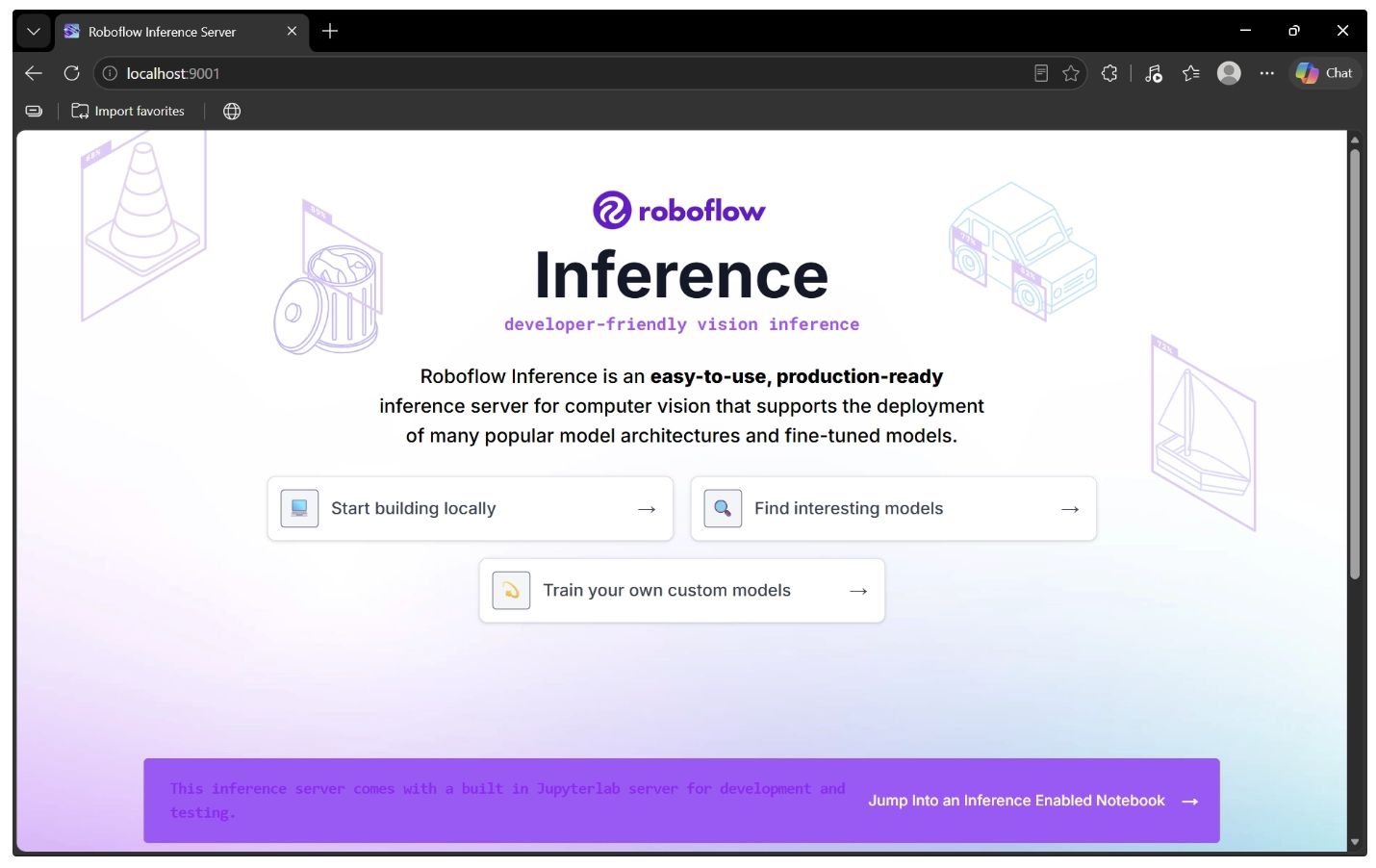
Step 2: Communicate with Inference Server using Inference SDK
Now you can use the inference-sdk to communicate with the inference server over HTTP.
