
Amazon Rekognition, a suite of computer vision APIs by Amazon Web Services, has a wide range of visual analysis solutions, such as facial recognition, content moderation, occupancy detection, OCR and logo detection. Underlying several of these solutions, Amazon Rekognition Image has a general object detection API, which detects 289 possible classes of objects from people to wedding gowns.
In this guide, we will show how to evaluate the effectiveness of a custom use-case-specific model to the generic model by Amazon Rekognition. You can use these steps to evaluate how your model compares to the AWS endpoint.
AWS Rekognition Test
Step 1: Finding an evaluation dataset
For this example, we will say that we want to detect cars and we want a model that will perform well at detecting vehicles in all sorts of scenarios. To find a good dataset, we can search Roboflow Universe for a trained object detection model.
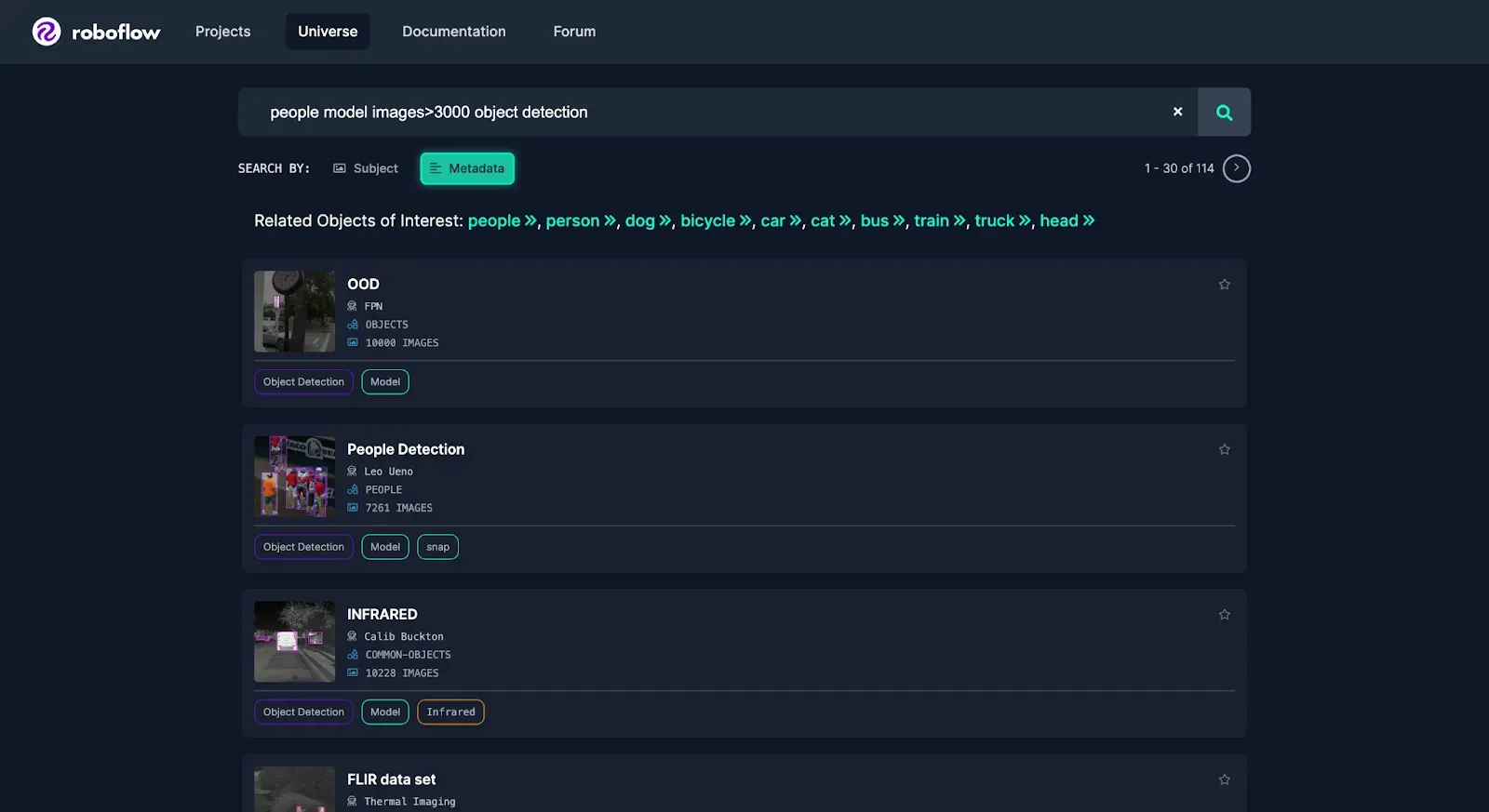
In this case, to evaluate how the models will perform in a variety of settings we will use a large, generalized, diverse dataset like COCO. For this example, we’ll use a Universe dataset of a subset of COCO limited to vehicles.
Optional: Create your own model or evaluation dataset
If you have your own use case that you would like to compare against Amazon Rekognition, you can create your own dataset and train a model, then compare that custom-trained model against how Amazon Rekognition performs.
For example, you could capture around a hundred images or videos from where you’d like to deploy your model and then upload the images to Roboflow.
You could quickly annotate them or even have Autodistill label the images for you.
Once you have your images annotated, you can add and modify preprocessing and augmentations, then generate a version.

