
Google Cloud Vision is a set of APIs made by Google for a variety of vision-based tasks designed to be easily integrated to enable visual intelligence for apps. They offer object detection of generic objects, optical character recognition (OCR), document detection/recognition, and the ability to train custom detection models.
In this guide, we will go over how you can evaluate how well Google’s Cloud Vision generic object detection API (also referred by Google as object localization) performs against other available models and APIs. This is helpful to make sure you are choosing the best model for your use case. We will use a custom-trained model in Roboflow Universe in detecting people for our example comparison.
Step 1: Finding an evaluation dataset
For this example, we will say that we want to detect people and we want a model that will perform well at detecting people in all sorts of scenarios. To find a good dataset, we can search Roboflow Universe for a trained object detection model.
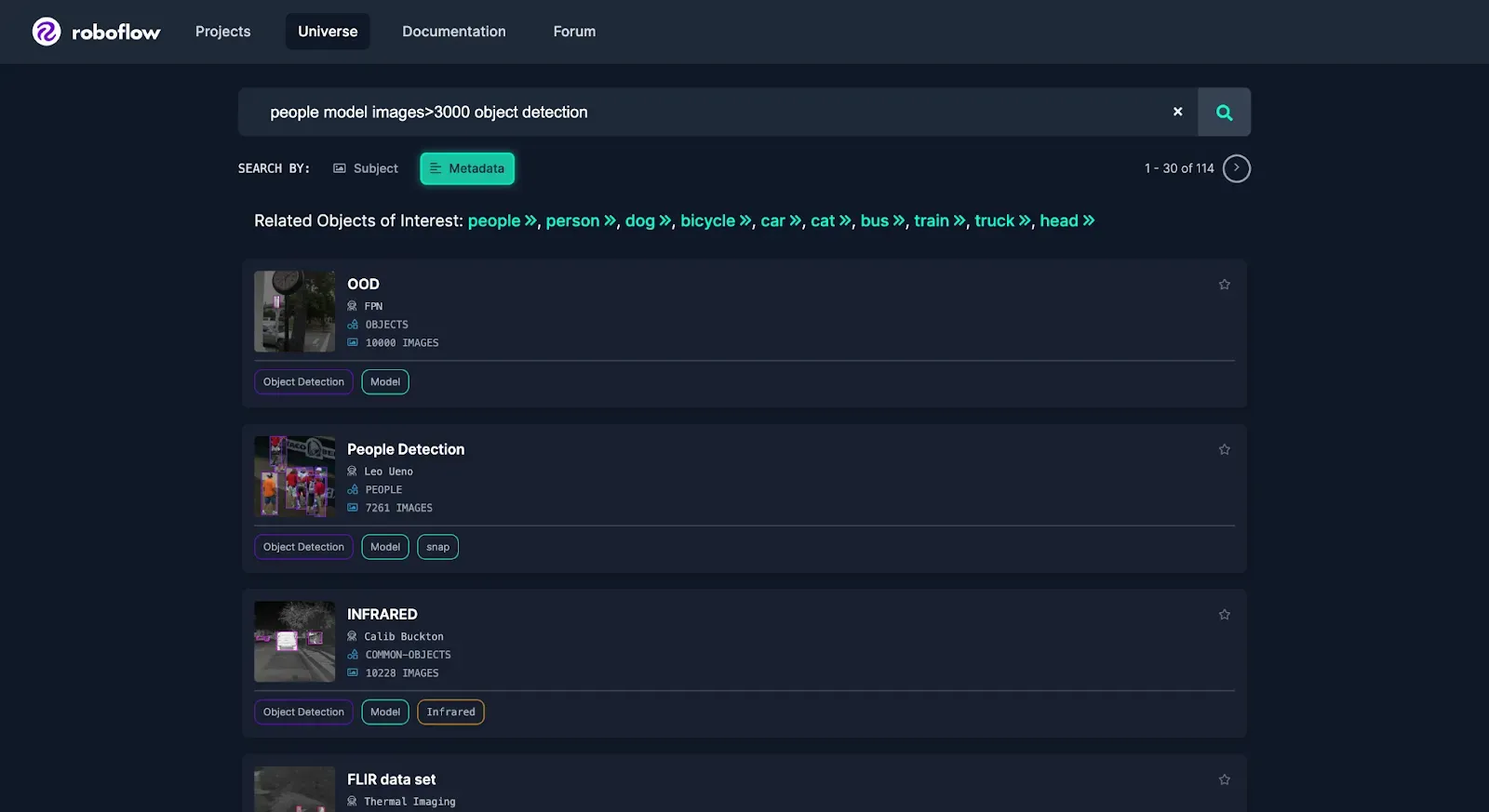
In this case, to evaluate how the models will perform in a variety of settings we will use a large, generalized, diverse dataset like COCO. For this example, we’ll use a Universe dataset of a subset of COCO limited to people.