Install Inference-sdk
You can download and install the sdk in your environment using the command below.
pip install inference-sdkMake sure your Python version is <3.13 and >=3.10 (Supported Python versions as of 5/31/2026).
Perform Inference on an image using a Model
You can now run the script below to perform inference on an image over HTTP using a computer vision model via the inference-sdk:
from inference_sdk import InferenceConfiguration, InferenceHTTPClient
# Path to input image
IMAGE_PATH = "construction_site.jpg"
# Model to use for inference
MODEL_ID = "rfdetr-nano"
# Configure inference thresholds
config = InferenceConfiguration(
confidence_threshold=0.5, # ignore low-confidence detections
iou_threshold=0.5 # overlap threshold for NMS
)
# Create inference client pointing to local server
# You can optionally pass `api_key` if you need access to private models or datasets
client = InferenceHTTPClient(
api_url="http://localhost:9001",
)
# Apply configuration and select model
client.configure(config)
client.select_model(MODEL_ID)
# Run inference on image
predictions = client.infer(IMAGE_PATH)
# Print model output
print(predictions)With the select_model function, you can load a variety of models for tasks such as object detection, segmentation, and classification onto the Inference server, including fine-tuned models available in your Roboflow workspace or on Roboflow Universe.
On a test image, the model produced the following outputs after inference.
{'inference_id': '0380c0bf-fff1-413b-876d-13855f055bdd', 'time': 0.775410069999964, 'image': {'width': 4928, 'height': 3264}, 'predictions': [{'x': 2641.0, 'y': 886.5, 'width': 602.0, 'height': 1031.0, 'confidence': 0.9222133159637451, 'class': 'person', 'class_id': 1, 'detection_id': '7859c8b1-7cb9-4870-8734-0169d90571f7'}, {'x': 2545.0, 'y': 2051.0, 'width': 398.0, 'height': 1562.0, 'confidence': 0.8956747055053711, 'class': 'person', 'class_id': 1, 'detection_id': '76338fc8-9d3b-4385-81bd-11da9493f811'}]}Note: On the first inference (internet connection required), the Inference Server downloads the required model and caches it locally, so all subsequent runs can be executed offline.
Step 3: Visualize Predictions
You can now use the model predictions to visualize them directly on the image using the supervision Python library.
Install Supervision
Supervision is an open-source Python library by Roboflow used in computer vision to make it easier to work with model predictions. It focuses on processing, visualizing, and manipulating outputs from object detection, segmentation, and tracking models.
pip install supervision Visualize the Prediction classes
You can now add the code snippet below to the script above that performs model inference. The snippet uses the supervision library to visualize bounding boxes and class labels for detected objects.
import supervision as sv
import cv2
# Create class id -> class name mapping
class_ids = {
p["class_id"]: p["class"]
for p in predictions["predictions"]
}
print(class_ids)
# Convert predictions to Supervision detections
detections = sv.Detections.from_inference(predictions)
# Read image
image = cv2.imread(IMAGE_PATH)
# Labels
labels = [
f"{class_ids[class_id]}"
for class_id in detections.class_id
]
# Auto-scale for image resolution
thickness = sv.calculate_optimal_line_thickness(
resolution_wh=(image.shape[1], image.shape[0])
)
text_scale = sv.calculate_optimal_text_scale(
resolution_wh=(image.shape[1], image.shape[0])
)
# Box annotator
box_annotator = sv.BoxAnnotator(
thickness=thickness * 2
)
# Label annotator
label_annotator = sv.LabelAnnotator(
text_scale=text_scale,
text_thickness=thickness,
text_padding=10
)
# Draw boxes
annotated_frame = box_annotator.annotate(
scene=image.copy(),
detections=detections
)
# Draw labels
annotated_frame = label_annotator.annotate(
scene=annotated_frame,
detections=detections,
labels=labels
)
# Display result
sv.plot_image(
image=annotated_frame,
size=(16, 16)
) The image below shows the output produced by the script above on a test image:

Step 4: Run inference on Webcam stream
Similarly to the example above, where we performed inference on a single image, you can treat a webcam video stream as a sequence of frames and run inference on each frame using the same approach shown in the script below.