After creating a version, you can train your model with one click.
Then, continue through this guide the same way, but replace the model with your own to download your project.
Step 2: Evaluate model performance
Now that we have the dataset to evaluate both models against, we can begin the evaluation process. We can test the models and produce the mAP (mean average precision) for both models using supervision’s mAP benchmark feature.
First, we’ll install the `roboflow` and `supervision` packages, as well as `boto3` and `aws-shell`, which are AWS tools, required to use Rekognition on Python.
!pip install boto3 aws-shell roboflow supervision -qAmazon’s Rekognition model can be accessed by signing up for an AWS account if you don’t already have one. Then, create an IAM access key to use the API.
In the notebook, start the authentication process by using the CLI command `aws configure` and follow the prompts that appear.
Download the Evaluation Dataset
Now, we’ll download our evaluation dataset and use the `DetectionDataset.from_coco()` method to get it into supervision.
from roboflow import Roboflow
rf = Roboflow(api_key="**YOUR API KEY HERE**")
project = rf.workspace("vehicle-mscoco").project("vehicles-coco")
dataset = project.version(2).download("coco")To do this on your own or with your own dataset, click on the Download this Dataset button on any object detection dataset on Universe and export in COCO format.
Testing the Rekognition Model
Before we can test, we will have to set up our class maps. The Rekognition object detection model has 289 classes, many of which can be overlapping. For our purposes, we found three classes in the list of classes that were relevant to vehicle detection: `Vehicle` and `Car`. In our limited testing, we found that these encompass most of the model’s most accurate detections, but there could be some instances where the class `Fire Truck` is detected, but `Car` or `Vehicle` isn’t. We saw behavior similar to this when we tested with people detection, as we will cover later.
Then, we set up a callback function so that supervision can run the model against the images in our evaluation dataset.
Once we have this setup, we can start to evaluate the performance of Rekognition by using the mAP benchmark function, getting a result of 59.05%.
mean_average_precision = sv.MeanAveragePrecision.benchmark(
dataset = sv_dataset,
callback = callback
)
print(f"Final mAP: {mean_average_precision.map50}")
Testing the Roboflow Universe Model
Now that we have the results from the Rekognition model, we can run the same evaluation with our specialized model from Roboflow Universe.
Entering the Roboflow API key, we can load in the model from Universe. Similar to the process with Rekognition, we can also set up a callback function for testing with Supervision.
def callback(np_image):
image = cv2.cvtColor(np_image, cv2.COLOR_RGB2BGR)
result = model.predict(image, confidence=45, overlap=50).json()
sv_result = sv.Detections.from_inference(result)
return sv_resultConducting the evaluation, we get a result of 65.92%, an improvement of 6.87% from the Rekognition model.

Person Detection Comparison
Getting results of 65.92% with Universe and 59.05% in Rekognition, we sought to test other popular use cases of computer vision. Having previously compared Google Cloud Vision’s generic object detection API using a person detection use-case, we decided to conduct an evaluation of Amazon Rekognition against the previous results.
Initially, we received results from Rekognition that were as low as 29%. In our limited experience, we found that Rekognition occasionally struggled with returning bounding box locations of some classes, while not others. To evaluate Rekognition against the other offerings as fairly as possible, we added the classes `Person`, `Man`, `Male` and `Female` to the class map, getting an improved result of 44.67%.

AWS Rekognition Test Conclusion
The results of the testing suggest that a specialized trained model for a specific use-case can perform better. If detecting a single object reliably is of importance, a specialized model may be worth testing. With that said, we also recognize the benefit of models like AWS Rekognition and Google Cloud Vision in that they have the ability to detect an extremely large number of objects. It is important to consider the specific reason and environment for a computer vision and choose the best solution for your use case accordingly.
Cite this Post
Use the following entry to cite this post in your research:
Leo Ueno. (Jan 12, 2024). Comparing Specialized Models to AWS Rekognition Test. Roboflow Blog: https://blog.roboflow.com/universe-aws-rekognition/