Optional: Create your own model or evaluation dataset
If you have your own use case that you would like to compare against Google Cloud Vision, you can create your own dataset and train a model, then compare that custom-trained model against how Google Cloud Vision performs.
For example, you could capture around a hundred images or videos from where you’d like to deploy your model and then upload the images to Roboflow.
You could quickly annotate them or even have Autodistill label the images for you.
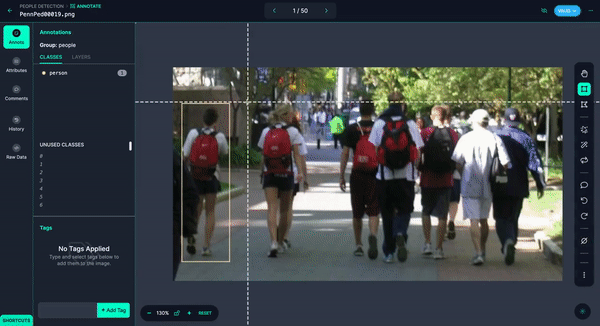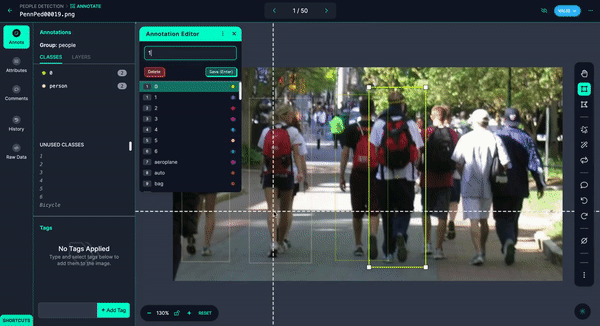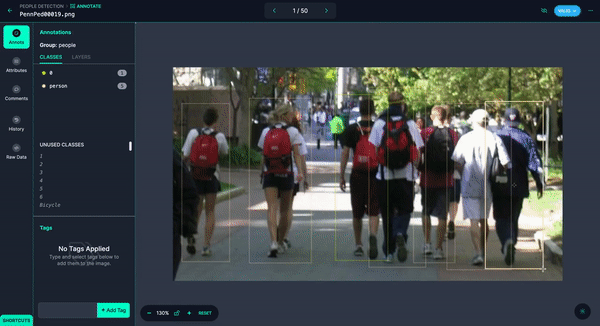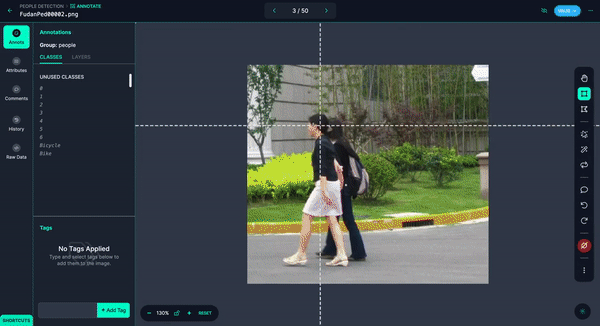
Once you have your images annotated, you can add and modify preprocessing and augmentations, then generate a version.

After creating a version, you can train your model with one click.
Then, continue through this guide the same way, but replace the model with your own to download your project.
Step 2: Evaluate model performance
Once we have our models and an evaluation dataset, we can test the models and produce the mAP for both models using supervision’s mAP benchmark feature.
First, we’ll import the `roboflow` and `supervision` packages.
!pip install supervision roboflow
Download the Evaluation Dataset
Now, we’ll download our evaluation dataset and use the `DetectionDataset.from_coco()` method to get it into supervision.
from roboflow import Roboflow
rf = Roboflow(api_key="**YOUR API KEY HERE**")
project = rf.workspace("shreks-swamp").project("coco-dataset-limited--person-only")
dataset = project.version(1).download("coco")To do this on your own or with your own dataset, click on the Download this Dataset button on any object detection dataset on Universe and export in COCO format.