import cv2
from inference_sdk import InferenceHTTPClient
import supervision as sv
# Initialize client
client = InferenceHTTPClient(
api_url="http://localhost:9001",
api_key="YOUR_ROBOFLOW_API_KEY"
)
MODEL_ID = "rock-paper-scissors-sxsw/11"
# Open webcam
cap = cv2.VideoCapture(0)
# Annotators
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
while True:
ret, frame = cap.read()
if not ret:
break
# Run inference
result = client.infer(frame, model_id=MODEL_ID)
# Convert to Supervision detections
detections = sv.Detections.from_inference(result)
# Class labels only
labels = [pred["class"] for pred in result["predictions"]]
# Draw bounding boxes
annotated_frame = box_annotator.annotate(
scene=frame,
detections=detections
)
# Draw class labels
annotated_frame = label_annotator.annotate(
scene=annotated_frame,
detections=detections,
labels=labels
)
# Show result
cv2.imshow("Inference SDK Stream", annotated_frame)
# Press Q to quit
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows() Bonus: Running Offline Inference Using a Deployed Roboflow Workflow
Roboflow Workflows is a visual, low-code, drag-and-drop web tool that enables you to build end-to-end computer vision systems by connecting modular blocks such as computer vision models, image processing steps, and logic rules.
It provides access to a wide range of models, including RF-DETR, YOLO26, Qwen3-VL, and Florence 2, all available as ready-to-use components. These can be combined within a workflow to build complete applications without managing separate model deployments.
These workflows can be deployed locally, and once deployed, they can run in offline mode, making the entire computer vision workflow, including the model, available for inference without an internet connection.
To create a Roboflow workflow, you can use the Roboflow Agent available in your workspace after logging in. It allows you to generate workflows for a wide range of computer vision tasks using simple natural language prompts.For example, you can use a prompt like:
“Create me an Instance Segmentation Workflow using RF-DETR that detects and masks people.”
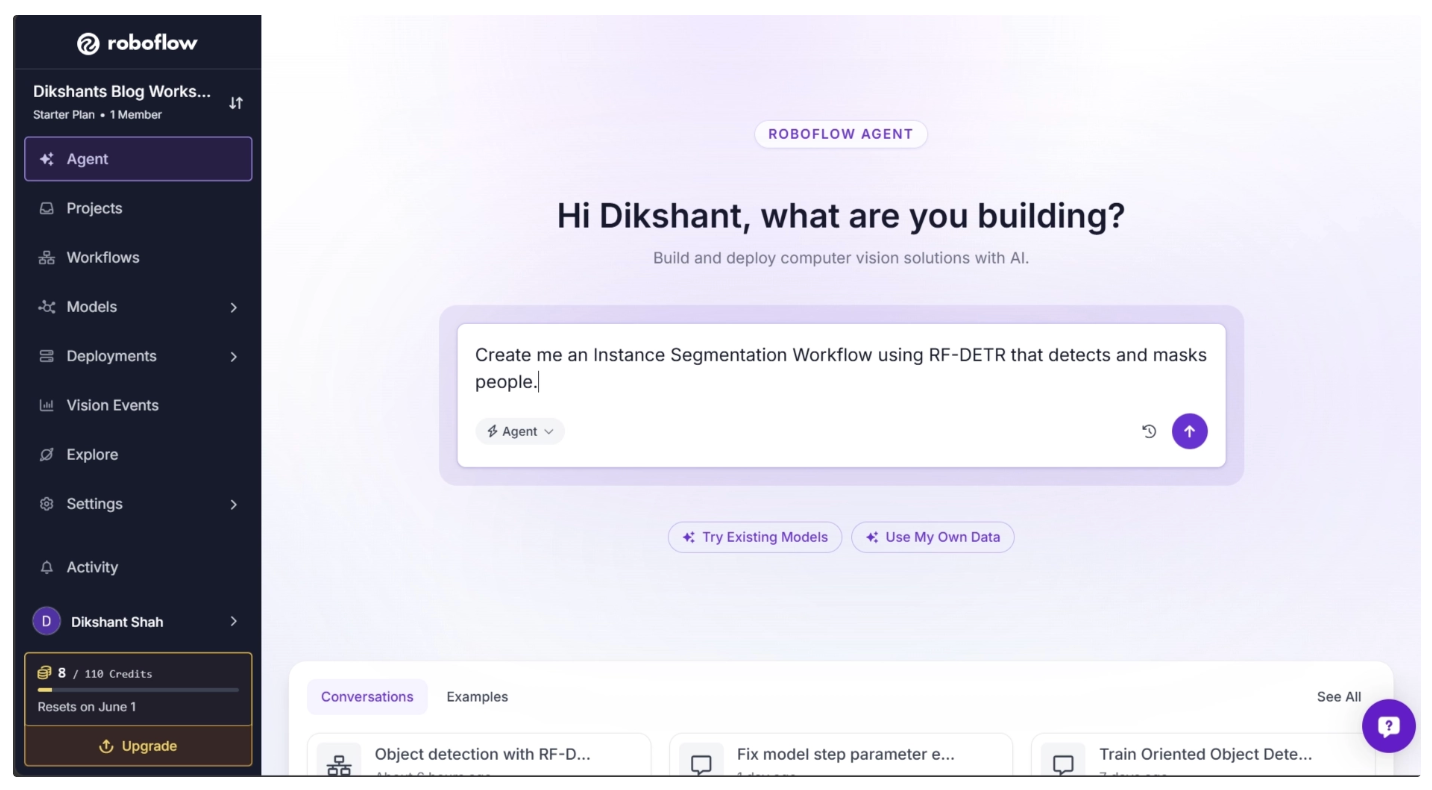
Roboflow Agent works as a conversational layer on top of Roboflow tools. You can describe your requirements in plain English, and it automatically builds the corresponding workflow for you.
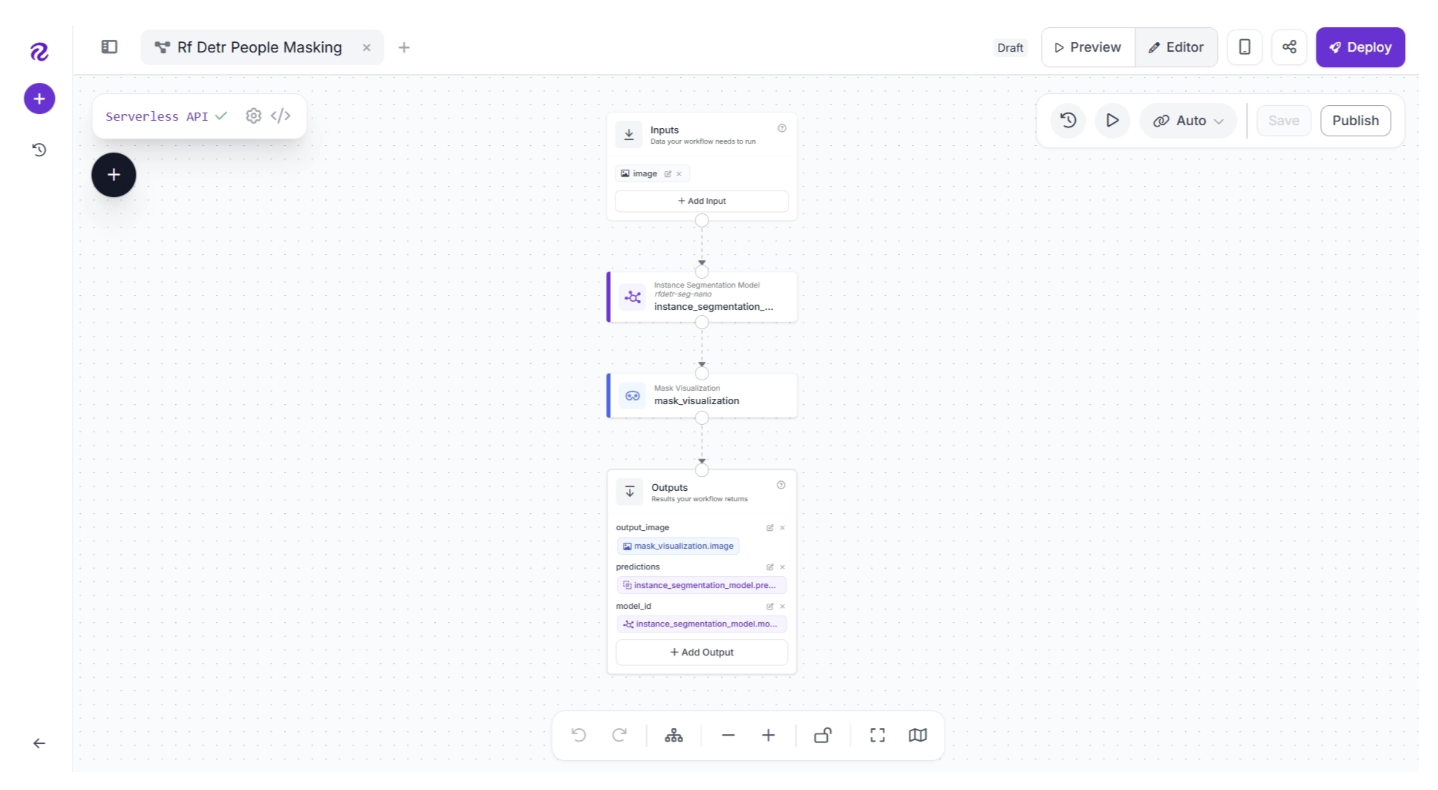
It provides a strong starting point while still allowing full customization, so you can adjust and refine workflows to match your specific use case.It generated the complete workflow as shown below. Based on the output produced by the agent on a test image, you can further customize the workflow using additional prompts or by clicking the blocks and configuring the parameters of individual blocks.