Testing the Cloud Vision Model
First, we will need to get set up authenticating with Google. If you haven’t used Google Cloud’s APIs before, follow this guide from Google to create a service account JSON file for the Google Cloud Vision API, then continue with this guide.
Set up the service account JSON you got with this code:
from google.oauth2.service_account import Credentials
credentials = Credentials.from_service_account_file(
filename="tester-1490046330330-d33ad7bf6f84.json" # Replace with the file name of your service account file
)Then, we set up a callback function so that supervision can run the model against the images in our evaluation dataset.
def callback(np_image):
img = Image.fromarray(np_image)
buffer = io.BytesIO()
img.save(buffer, format='PNG') # You can change the format as needed, e.g., JPEG
buffer.seek(0)
image_bytes = buffer.read()
image = vision.Image(content=image_bytes)
objects = client.object_localization(image=image).localized_object_annotations
sv_result = sv.Detections.from_gcp_vision(gcp_results=objects, size=(img.height,img.width))
image = cv2.cvtColor(np_image, cv2.COLOR_RGB2BGR)
bounding_box_annotator = sv.BoundingBoxAnnotator(color=sv.Color.from_hex("#FF0000"))
annotated_frame = bounding_box_annotator.annotate(
scene=image,
detections=sv_result
)
sv.plot_image(image=image, size=(3, 3))
return sv_resultNow we calculate the model’s mAP for our dataset by passing it to supervision’s mAP benchmark function.
mean_average_precision = sv.MeanAveragePrecision.benchmark(
dataset = sv_dataset,
callback = callback
)Then, we ran the Cloud Vision API against the evaluation dataset and got a result of 64.7%.

Testing the Roboflow Universe Model
Next, we’ll compare the other model. We can evaluate that model by completing the same process we just did, but by modifying the callback and filling in our model info.
We will load our first model using our API key and project ID of the model.
api_key = "YOUR API KEY HERE"
project_id = "people-detection-o4rdr"
rf = Roboflow(api_key)
project = rf.workspace().project(project_id)
model = project.version(1).modelThen, we set up a callback function again.
def callback(np_image):
image = cv2.cvtColor(np_image, cv2.COLOR_RGB2BGR)
result = model.predict(image, confidence=45, overlap=50).json()
sv_result = sv.Detections.from_inference(result)
bounding_box_annotator = sv.BoundingBoxAnnotator(color=sv.Color.from_hex("#FF0000"))
annotated_frame = bounding_box_annotator.annotate(
scene=image,
detections=sv_result
)
sv.plot_image(image=image, size=(3, 3))
return sv_resultThen, we calculate the mAP again using supervision’s mAP benchmark.