You can test the workflow directly within the Workflow UI by clicking the “Preview” button in the top-right corner. This opens a testing interface where you can drag and drop images or videos into the workflow to inspect the results, as shown below.
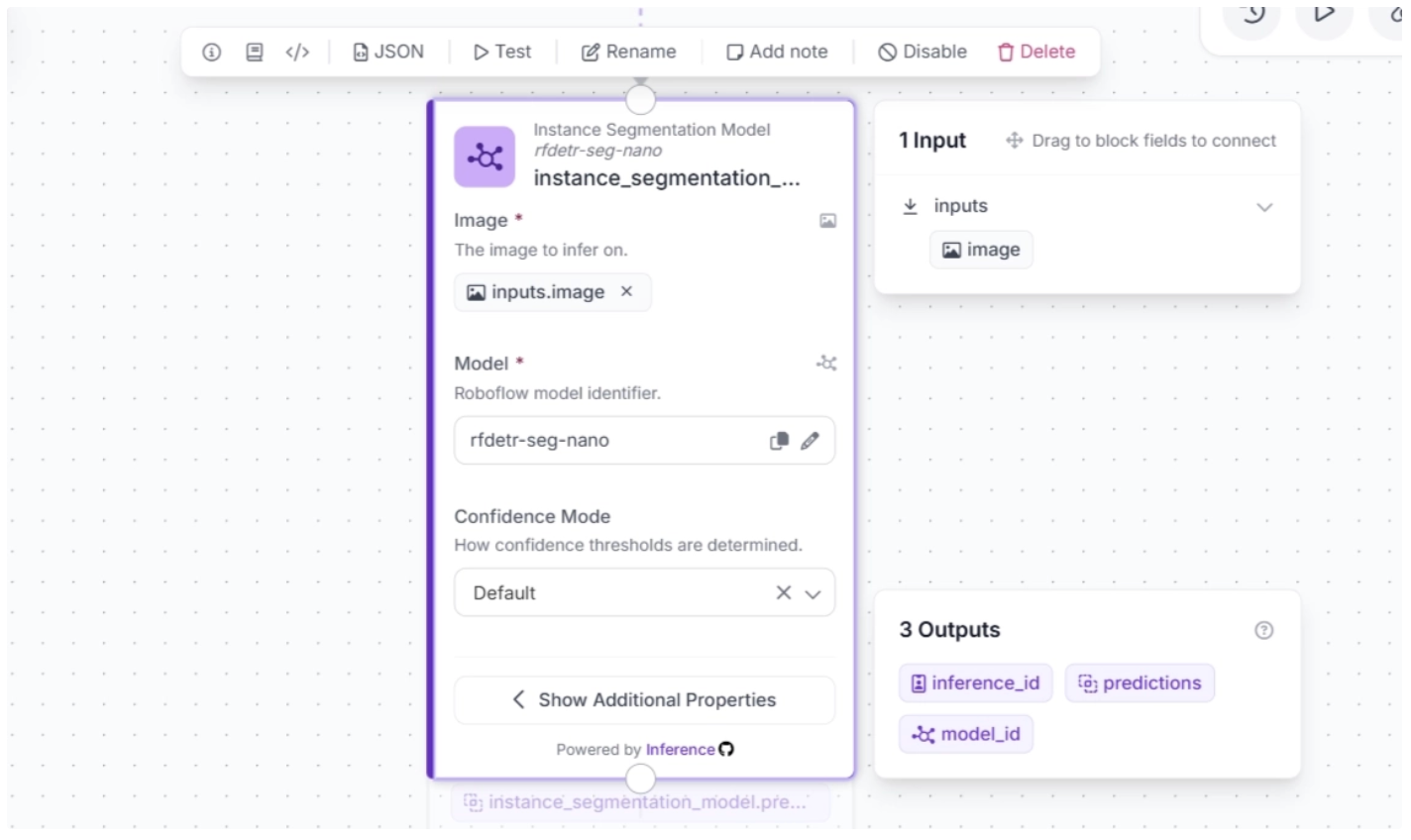
Individual models can be configured by clicking a model block within the workflow. This opens the block's configuration panel, where model settings and parameters can be adjusted, as shown below.
The selected model can also be replaced with a different one, making it easy to experiment with and compare alternative models within the same workflow.
You can then deploy the workflow to run locally. The deployment script for running the workflow locally is available in the workflow UI by clicking the “Deploy” button, as shown below.
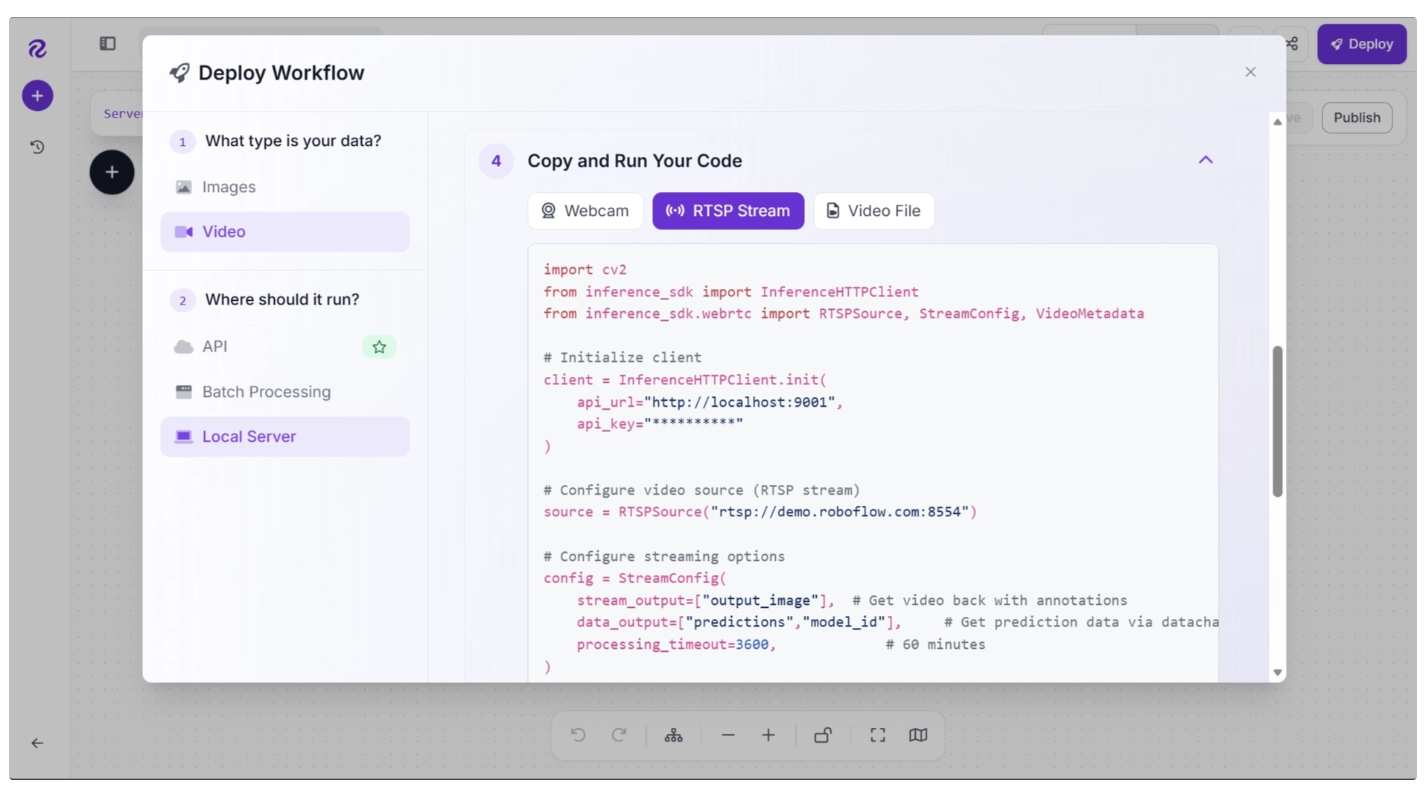
Essentially, you build the workflow using its various available model blocks online. Once it is built, you can deploy it locally and cache it for future offline use. However, offline workflow deployment is an Enterprise feature and requires an Enterprise Plan from Roboflow.
The video below demonstrates the output of the above workflow powered by the RF-DETR segmentation model running on an RTSP stream, with the entire workflow and model executed locally.
Conclusion: Deploy Computer Vision Models Offline
Running computer vision models offline is becoming increasingly important as applications move closer to edge environments where speed, reliability, and data privacy are critical. Local deployment removes cloud dependency and gives full control over inference on devices such as laptops, industrial machines, or NVIDIA Jetson.
In this guide, we explored two approaches using Roboflow Inference: The first uses the native Python inference library, where models run directly in your Python process. This is best for lightweight setups, edge devices, and low-overhead use cases.
The second uses the Inference Server with the CLI and SDK, offering a scalable setup for production, distributed systems, and air-gapped environments where multiple clients connect to a local service.
Together, these approaches form a flexible system for building offline computer vision solutions, from simple experiments to production deployments.
Cite this Post
Use the following entry to cite this post in your research:
Dikshant Shah. (Jun 1, 2026). How to Deploy Computer Vision Models Offline. Roboflow Blog: https://blog.roboflow.com/deploy-computer-vision-models-offline/