mean_average_precision = sv.MeanAveragePrecision.benchmark(
dataset = sv_dataset,
callback = callback
)Then, we run our evaluation again on the Roboflow model.
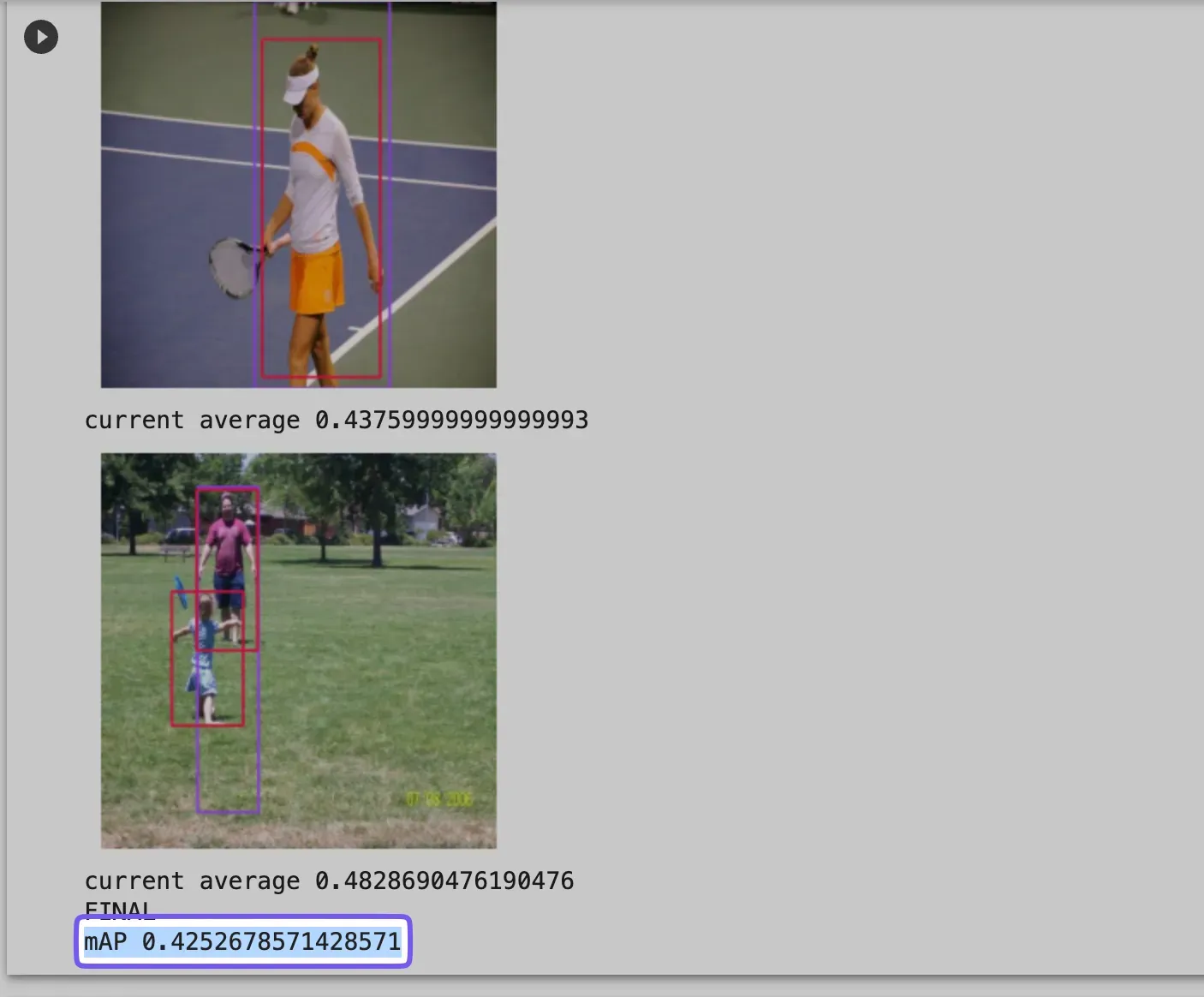
Results
The results from COCO (the dataset we just used to evaluate our models), and the improved performance of GCP Vision’s API compared to the Universe model, exceeded our expectations, especially when considering our limited manual testing of the API.
So, we conducted three more experiments to determine three things:
- Does this performance hold up in other data/datasets?
- Is Google Cloud Vision’s object detection API powered by Microsoft COCO?
- If so, what was the actual effectiveness of Google’s model
Roboflow Person Dataset Evaluation
To determine whether Google’s model performance held up in other datasets, we evaluated it on the test dataset of the Universe person detection model we just used. We also evaluated another model, an object detection model on Universe trained on COCO, an upload of a notebook-trained YOLOv8n model.

Although these results are far from definitive that Google Cloud Vision runs on a Microsoft COCO model, the uncanny similarity in performance suggests that they may use similar datasets or that Google may have trained their model from a COCO checkpoint.
This may explain the improved performance of GCP Vision’s model in our prior test. Models very often predict with a higher accuracy on images that have been or are similar to those “seen before”/trained on. This is why mAP does not always provide the entire picture.
Alternative Evaluation Dataset
To fairly evaluate all three models, we will evaluate these models a third and final time on a dataset that all models have likely not seen before. We used another person detection dataset from Roboflow Universe. These were the results of running the prior tests again on this new dataset:

Conclusion
Having the ability to properly evaluate different models across different platforms can be an effective tool in deciding which model best suits any particular use case. While the final evaluation dataset did result in higher performance from one model on Universe, it doesn’t necessarily equate to good performance in your use case. We encourage you to collect your real-world data to not only evaluate how models perform on your data, but to also be able to train your own model.
Cite this Post
Use the following entry to cite this post in your research:
Leo Ueno. (Dec 6, 2023). Comparing Custom Models to Google Cloud Vision API. Roboflow Blog: https://blog.roboflow.com/custom-models-versus-google-cloud-vision/